Im Beitrag wird die Frage beleuchtet, inwieweit auf der Basis von Windkraft eine verlässliche Versorgung mit Strom hergestellt werden kann. Wir konzentrieren uns dabei auf das grundsätzliche Potential in der Erzeugung von Windstrom und blenden die praktisch bestehenden Limitierungen (minimale Windgeschwindigkeit unterhalb derer kein Strom produziert wird, begrenzter Erntefaktor aufgrund physikalischer Randbedingungen, Abschaltung bei zu starkem Wind, sonstige Verluste) aus.
Zunächst zusammenfassend die verwendeten Begriffe und Definitionen:
(1)
Die Verteilung der Windgeschwindigkeit
Der Wind gehorcht der Weibullverteilung mit den Parametern und . Der letztgenannte Wert heißt Formfaktor. Für die vorherrschenden Windverhältnisse in Mitteleuropa kann man den Formfaktor ansetzen. In Süddeutschland liegt der Wert etwas darunter, an der Küste etwas darüber bei bis zu .
(2)
Die Formel gibt die Wahrscheinlichkeit dafür an, dass die tatsächliche Windgeschwindigkeit zu einem willkürlich gesetzten Zeitpunkt kleiner als die definierte Geschwindigkeit ist.
In Abb. 1 sind typische Graphen für die Verteilung der Windgeschwindigkeit bei unterschiedlichen Formfaktoren dargestellt.
Abbildung 1: Verteilung der Windgeschwindigkeit bei unterschiedlichen Formfaktoren .
Bei gegebenen Parametern bestimmt sich die mittlere Windgeschwindigkeit zu
(3)
Somit kann man bei bekannter mittlerer Windgeschwindigkeit umgekehrt auch den Parameter errechnen.
(4)
Die Verteilung der Windleistung
Für ein ideales Windrad ergibt sich die resultierende Windstromleistung aus der Nennleistung und der Nenn-Windgeschwindigkeit gemäß
(5)
Demnach lässt sich aus der abgegebenen Leistung umgekehrt die Windgeschwindigkeit bestimmen.
(6)
Auf dieser Basis können wir nun die Verteilung der Leistungsabgabe folgendermaßen beschreiben:
(7)
Die produzierte Windstromleistung ist demnach Weibull-verteilt mit dem Formfaktor . Abbildung 2 zeigt Beispiele für die Verteilung der Leistungsabgabe bei Formfaktoren um .
Abbildung 2: Verteilung der Leistungsabgabe bei unterschiedlichen Formfaktoren . Man sieht, dass die Leistung überwiegend bei einem Bruchteil der Normleistung (also der Nennleistung) abgegeben wird.
Generische Darstellung der Leistungsverteilung
Der Erwartungswert der Leistung bestimmt sich zu
(8)
Für den Formfaktor erhalten wir die Vereinfachung:
(9)
Wenn gesetzt wird, dann gibt die obige Formel die Wahrscheinlichkeit des Ereignisses wieder. Bei einer Erhöhung der Windstromproduktion um den Faktor ist folglich die Wahrscheinlichkeit, dass weniger Windstrom als produziert wird. Das ist demnach das Ereignis . Eingesetzt in Formel (7) erhalten wir
(10)
Im Ergebnis ist daher die Wahrscheinlichkeit des Ereignisses unabhängig von den physikalischen Randbedingungen wie z.B. der mittleren Windgeschwindigkeit und der Nennleistung des Windrads. Allein entscheidend ist das Verhältnis zwischen der produzierten Windleistung und dem Strombedarf, also dem Produktionsfaktor .
Für den Formfaktor folgt der unmittelbar auswertbare Zusammenhang:
(11)
Analyse zum Versorgungsgrad
Der Versorgungsgrad ist das Verhältnis zwischen dem auf einen Zeitpunkt bezogenen Leistungsangebot und dem entsprechenden Leistungsbedarf. Formal also . Wenn nun, wie oben, die Windstromproduktion um den Faktor erhöht und gesetzt wird, dann ist das Ereignis identisch mit . Daher erhalten wir die von der Windgeschwindigkeit und der induzierten Windleistung formal unabhängige Darstellung des Versorgungsgrads in Termen des Produktionsfaktors .
(12)
bzw.
(13)
Bezogen auf einen vorgegebenen Versorgungsgrad statt 1 ergibt sich
(14)
bzw.
(15)
Wir haben nun einen vollständigen Überblick über die erzielbaren Versorgungsgrade in Abhängigkeit von der Windstromproduktion in Einheiten des Strombedarfs. Wir müssen also nicht konkrete Windgeschwindigkeiten oder Leistungsfaktoren betrachten und können demgemäß grundsätzliche Aussagen zur Versorgungssicherheit bzw. zum Versorgungsrisiko ohne nähere Kenntnis der Gegebenheiten am Aufstellungsort treffen. Wir müssen lediglich die Verteilung der Windgeschwindigkeiten kennen, genauer, den Formfaktor der entsprechenden Weibullverteilung.
Versorgungssicherheit und Versorgungsrisiko
Die resultierenden graphischen Verläufe für die Versorgungssicherheit und das Versorgungsrisiko bei unterschiedlichen Formfaktoren sind in den Abbildungen 3 und 4 dargestellt.
Abbildung 3: Versorgungsrisiko bei unterschiedlichen Formfaktoren .
Abbildung 4: Versorgungssicherheit bei unterschiedlichen Formfaktoren .
Die tatsächliche Windverteilung in Deutschland gehorcht näherungsweise der Weibullverteilung mit dem Formfaktor . Für die grundsätzlichen Aussagen reicht es daher aus, diesen Formfaktor zu betrachten.
Nach Formel (13) bestimmt sich das Versorgungsrisiko zu
(16)
und entsprechend die Versorgungssicherheit
(17)
Abbildung 5: Versorgungsrisiko bei einem Formfaktor von .
Abbildung 6: Versorgungssicherheit bei einem Formfaktor von .
Die Graphen in Abb. 5 und Abb. 6 zeigen das theoretische Versorgungsrisiko und entsprechend die Versorgungssicherheit aus der Produktion von Windstrom unter idealen Bedingungen (verlustfrei, 100-prozentige Verfügbarkeit, keine Abschaltung) als Wahrscheinlichkeitsverteilung. Auf der x-Achse ist der Umfang der Windstromproduktion in Vielfachen des Strombedarfs (Produktionsfaktor q) aufgetragen. Die y-Achse in Abb. 5 zeigt das theoretische Versorgungsrisiko und die y-Achse in Abb. 6 die resultierende Versorgungssicherheit als Funktion des Produktionsfaktors q.
Aufgrund der Herleitung erkennen wir, dass die theoretische Versorgungssicherheit und entsprechend auch das Versorgungsrisiko unmittelbar aus dem Verhältnis zwischen der Gesamtproduktion an Windstrom und dem jeweiligen Bedarf, also dem Produktionsfaktor q abgeleitet werden kann.
Einige Zahlenbeispiele: Wenn der Produktionsfaktor ist (also genauso viel Strom produziert wird, wie im Mittel benötigt wird), dann liegt die Versorgungssicherheit bei 0,3 (= 30 %) und das Versorgungsrisiko bei 0,7 (= 70 %). Vielfach wird diese Situation bereits als „Autarkie“ bezeichnet, obwohl es eigentlich nur „bilanzielle Autarkie“ ist und man tatsächlich in den überwiegenden Zeitabschnitten eines Jahres auf externe Stromlieferungen angewiesen ist.
Sofern der Produktionsfaktor nur bei liegt, dann erhalten wir eine Versorgungssicherheit von 0,15 (= 15 %) und ein Versorgungsrisiko von 0,85 (= 85 %). Wenn im Jahresverlauf summarisch doppelt so viel Strom als benötigt produziert (Produktionsfaktor ), so ergibt sich eine theoretische Versorgungssicherheit von 0,47 (= 47 %) und ein Versorgungsrisiko von 0,53 (= 53 %) .
Man entnimmt den Graphen, dass die theoretische Versorgungssicherheit mit wachsendem Produktionsfaktor zunächst schnell steigt und das Versorgungsrisiko entsprechend sinkt. Allerdings ist der Aufwand für eine deutliche Reduzierung des Versorgungsrisikos am Ende doch sehr hoch: Selbst bei einem Produktionsfaktor von liegt das Versorgungsrisiko immer noch bei 0,23 (= 23 %), also Versorgungssicherheit 0,77 (= 77 %). Und sogar bei , wenn also der in der Jahressumme benötigte Windstrom den Bedarf um den Faktor 100 übersteigt – was ja in der Praxis überhaupt nicht finanzierbar ist – bleibt das Versorgungsrisiko bei 0,055 (= 5,5 %). Wir erhalten also lediglich eine Versorgungssicherheit 0,955 (= 95,5 %). Trotz des utopisch hohen Aufwandes wäre zeitanteilig an 16 Tagen eines Jahres die Stromversorgung nicht gewährleistet.
Investitionseffizienz
Es ist unmittelbar einleuchtend, dass sich die Investitionskosten proportional mit dem Produktionsfaktor erhöhen oder erniedrigen. Das Verhältnis zwischen der erreichten Versorgungssicherheit und dem Produktionsfaktor ist daher ein Maß für die Investitionseffizienz.
Nun kann man fragen, bei welchem Produktionsfaktor und welcher Versorgungssicherheit der Quotient aus beiden Werten sein Maximum annimmt und damit zur größtmöglichen Investitionseffizienz führt?
In Abbildung 7 sind die Verläufe des Quotienten Versorgungssicherheit / Produktionsfaktor für die Formfaktoren dargestellt.
Abbildung 7: Quotient Versorgungssicherheit / Produktionsfaktor für die Formfaktoren . Beispiel: Für den Formfaktor erhalten wir bei einen Quotienten von und somit eine Versorgungssicherheit von . Wenn nun der Produktionsfaktor auf erhöht wird, ist der Quotient und die Versorgungssicherheit , d.h., die Versorgungssicherheit steigt überproportional mit dem Produktionsfaktor.
Der Quotient Versorgungssicherheit / Produktionsfaktor erreicht an einem bestimmten Wert für den Produktionsfaktor sein Maximum. Diesen Wert bestimmt man zu
Aus dem Vorstehenden entnimmt man, dass die Investitionseffizienz zunächst einmal ansteigt und dann nach Erreichen eines Maximums – in Abhängigkeit vom Formfaktor – wieder abfällt. Für werden die jeweiligen Maxima mit Effizienzwerten von bei Produktionsfaktoren erreicht. Bei größeren Produktionsfaktoren ist die Investitionseffizienz in jedem Falle geringer.
Man erhält daher bei Erhöhung des Produktionsfaktors in der Relation einen immer geringeren Zuwachs an Versorgungssicherheit. Bei sind das z.B. die Produktionsfaktoren (s. Abb. 7, rechts des Maximums der blauen Kurve). Bei ausschließlicher Betrachtung der Windstromproduktion und ohne die Berücksichtigung von (teuren) Speichern ist daher der Ausbau der Windkraft wesentlich über die Grenze hinaus zumindest ineffizient.
Realitätsbezug
Natürlich wird man in der Praxis nicht ausschließlich auf die Stromversorgung mit Windkraft bauen und daneben auch andere Erneuerbare wie z.B. Solarstrom oder Biomasse miteinbeziehen. Ist dann die obige Überlegung obsolet und die Versorgungssicherheit in Summe doch zu gewährleisten? Leider nein! Es bleibt die grundsätzliche Problematik der Wetterabhängigkeit. Wenn wir z.B. annehmen, dass 50 % des Bedarfs aus sicheren Quellen kommen (was dann allerdings Photovoltaik ausschließen würde) und damit nur die restlichen 50 % über die Windkraft erzeugt werden müssen, dann laufen wir am Ende auf dieselbe Problematik zu, nur eben mit einem graduell etwas reduziertem Risiko. Statt eines Versorgungsrisikos von 60 % hätte man dann z.B. „nur“ ein Risiko von 30 %. Die erforderliche Versorgungssicherheit von 99,9 % und höher ist auf diesem Wege – also ohne Importe, Speicher oder Backup-Kraftwerke – nicht erreichbar.
Das hochkomplexe Verhalten von Tieren in großen Gruppen versetzt den aufmerksamen Beobachter immer wieder in Erstaunen. Im Spätsommer gewahrt der Blick in den Himmel Schwärme von Zugvögeln, die, scheinbar wie auf ein Kommando, in rascher Folge die Richtung wechseln und dabei auch schwierige Flugmanöver ganz ohne Kollisionen meistern. Gelegentlich lässt sich ein Schwarm, als hätten alle Vögel gemeinsam genau dieses Ziel lange schon untereinander „abgestimmt“, zum Zwischenstopp auf einer elektrischen Überlandleitung nieder, nur um nach einer geschwätzigen Ruhepause alle zugleich munter zum Flug anzuheben und ebenso gewandt wie verlässlich die ursprüngliche Schwarmformation wieder einzunehmen.
Auf äußere Einflüsse, z.B. die Anwesenheit von Fressfeinden, reagiert die Formation als Ganzes, scheinbar als koordinierte Einheit. Gerade so, als gäbe es einen Plan des Schwarms, wie mit derlei Störungen umzugehen sei. Aus Sicht des Beobachters gehen die Individuen im Schwarm auf und verleihen ihm so quasi wesenhafte Existenz.
„Intelligente“ Fischschwärme
Noch eindrucksvoller, ist das Verhalten von Fischschwärmen: Blitzartige Bewegungen von tausenden Fischen auf engstem Raum lassen den Eindruck entstehen, es handele sich um ein einziges riesiges Individuum. Beim Angriff von Räubern zeigen Fischschwärme vielfach sehr komplexes Verhalten. Manche Arten teilen den Schwarm und bieten dem Angreifer so zwei divergierende Ziele, zwischen denen er sich entscheiden muss. Andere strömen plötzlich mit hoher Geschwindigkeit auseinander und lassen den Schwarm quasi explodieren: Der Angreifer stößt ins Leere. Nochmals andere vollziehen augenblicklich rasche Ausweichmanöver und bringen sich, zur Desorientierung des Angreifers, hinter denselben.
Fischschwarm
So verschieden die Strategien auch sein mögen, allen Arten gemein ist ein dem Wohle der Gesamtheit der Individuen (des Schwarms) höchst zweckdienliches Verhalten. Der einzelne Schwarmfisch verhält sich offenbar so, dass nicht nur er selbst, sondern dass die Gemeinschaft aller Individuen möglichst wenig gefährdet wird.
Schwarmverhalten bei Säugetieren
Auch manche Säugetierarten zeigen Schwarmverhalten: Wölfe organisieren sich in Rudeln und steigern so ihre Erfolgschancen bei der Jagd. Ein gleiches beobachtet man bei Löwen, die ebenfalls in der Gruppe jagen. Ihre potenziellen Opfer wiederum, z.B. Antilopen oder Gazellen, leben zusammen in Herden und zeigen beim Angriff ihrer Feinde ein abgestimmtes Fluchtverhalten, das dem Löwenrudel die Trennung eines einzelnen Tiers von der Herde erschwert und damit die Überlebenswahrscheinlichkeit der Individuen erhöht.
Schwarmintelligenz bei Bienen
Die bemerkenswertesten Beispiele von Schwarmintelligenz finden sich bei einer Reihe von Insektenarten, z.B. bei Ameisen oder Bienen. Das vielgestaltige Sozialverhalten von Bienenvölkern mit einigen zehntausend Individuen ist ein Musterbeispiel für Schwarmintelligenz. Die Nahrungssuche, die Brutpflege, die Verteidigung des Bienenstocks werden zum Wohle des ganzen Volkes arbeitsteilig organisiert. Es verwundert, dass dies alles ganz ohne eine koordinierende Instanz möglich ist.
Mittels ausgefeilter Bewegungsmuster tauschen die Bienen untereinander Informationen aus: So dient der bekannte Schwänzeltanz zum Anzeigen von neuen Futterquellen. Andere Ausdrucksmöglichkeiten erlauben ihnen die Verständigung hinsichtlich der Erledigung einer Reihe von weiteren für den Stock wichtigen Aufgaben.
Die einzelne Biene kann man kaum als intelligent bezeichnen. Und doch entsteht durch das einigen wenigen einfachen Regeln gehorchende geordnete Zusammenwirken ein komplexes Gesamtgebilde hoher Effektivität. In dieser Hinsicht unübertroffen erscheinen Ameisenstaaten mit bis zu mehreren Millionen Individuen. Sie faszinieren in ihren perfekt durchorganisierten, hochkomplexen Abläufen.
Der Ameisenstaat als Ausdruck von Schwarmintelligenz
Im Ameisenstaat erledigen Gruppen von Individuen unterschiedliche Aufgaben: Die Nahrungssuche, der Transport von Nahrung oder Baumaterial, die Wegesicherung, der Nestbau oder die Brutpflege, und vieles andere mehr. Dabei ist jeweils eine gewisse Anzahl von Arbeiterinnen auf bestimmte Tätigkeiten spezialisiert. Ändern sich die Umgebungsbedingungen, dann passt sich der Staat darauf sehr schnell und zielgerichtet darauf an. Werden aufgrund von zerstörenden äußeren Einwirkungen z.B. mehr Individuen für die Nestpflege (den „Wiederaufbau“) benötigt, so stellt ein gewisser Anteil von Ameisen die bisherige Tätigkeit ein und widmet sich den vorrangig wichtigen Reparaturarbeiten am Bau. Auch dies ohne Zutun einer Managementinstanz.
So wie in diesem Bild funktioniert die Arbeitsteilung im Ameisenstaat eben gerade nicht. Insbesondere ist die Managementfunktion (auf dem transportierten Ast) aufgrund der Wirkmechanismen (s.u.) entbehrlich.
Was ist Schwarmintelligenz?
Zusammenfassend betrachtet ist genau dies das hervorstechende Merkmal des Phänomens Schwarmintelligenz: Die Dinge geschehen ohne zentrale Koordination und dennoch zielgerichtet und wirkungsvoll. Das führt uns unmittelbar zur Frage, auf Basis welch anderer Mechanismen die durchaus vielschichtigen Aufgaben mit solch hoher Effizienz bewältigt werden können?
Wie entsteht Schwarmintelligenz?
Schwarmindividuen, wie wir sie in der Natur beobachten, sind meist recht einfach, wenig intelligent und allein nicht in der Lage, komplexe Aufgaben zu bewältigen. Trotzdem gelingt es ihnen durch das Zusammenwirken im Schwarm, auch schwierige Herausforderungen zu meistern. Wir haben oben einige Beispiele dazu gesehen. Die Regeln zum Beschreiben von komplexem Schwarmverhalten sind überraschend einfach. Am Beispiel von Fischschwärmen sei dies kurz erläutert. Nach [Reynolds] sind hier im Wesentlichen nur drei Prinzipien bestimmend:
– Einhaltung eines bestimmten Abstands zum Nachbarn (Separation)
– Bewegung in die durchschnittliche Richtung der Nachbarn (Alignment)
– Anstreben der durchschnittlichen Position der Nachbarn (Cohesion)
Die zugrundeliegenden Regelmechanismen sind nach Struktur und Abhängigkeit für die unterschiedlichen Arten höchst verschieden. Fast immer aber lässt sich zeigen, dass das Gesamtverhalten des Schwarms letztlich auf die individuelle und lediglich lokalen Einflüssen unterliegende Befolgung von wenigen Grundsätzen zurückgeführt werden kann.
Schach spielende Ameisen: Das ist eben genau keine Schwarmintelligenz.
Die Wirkung der drei Grundprinzipien am Beispiel des Ameisenstaats
Ameisen z.B. hinterlassen bei der Suche nach Nahrungsquellen Duftspuren (sogenannte Pheromone). Natürlich verflüchtigen sich diese Spuren im Laufe der Zeit. „Je öfter aber eine oder mehrere Ameisen innerhalb eines kurzen Zeitraums auf demselben Weg gehen, umso intensiver ist diese Markierung. Dies führt dazu, dass immer mehr Ameisen diesen Weg benutzen, dabei erneut Pheromone hinterlassen und weitere Nahrung in den Bau transportieren, bis die Quelle erschöpft ist. Ein kurzer Weg zu einer guten Nahrungsquelle wird also bevorzugt, da die Pheromonspur hier besonders intensiv ist.
Für einen großen Ameisenstaat ist das eine sehr effiziente Methode, die ohne Intervention und Management einer einzelnen höheren Instanz auskommt und nur auf lokalen Informationen basiert. Eine einzelne Ameise muss keinen Überblick über alle Vorgänge im Staat haben, um zu entscheiden, an welchem Ort sie nach Nahrung suchen soll. Sie trifft diese Entscheidung allein auf Grundlage der Pheromonspur und dadurch mittels Kommunikation mit anderen Ameisen.“ (zitiert nach Pintscher 2008).
Menschenmengen als Schwärme
Auch große Menschenmengen zeigen unter bestimmten Bedingungen schwarmähnliches Verhalten. Das kann man z.B. beobachten bei Strömen von Fußgängern. In Paniksituationen verhalten sich Menschen weniger als Einzelwesen, die individuell aufgrund genauer Situationsanalyse zu rationalen Entscheidungen kommen, als vielmehr wie Teile eines großen Ganzen, ähnlich eines gesamthaft agierenden Schwarms. Gegenwärtig sind viele Fragestellungen hierzu noch Gegenstand der Forschung.
Zusammenfassung der Beobachtungen
Das, was der Beobachter als komplexes Verhalten des Schwarms wahrnimmt, lässt sich in Summe verstehen als die Einhaltung von einigen grundlegenden, einfachen Prinzipien durch die Einzelwesen. Wobei eines hinzukommt: Der Schwarm als Ganzes zeigt auf der Makroebene Eigenschaften und Strukturen, die es rechtfertigen, ihn als emergentes System aufzufassen. Das aufgrund lokaler Informationen geregelte Verhalten der Gruppenmitglieder ermöglicht es so der Gesamtheit, Aufgaben zu lösen, die das Vermögen der einzelnen Individuen bei weitem übersteigen. Wir können also in aller Kürze resümieren: Schwarmintelligenz entsteht durch das komplexe und spezifischen Regeln unterliegende Zusammenwirken einer großen Anzahl von Individuen.
Gibt es Schwarmintelligenz beim Menschen?
Nach dem Obigen können wir können wir die wesentliche Erkenntnis folgendermaßen formulieren:
Schwarmintelligenz entsteht dann, wenn wenig intelligente („dumme“) Individuen auf Basis simpler Regeln im Hinblick auf ein übergreifendes, die Einsichtsfähigkeit der Schwarmindividuen übersteigendes Ziel im Sinne der Gemeinschaft („Schwarm“) geeignet zusammenwirken.
Schwarmintelligenz beim Menschen – die gibt es nicht. Oder, etwas weniger apodiktisch formuliert, die gibt es nur äußerst selten. Sehr viel häufiger aber trifft man auf deren Gegenteil, die Schwarmdummheit. Noch etwas pointierter: Der einzelne Mensch ist intelligent, die Masse ist strohdoof – und dafür gibt es viele Beispiele. Man denke z.B. an irrationale Hamsterkäufe oder an das Verhalten großer Menschenmengen bei Panik.
Das ist also der springende Punkt: Schwarmintelligenz beim Menschen gibt es deswegen nicht, weil der Mensch schon als Individuum intelligent ist.
Fraglos kann ein Team grundsätzlich mehr leisten als ein Individuum, das aber liegt vor allem am Skalierungseffekt und an der Koordination der Zusammenarbeit. Das ist keine Schwarmintelligenz, weil das entscheidende Plus an Arbeitsmenge und höherer Komplexität erst durch das Wirken einer koordinierenden Managementinstanz ermöglicht wird. Das konstruktive Zusammenwirken entsteht nicht von selbst, sondern ist das Ergebnis von Steuerung und Kontrolle.
Schwarmdummheit
Wenn intelligente Wesen konstruktiv zusammenwirken, entsteht das, was intelligente Wesen bewirken können, nicht weniger, aber auch nicht mehr. Es entsteht eine neue Qualität im Hinblick auf die Komplexität und die Menge des Erreichbaren. Es gelingt so aber nicht, ein höheres Intelligenzniveau zu erklimmen.
Übertragen auf den Menschen würde das bedeuten, dass beim Zusammenwirken von Dummköpfen, oder dann, wenn jeder einzelne seine Urteilsfähigkeit hintanstellt, Schwarmintelligenz entstehen könnte. Sofern man den Intelligenzbegriff etwas weiter fasst, ist das tatsächlich der Fall. Manipulierte Massen können Dinge bewirken, die über das Vermögen intelligenter Individuen weit hinaus gehen.
Tausend Intelligente sind so intelligent wie der Intelligenteste unter ihnen. Tausend Dummköpfe können die Welt zerstören.
Quellen:
[Bonabeau 1999]: Bonabeau, E./Dorigo, M./Theraulaz, G.: Swarm Intelligence: From Natural to Articial Systems. New York u. a.: Oxford University Press, 1999.
[Dorigo 1996]: Dorigo, M./Maniezzo, V./Colorni, A.: The ant system: Optimization by a colony of coo[1]perating agents. In: IEEE Transactions on Systems, Man, and Cybernetics Part B, Cyber[1]netics 26 (1996), S. 29-41.
[Partridge 1981]: Partridge, B.L.: Internal dynamics and the interrelations of fish in schools. In: Journal of Comparative Physiology 114 (1981), S. 313-325.
[Reynolds 1987]: Reynolds, C.W.: Flocks, herds, and schools: A distributed behavioral model. ACM. In: Computer Graphics 21 (1987), S. 25-34.
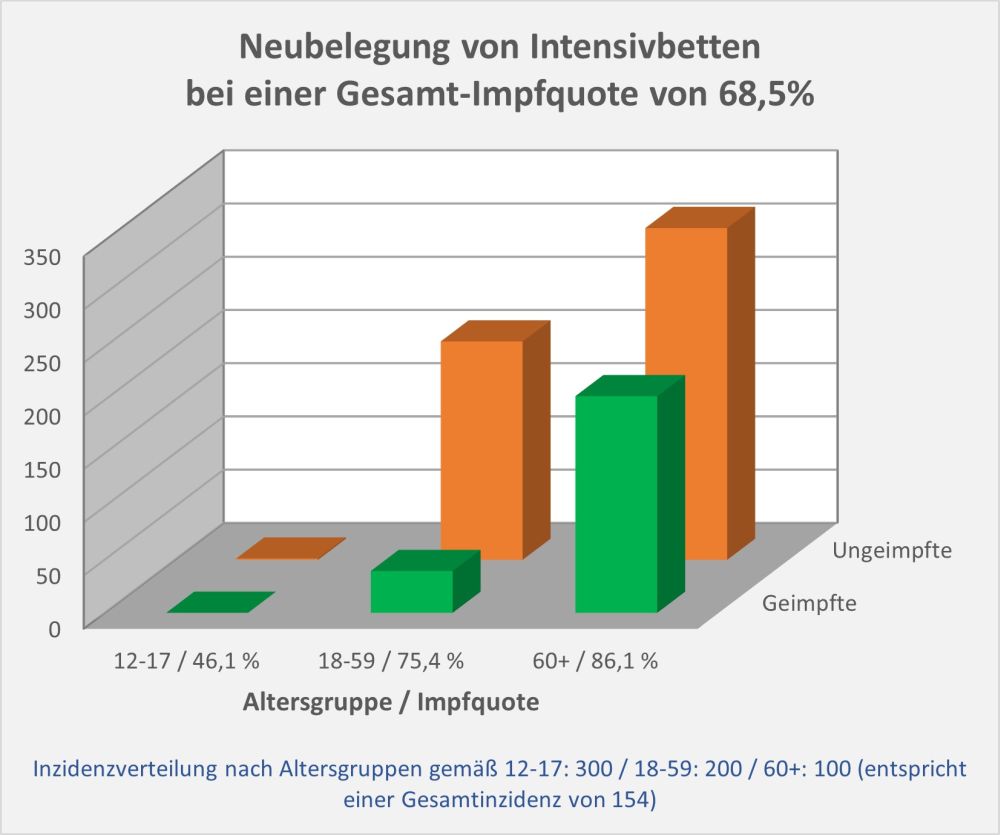
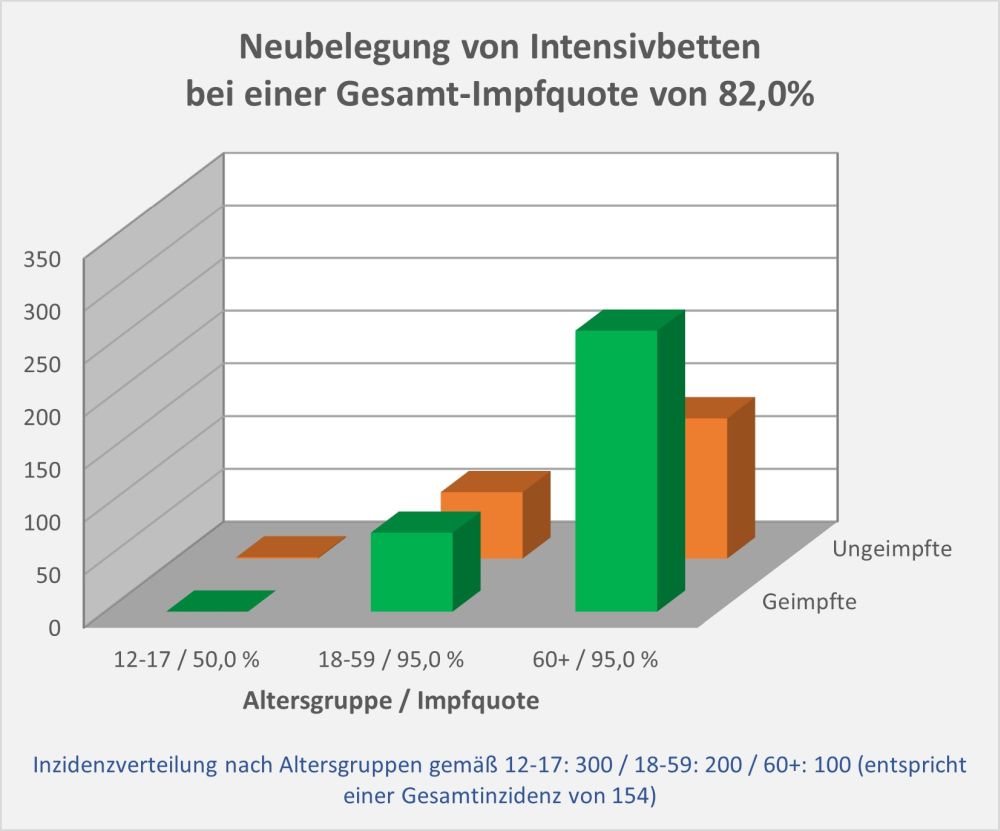
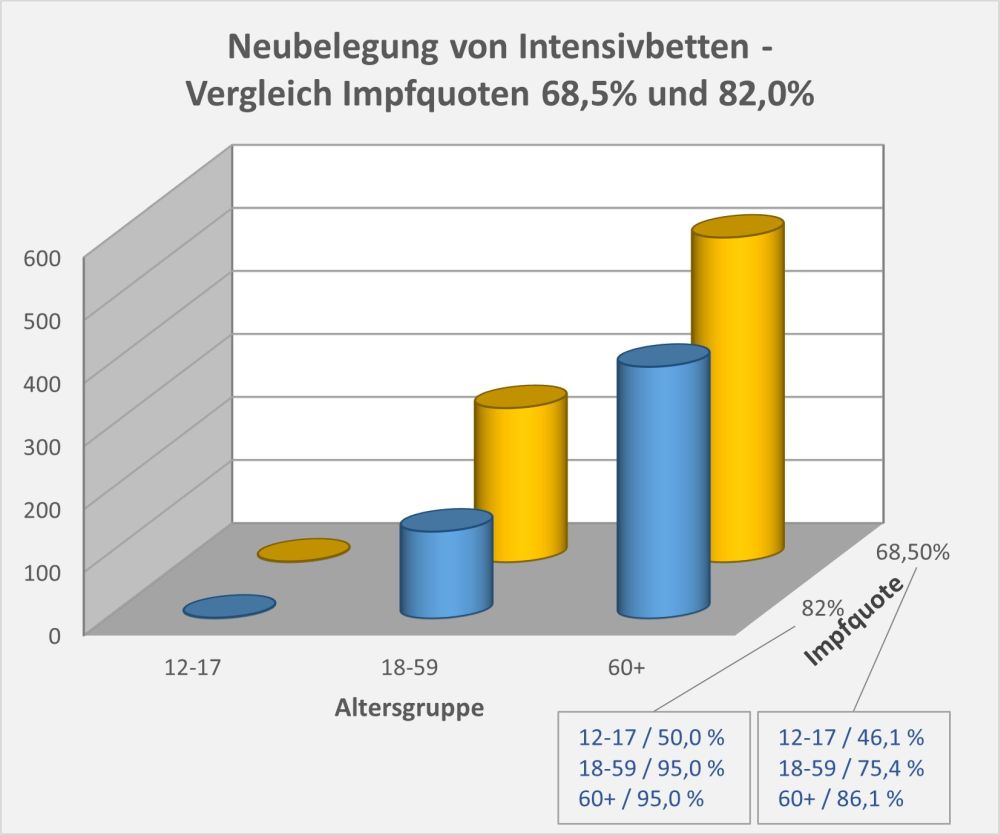
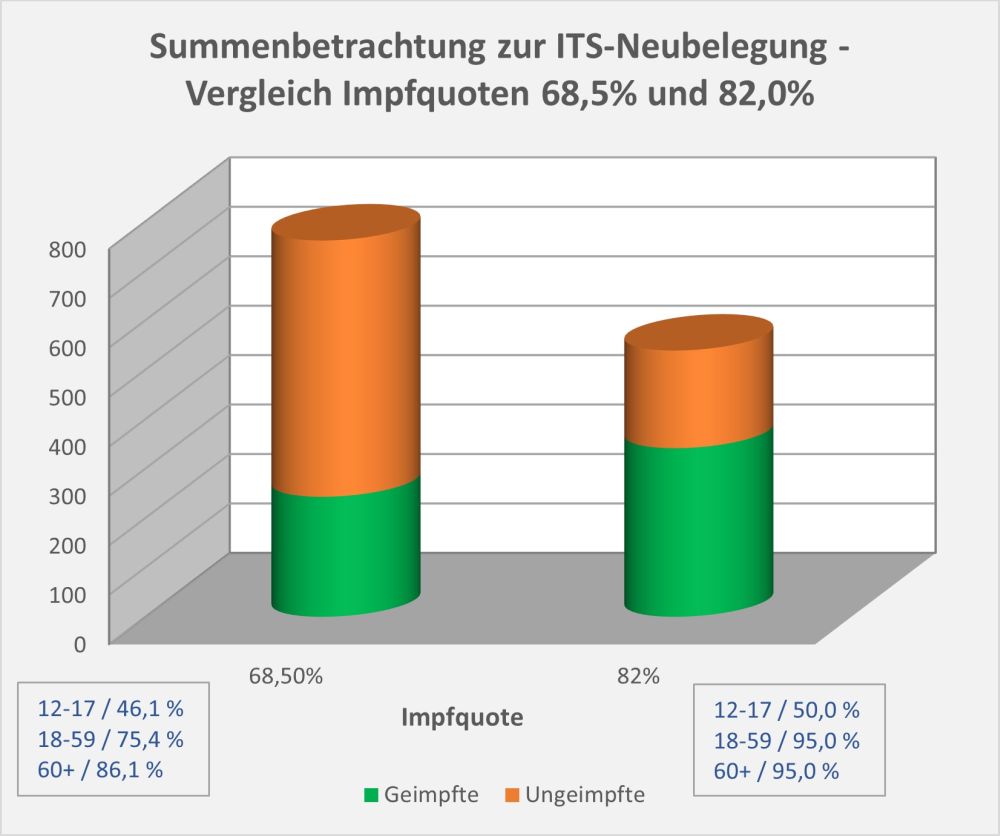
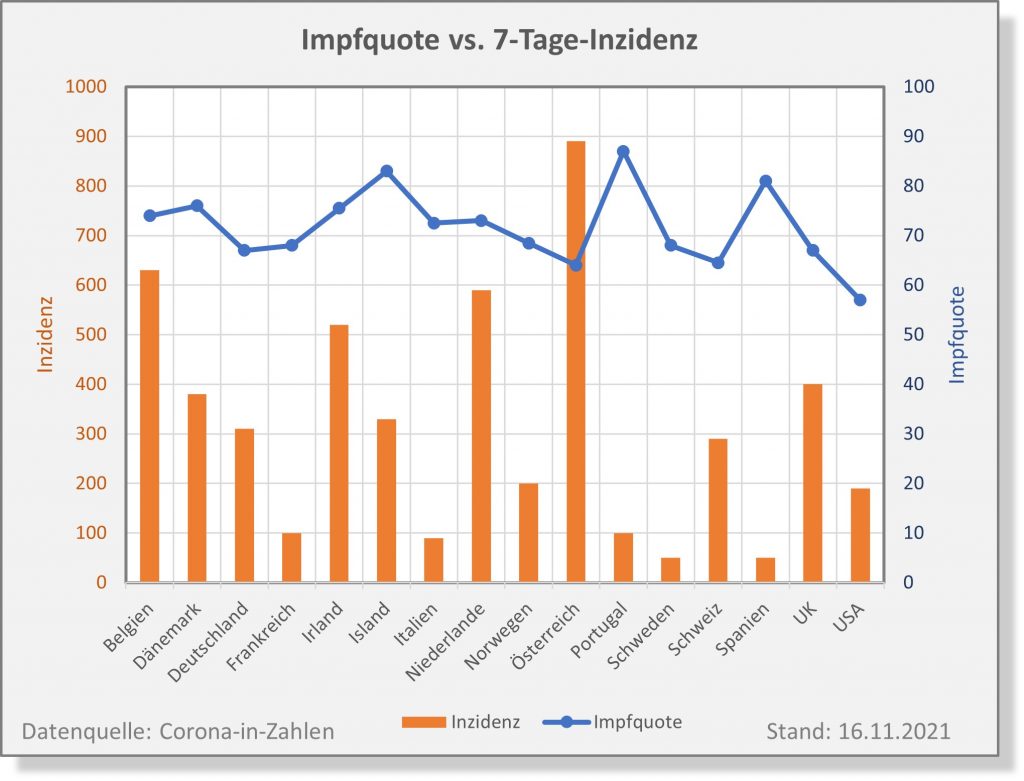
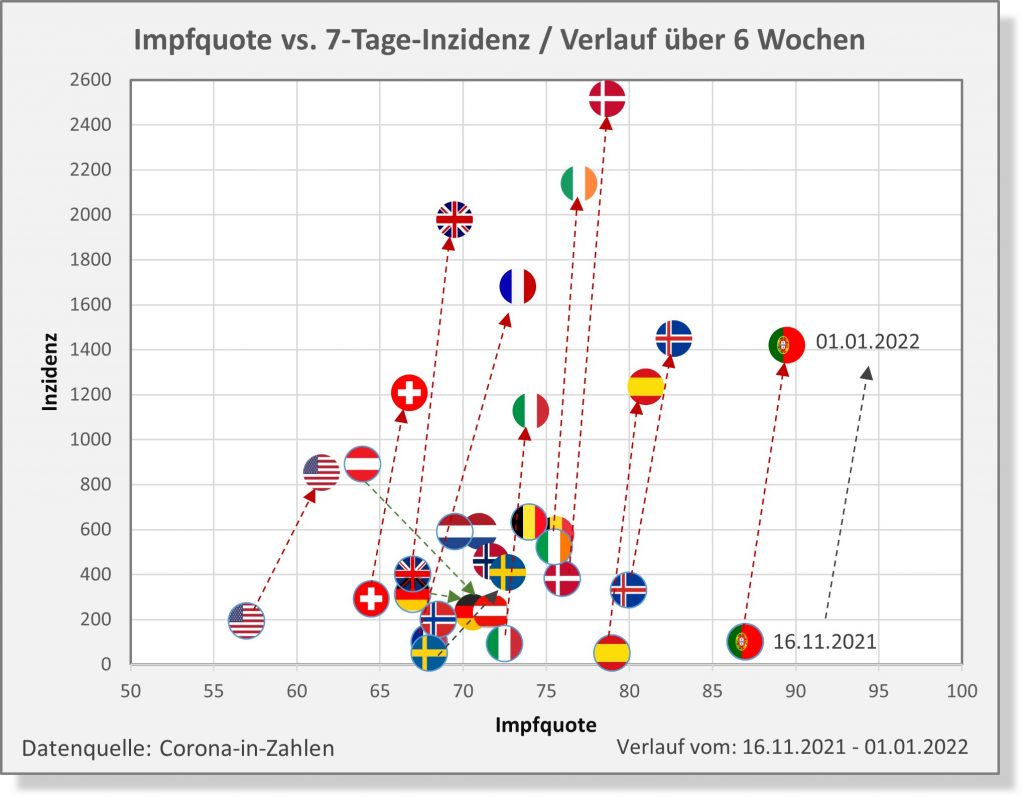
In 2021 wurden in Deutschland ca. 150 Millionen Impfungen mit einem Corona-Impfstoff verabreicht. Insgesamt haben sich über 61 Mio. Personen impfen lassen. Die genauen Zahlen zu den Erst-, Zweit- und Drittimpfungen können Abb. 1 entnommen werden.
Ohne diese Impfungen hätte es wohl eine höhere Zahl von Corona-Todesfällen gegeben, vor allem bei den Älteren (s. [14]). Wo Licht ist, da ist aber auch Schatten: Laut Sicherheitsbericht des Paul-Ehrlich-Instituts (PEI, s. [1]) wurden im Zuge der Impfungen seit Beginn der Impfkampagne Ende 2020 insgesamt 244.576 Verdachtsfälle von Nebenwirkungen und Impfkomplikationen gemeldet (s. Abb. 2).
Viele dieser Meldungen beziehen sich auf letzten Endes vorübergehende Beeinträchtigungen. Betreffend die Dunkelziffer zu den nicht gemeldeten unmittelbaren Nebenwirkungen der Impfung weiß man natürlich nichts. Man kann aber davon ausgehen, dass leichtere Fälle wohl kaum Eingang in die offizielle Statistik finden.
In Summe kann man das abtun als statistische Pflichtübung: Was ist schon dabei, wenn die Einstichstelle für 1 oder 2 Tage schmerzt? Oder wenn man vorübergehend Kopfschmerzen hat? Tatsächlich reden wir hier In den meisten Fällen von temporären Beeinträchtigungen. In etwa 50 % der Fälle waren die Patienten wiederhergestellt oder ihr Allgemeinzustand war verbessert. Ganz so banal ist das dennoch nicht. Bei einem weiteren Drittel der Verdachtsfälle waren die Beeinträchtigungen zum Zeitpunkt der Meldung noch nicht abgeklungen. Und in immerhin 3 % der Fälle geht man von bleibenden Schäden aus.
Abbildung 2: Ausgang der gemeldeten unerwünschten Reaktionen nach Impfung mit einem COVID-19-Impfstoff. Die Prozentangaben beziehen sich auf die Gesamtanzahl der gemeldeten Nebenwirkungen, d.h., 1 Prozentpunkt entspricht ca. 2.500 Fällen. Quelle: PEI, Corona-Sicherheitsbericht 2021, Datenstand: 07.02.2022.
Insgesamt gibt es eine erhebliche Zahl von 29.786 Verdachtsfällen bezüglich derer das PEI selbst von „schwerwiegenden“ unerwünschten Reaktionen spricht (s. Abb. 3). Darunter sind viele Geimpfte, die eine ambulante oder stationäre Behandlung benötigen. Und auch 2255 Verdachtsfälle mit tödlichem Ausgang werden verzeichnet.
Abbildung 3: Anzahl der gemeldeten Nebenwirkungen, der schwerwiegenden Nebenwirkungen und der Verdachtsfälle mit tödlichem Ausgang. Man beachte die logarithmische Skalierung (kleine Werte erscheinen vergleichsweise groß). Rohdaten: PEI, Corona-Sicherheitsbericht 2021, Datenstand: 07.02.2022.
Natürlich muss man das alles in Relation zur Anzahl der Impfungen sehen. Dazu weiter unten.
Verdachtsfälle von Impftoten
Im Jahresbericht des PEI wird die Zahl von 2255 Meldungen mit einem tödlichen Ausgang „in unterschiedlichem zeitlichem Abstand zur Corona-Impfung“ genannt. Genaugenommen spricht das PEI hier von Verdachtsfällen. In 85 Einzelfällen, in denen Patienten an bekannten Impfrisiken wie Thrombose-mit-Thrombozytopenie-Syndrom (TTS), Blutungen aufgrund einer Immunthrombozytopenie oder Myokarditis im zeitlich plausiblen Abstand zur jeweiligen Impfung verstorben sind, hat das PEI den kausalen Zusammenhang mit der Impfung als möglich oder wahrscheinlich bewertet. Man fragt sich an dieser Stelle, was es mit den verbleibenden 2170 Verdachtsfällen auf sich hat. Dazu gibt es im Sicherheitsbericht lediglich einen statistischen Abgleich (s.u.). Es bleibt also offen, inwiefern hier eine ursächliche Beziehung zur Impfung bestehen könnte. Letztlich muss man daher auch in diesen Fällen die Kausalität der Impfung zumindest als „möglich“ erachten, es sei denn, dies kann im Einzelfall definitiv ausgeschlossen werden.
Meldungen über Impfkomplikationenan das PEI
Grundsätzlich werden Meldungen von Nebenwirkungen nach Impfung mit COVID-19-Impfstoffen über die Gesundheitsämter an das Paul-Ehrlich-Institut übermittelt. Ärzte sind gesetzlich verpflichtet, Impfkomplikationen, d. h. gesundheitliche Beschwerden, die über das übliche Ausmaß einer Impfreaktion hinausgehen und nicht evident auf andere Ursachen zurückzuführen sind, dem zuständigen Gesundheitsamt zu melden. Zusätzlich können auch Geimpfte bzw. deren Angehörige direkt dem Paul-Ehrlich-Institut melden.
Kann man also davon ausgehen, dass die Mehrzahl der aufgetretenen Nebenwirkungen tatsächlich gemeldet werden? Nicht unbedingt! Bei den leichteren Fällen wird wohl oft eine Meldung unterbleiben. Jedenfalls ist das die Erfahrung von anderen Impfprogrammen. Man schätzt, dass i. A. nur in etwa 5 % der Fälle von Nebenwirkungen eine Meldung an das PEI erfolgt. Sofern es hier um leichtere Beeinträchtigungen geht, ist das nicht weiter von Belang und allenfalls von Interesse für die Statistik. Indessen kann man nicht ausschließen, dass auch schwerwiegende Fälle übersehen werden, z.B. dann, wenn das Auftreten von Krankheitssymptomen bei einer geimpften Person aufgrund von Vorerkrankungen oder aktuellen gesundheitlichen Beeinträchtigungen auch ohne die Impfung nicht völlig unerwartet gewesen wäre.
Nach einer aktuellen Analyse kommt die BKK Pro Vita zu einen ebenso ernüchternden wie alarmierenden Ergebnis: Es gebe viel häufiger Nebenwirkungen der Corona-Impfung als gedacht. Man gehe von einer sehr erheblichen Untererfassung aus. Die BKK rechnet vor, dass Nebenwirkungen der Impfung laut (ihren) Patientendaten mindestens zehn Mal häufiger sind als vom Paul-Ehrlich-Institut gemeldet. Wenn man die 10 Mio. Versicherte umfassende Stichprobe der BKK auf das Gesamtjahr und auf die Bevölkerung in Deutschland hochrechnet, sindvermutlich 2,5 bis 3 Millionen Menschen in Deutschland wegen Impfnebenwirkungen nach Corona-Impfung in ärztlicher Behandlung gewesen (s. [16]). Vier bis fünf Prozent (der Geimpften) waren wegen Nebenwirkungen beim Arzt.
Betrachten wir konkret das Szenario im Hinblick auf die Verdachtsfälle mit tödlichem Ausgang. Hier denkt man noch am ehesten, kein Fall könne unentdeckt bleiben. In Deutschland gibt es etwa 25.000 Hausarztpraxen. Von ihren Patienten sind circa 5 Millionen über achtzig. Zugleich ist die Impfquote in dieser Gruppe mit über 90 % sehr hoch. Im statistischen Mittel entfallen demnach jeweils 200 Über-80-Jährige auf eine Hausarztpraxis, und nahezu alle wurden 2021 geimpft. Die statistische Sterbewahrscheinlichkeit (völlig ohne Impfung) in dieser Altersgruppe liegt bei etwa 11,5 % p.a. Damit sind in 2021 pro Hausarztpraxis 23 Patienten über 80 verstorben, pro Monat also etwa 2 Personen. Es ist also absolut nicht ungewöhnlich, wenn von den 200 hochbetagten Patienten einer Hausarztpraxis jeden Monat 2 versterben. Ebenfalls nicht sonderlich überraschend ist es, wenn diese Sterbefälle innerhalb von 30 Tagen nach der Impfung auftreten: Es liegt ja völlig im Rahmen des Üblichen. Wenn nicht außergewöhnliche Umstände vorliegen, hat der Hausarzt kaum eine Chance, solche Todesfälle mit der Impfung in Zusammenhang zu bringen. Und was, wenn er davon gar nichts erfährt, weil sich der Patient im Impfzentrum hat impfen lassen?
Die Meldungsstatistik des PEI ist daher zunächst einmal nur eine Grundlage für die grobe Beurteilung von Risiken. Eine abschließende Bewertung ist auf dieser Basis kaum möglich (s. a. [16]).
Risikoeinschätzung auf Basis der Meldezahlen
Das PEI bezieht die gemeldeten Fälle auf die Anzahl der Impfdosen. Das erscheint naheliegend und zweckmäßig. In Relation zu den ca. 150 Mio. Impfungen ergibt sich auf dieser Basis eine Melderate von 1600 Fällen von Nebenwirkungen pro 1 Mio. Impfungen, und 200 Fällen von schwerwiegenden Nebenwirkungen pro 1 Mio. Impfungen. Der relative Anteil der Verdachtsfälle mit tödlichem Ausgang liegt bei 15 pro 1 Mio. Impfungen. Um zu einer ersten Einschätzung zu kommen, inwiefern das viel oder wenig ist, kann man diese Zahl den im gleichen Zeitraum „an oder mit“-Corona-Verstorbenen gegenüberstellen. Aufgrund der knapp 70.000 Coronatoten in 2021 sind das etwa 839 Tote pro 1 Mio. Einwohner, mithin etwa das 56-fache der Anzahl der Verdachtsfälle von Impftoten. Doch ist dieser Vergleich zulässig?
Für die Risikoeinschätzung sinnvoller erscheint die Bezugnahme auf die Anzahl der Geimpften. Letzten Endes muss doch die mögliche Gefährdung der Person interessieren, nicht das Risiko des impfenden Arztes. Wenn man sich, wie das PEI, auf die Anzahl der Impfungen bezieht, wird das Bild in unzulässiger Weise geschönt insofern das Risiko kleiner erscheint als es wirklich ist.
Die o.g. ca. 150 Mio. Impfdosen wurden lt. PEI an 61.593.423 Personen verabreicht. Im Mittel wurde demnach jeder Geimpfte etwa zweieinhalbmal „gepikst“. Berücksichtigt man dies in der Statistik, so ergibt sich ein geschärftes Bild zum Risiko:
3971 Fälle von Nebenwirkungen pro 1 Mio. Geimpfte
484 Fälle von schwerwiegenden Nebenwirkungen pro 1 Mio. Geimpfte
37 Verdachtsfälle mit tödlichem Ausgang pro 1 Mio. Geimpfte
Vergleicht man die letzte Zahl wieder mit den 839 Coronatoten pro 1 Mio. Einwohner, so ergibt sich nun ein Verhältnis von 23:1. Das spricht im Grundsatz immer noch klar für die Impfung, das Risikoverhältnis ist aber nicht so überwältigend positiv, wie man das eigentlich vermuten würde. Vor allem, wenn man dabei die völlig unterschiedliche Corona-Risikobewertung im Hinblick auf die diversen Altersgruppen berücksichtigt
Abbildung 4: Melderate über Verdachtsfälle von Nebenwirkungen und Impfkomplikationen nach Impfung zum Schutz vor COVID-19 pro 1 Mio. Geimpfte seit Beginn der Impfkampagne am 27.12.2020 bis zum 31.12.2021. Zum Vergleich ist in der rechten Rubrik die Corona-Todesfallzahl pro 1 Mio. Einwohner eingetragen. Rohdaten: RKI, PEI, Corona-Sicherheitsbericht 2021, Datenstand: 07.02.2022.
Die Anzahl der gemeldeten schwerwiegenden Nebenwirkungen liegt „nur“ 58 % unter der Anzahl der registrierten Todesfälle „an oder mit“ Corona. Das ist ein vergleichsweise kleiner Abstand. Wobei trotzdem klar ist: Vor die Wahl gestellt, würden sicher alle Verstorbenen die Alternative der schwerwiegenden Nebenwirkung nach der Impfung gerne in Kauf genommen haben.
Zusammenhang zwischen Impfung und möglichen Nebenwirkungen
Aufgrund der Meldungssystematik darf man zweifelsohne unterstellen, dass zumindest die zeitnah auftretenden Nebenwirkungen zu einem gewissen Teil erfasst werden. Selbst wenn wir davon ausgehen, dass es gar keine Dunkelziffer gibt, wird man die Fallzahl mit knapp 250.000 Fällen von Nebenwirkungen und knapp 30.000 Verdachtsfällen von schwerwiegenden unerwünschten Reaktionen kaum als vernachlässigbar abtun können. Es sind fraglos viele Fälle. In Relation zu den ca. 150 Mio. Impfungen ist die Melderate aber dennoch klein: 1,6 Fälle von Nebenwirkungen pro 1000 Impfungen, und 0,2 Fälle von schwerwiegenden Nebenwirkungen pro 1000 Impfungen.
Dabei hat man es hier im Grundsatz mit einfach zu identifizierenden Impfreaktionen zu tun, weil sie in einem engen zeitlichen Abstand zur Impfung auftreten. Viel schwieriger oder gar unmöglich ist der Nachweis einer nachgelagerten Folgewirkung, die erst Monate oder gar Jahre nach der Impfung auftritt. Wie wollte man denn zweifelsfrei belegen, dass das Auftreten einer Autoimmunkrankheit auf eine Jahre zurückliegende Impfung zurückzuführen sei? Allenfalls würde man in diesem Falle eine statistische Korrelation finden können, was natürlich kein Beweis ist. Vor Gericht hätte ein solcher Nachweis wohl kaum Bestand.
Laut PEI ist von langfristigen Impffolgen nichts bekannt. Darf man daraus schließen, dass es solche Impffolgen nicht gibt? Diese Schlussfolgerung ist möglicherweise übereilt. Das Wirkprinzip von mRNA-Impfstoffen ist neu, deswegen kann man auch nachgelagerte oder indirekte Folgen auf das Immunsystem nicht mit Sicherheit ausschließen. Wer dies tut, verstößt gegen elementare wissenschaftliche Prinzipien und handelt unredlich. Analogieschlüsse aus den historischen Impfprogrammen sind nicht hinreichend für den Ausschluss von Langzeitfolgen, weil die Analogie aufgrund des neuartigen Wirkprinzips so nicht besteht.
Man muss sich vergegenwärtigen, dass die mRNA-Impfstoffe noch immer nicht über eine reguläre Zulassung verfügen. Von der Politik und den Medien wird das weitgehend ignoriert. Stattdessen verweist man gerne auf das Paul-Ehrlich-Institut und präsentiert meistens solche Wissenschaftler, die in ihren Statements jegliche von der Impfung möglicherweise ausgehenden Gefährdungen mehr oder weniger als Hirngespinste abtun. Indessen gibt es aber auch seriöse kritische Stimmen, auch wenn man wenig von ihnen hört (s. dazu [17] Fragezeichen beim mRNA-Impfstoff).
Auch wenn man eine unmittelbare Gefahr mit größter Sicherheit ausschließen kann, da die Impfstoffe schon millionenfach verabreicht wurden (darauf fußt das Urteil des PEI), so gebietet die wissenschaftliche Skepsis im Verein mit der ärztlichen Vorsicht, solche vorschnellen Verharmlosungen zu unterlassen. Dies vor allem dann, wenn es um Impfprogramme für Kinder geht. Es besteht ein Restrisiko, über das man nichts Genaues weiß. Möglicherweise wird es sich als klein erweisen, das ist aber nicht gewiss. Wer das Risiko jetzt aus politischen Gründen kleinredet, ignoriert eherne wissenschaftliche Grundsätze und wird seiner Verantwortung nicht gerecht.
Natürlich kann man pragmatisch argumentieren, das bekannte von Corona ausgehende Risiko sei höher einzuschätzen als das unbekannte Restrisiko möglicher Spätfolgen. Das ist ein politisch opportuner Zugang, den man durchaus vertreten kann. Man muss ihn aber nicht zwingend gutheißen, weil ihm die wissenschaftliche Grundlage fehlt. Zumindest sollte, wer dies propagiert, sich nicht auf die Wissenschaft berufen. Es ist dennoch ein oft anzutreffendes Verhalten: Risiken, die man in Ermangelung verlässlicher Daten und gezielter Untersuchungen nicht quantifizieren kann, werden kurzerhand als nicht existent deklariert. Manchmal wird das sogar explizit als „wissenschaftlich“ ausgegeben, sogar von Wissenschaftlern – tatsächlich ist es nicht mehr als Augenwischerei.
Jedenfalls ist es unwissenschaftlich und damit unseriös, mögliche Langzeitfolgen pauschal auszuschließen. Diesen Schluss mögen sich Leute zutrauen, die ihr Wissen durch den Blick in die Kristallkugel gewinnen.
Zusammenhang zwischen Impfung und möglichen Todesfällen
Kann man davon ausgehen, dass zumindest die Verdachtsfälle mit tödlichem Ausgang nach der Impfung vollständig erfasst werden? Daran muss man Zweifel anmelden. Die Gründe dafür liegen wieder in der Statistik.
Unabhängig von der Impfung liegt die durchschnittliche Sterblichkeit bei 1,24 % p.a. Von einer Million Menschen sterben also statistisch gesehen 12.400 innerhalb der nächsten 12 Monate nach einem willkürlich festgesetzten Datum. Entsprechend sterben nach der verabreichten Impfung im statistischen Mittel ca. 1000 Personen im Laufe der folgenden 30 Tage. Hochgerechnet auf die Gesamtanzahl der in 2021 Geimpften (61,5 Mio.) muss man daher 61.500 Tote innerhalb von gut 4 Wochen nach der Impfung erwarten. Tatsächlich wurden aber nur 2255 Todesfälle (3,7 % von 61.500) in zeitlicher Nähe zur Impfung registriert. Was kann man daraus schließen?
Dreierlei:
Nur ein Bruchteil von weniger als 4 % der statistisch zu erwartenden Verdachtsfälle mit tödlichem Ausgang innerhalb von 4 Wochen nach der Impfung wurde tatsächlich gemeldet (Meldequote 1 Fall von 27). Das könnte darauf hindeuten, dass der mögliche Zusammenhang zwischen Impfung und Versterben in vielen Fällen nicht registriert wurde (s. dazu auch obiges Beispiel betreffend der Hausarztpraxen).
Wenn wir unterstellen, dass jeder dieser Todesfälle im Hinblick auf die Impfung ärztlich bewertet wurde, dann würde sich damit der Verdacht der Impfkausalität erhärten. Wir müssten also davon ausgehen, dass in all diesen Fällen (also den genannten 2255) der Tod mit hoher Wahrscheinlichkeit als unmittelbare Folge der Impfung eingetreten ist. Damit wären das keine bloßen Verdachtsfälle mehr.
Es gibt noch eine dritte Sicht: Die nur etwa 4 % dokumentierten Verdachtsfälle liegen im Bereich der möglichen statistischen Schwankungen und fallen daher in der Gesamtschau nicht ins Gewicht. Die Gesamtanzahl der Verstorbenen ist aufgrund der Impfung offensichtlich nicht statistisch signifikant angestiegen. Daraus kann man unmittelbar auf die relative Harmlosigkeit der Impfung schließen. Das ist in etwa die Position des PEI.
Was ist zutreffend? Man darf vermuten, dass alle drei Sichten einen Teil der Wahrheit repräsentieren. Die nackte Statistik spricht für die Position des PEI. Wenn vom Impfstoff tatsächlich eine nennenswerte Gefahr in unmittelbarer zeitlicher Nähe zur Impfung ausgehen würde, dann müsste sich das in den Todesfallzahlen zeigen. Dass dies dennoch eine Gratwanderung ist, zeigt die folgende Überlegung: Vorausgesetzt, wir zählen nur die unmittelbar nach der Impfung und ggf. am Folgetag aufgetretenen Todesfälle, dann ergeben sich dafür im statistischen Mittel 2050 Tote (= 61.500/30). Das sind in etwa bereits so viele, wie insgesamt für das gesamte Jahr an das PEI gemeldet wurden. Diese Fallzahl würde man auch dann erwarten, wenn man ein Placebo gespritzt hätte. Es erscheint daher zweifelhaft, inwiefern mittels dieser Vorgehensweise eine schwach ausgeprägte Todeskausalität überhaupt identifiziert werden könnte.
Umgekehrt kann man sich auch fragen, bei welcher Anzahl von Verdachtsfällen ein mögliches Risiko erkannt werden würde. Die 2255 Fälle werden offenbar noch nicht als Risikosignal gesehen, da sie mehr oder weniger im statistischen Rauschen untergehen. Indessen würden auch 10.000 Verdachtsfälle noch weit unter der statistisch zu erwartenden Anzahl von 61.500 Fällen liegen. Es ist daher eine offene Frage, inwieweit dieser Ansatz überhaupt dafür geeignet ist, mögliche Risiken sicher zu erkennen. Um es ganz pointiert zum Ausdruck zu bringen: Wenn die Menschen nach der Impfung nicht wie die Fliegen sterben, dann wird man mittels dieser Methodik kaum valide Indizien für eine eventuell bestehende ernsthafte Problematik finden.
Betreffend möglicher Langzeitfolgen ist die Situation keineswegs besser: Es gibt derzeit kein Verfahren für die sichere Detektion möglicher Risikofaktoren.
Vergleich mit anderen Impfprogrammen
Von 2000 bis 2019 wurden in Deutschland mehr als 580 Mio. Impfungen durchgeführt, im Schnitt also immerhin mindestens 34 Mio. Impfungen pro Jahr. Dabei waren insgesamt 456 Todesfälle nach Impfungen gemeldet worden (jährlich also etwa 22 Fälle). Im Vergleich dazu fallen die 2255 Verdachtsfälle mit tödlichem Ausgang in 2021 aus dem Rahmen (s. Abb. 5). Und zwar erheblich: Für ein Viertel der verabreichten Impfdosen zählen wir die fünffache Anzahl von Verdachtsfällen mit tödlichem Ausgang. Im Ergebnis ist damit das potentiell von der Corona-Impfung ausgehende Risiko etwa zwanzigmal höher als das mittlere Risiko in den historischen Impfprogrammen der letzten 20 Jahre.
Abbildung 5: Risikovergleich mit historischen Impfprogrammen. Das relative Risiko bei der Corona-Impfung ist gegenüber den Vergleichsimpfungen um den Faktor 20 höher. Quelle: PEI, Corona-Sicherheitsbericht 2021, Datenstand: 07.02.2022.
Die Vergleichsdaten legen nahe, dass die aktuell verfügbaren Corona-Impfstoffe nicht zu den sichersten und harmlosesten Vakzinen gehören, die je entwickelt wurden. Selbstverständlich ändert das nichts daran, dass die Impfung in der weit überwiegenden Anzahl der Fälle nichtsdestotrotz Nutzen stiftet. Einige tausend Hochbetagte zusätzlich wären wohl ohne die Impfung Opfer des Virus geworden. Indessen sollte man angesichts der nüchternen Fakten Verständnis aufbringen für Menschen, die bezüglich der Corona-Impfung in ihrer eigenen Risikobewertung nach wie vor zögern. Vor allem auch eingedenk der nicht seriös ausschließbaren möglichen Langzeitfolgen, selbst wenn man die eher für unwahrscheinlich halten möge. Das Aufzeigen des Nutzens ist nur die eine Hälfte der nötigen Aufklärung, dazu gehört ebenso die offene Kommunikation bezüglich der möglichen Risiken.
An oder mit der Impfung verstorben?
Wir haben oben die statistisch zu erwartende Anzahl der Todesfälle in zeitlicher Nähe zur Impfung bestimmt. Dabei wurde das Verfahren des PEI angewendet (Bezug auf die mittlere Sterberate von 1,24% p.a.). Dieser Ansatz ist unscharf, insofern die Altersstruktur der Impfkohorte dabei keine Berücksichtigung findet. Das ist deswegen von Bedeutung, weil es natürlich einen Unterschied macht, ob ein 80-Jähriger innerhalb von 5 Tagen nach der Impfung verstirbt oder ob dasselbe einem 20-Jährigen widerfährt. Der Grund liegt auf der Hand: Letzterer hat ein etwa 160-mal geringeres allgemeines Sterberisiko. Wenn also der erste Fall eintritt, dann liegt das viel eher im Rahmen der Erwartung als im zweiten Fall. Diese Differenzierung geht in der pauschalen Betrachtung des PEI verloren.
Nun kennen wir nicht die genaue Zusammensetzung der an das PEI ergangenen Meldungen hinsichtlich der Altersstruktur. Wir haben aber hinreichende Kenntnis zu den altersabhängigen Impfquoten. Das erlaubt uns eine etwas schärfere Betrachtung im Hinblick auf die statistische Erwartung betreffend die Fallzahlen.
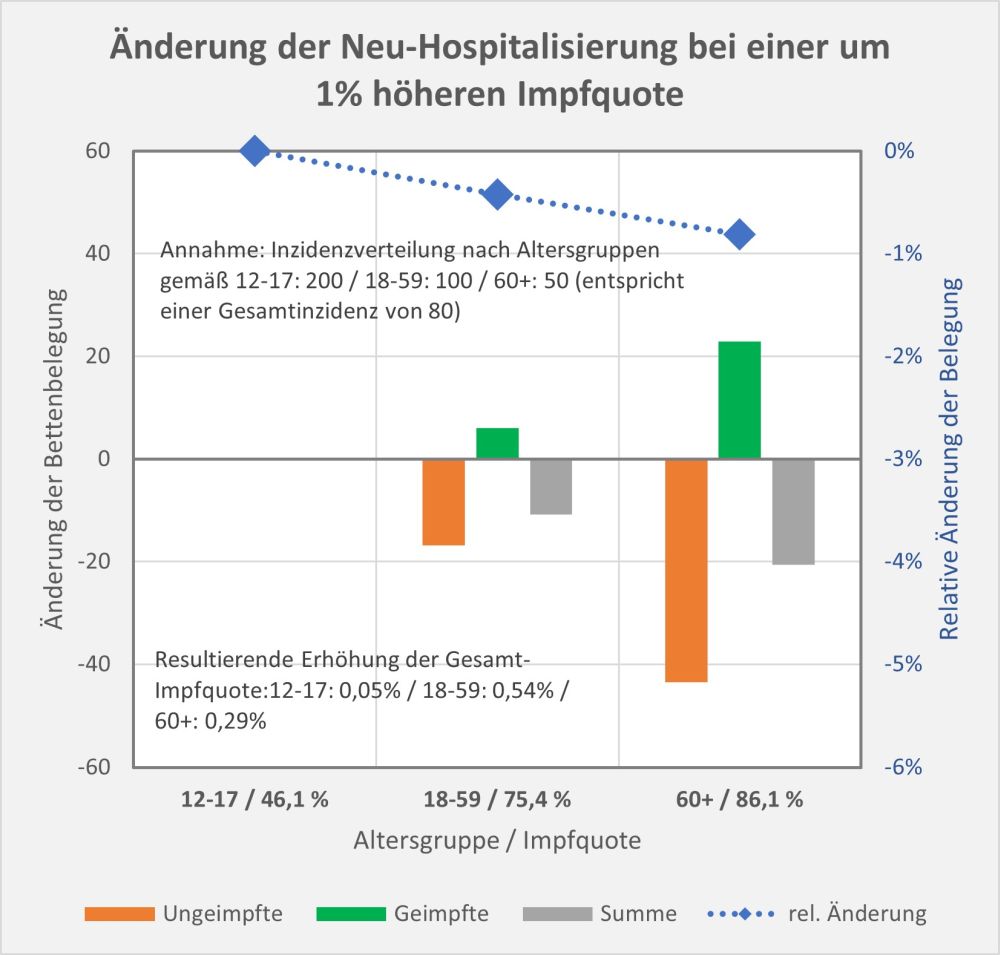
Abbildung 6: Statistische Erwartungswerte für die Anzahl der aufgrund des allgemeinen altersbezogenen Sterberisikos „an oder mit“ der Impfung innerhalb von 30 Tagen Verstorbenen. Die rot gestrichelte Linie markiert die an das PEI tatsächlich gemeldeten Fälle. Man sieht, dass tatsächlich nur ein winziger Bruchteil (1 von 38 Fällen) der innerhalb von 30 Tagen nach der Impfung statistisch zu erwartenden Todesfälle als Verdachtsfälle registriert wurden. Zugrunde gelegt wurden folgende Impfquoten (mit mindestens 1 Dosis): Altersgruppe 12-17: 55%, Altersgruppe 18-59: 80%, Altersgruppe 60+: 90%. Quelle für die Rohdaten: RKI, Datenstand: 07.02.2022.
Aus der vorstehenden Grafik wird klar ersichtlich, dass die Meldungen an das PEI nur einen winzigen Bruchteil der Todesfälle in zeitlicher Nähe zur Impfung (30 Tage) ausmachen. Die daraus im Hinblick auf mögliche Risikosignale resultierenden Fragen wurden oben angesprochen.
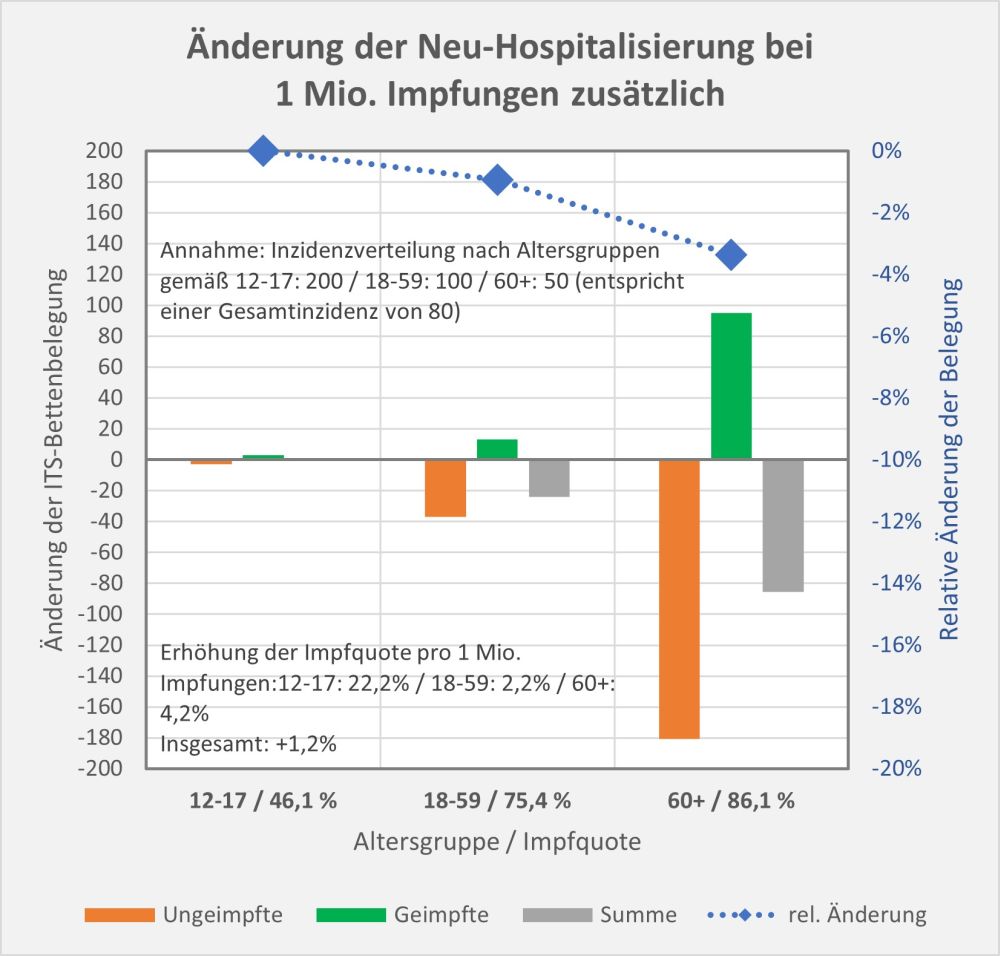
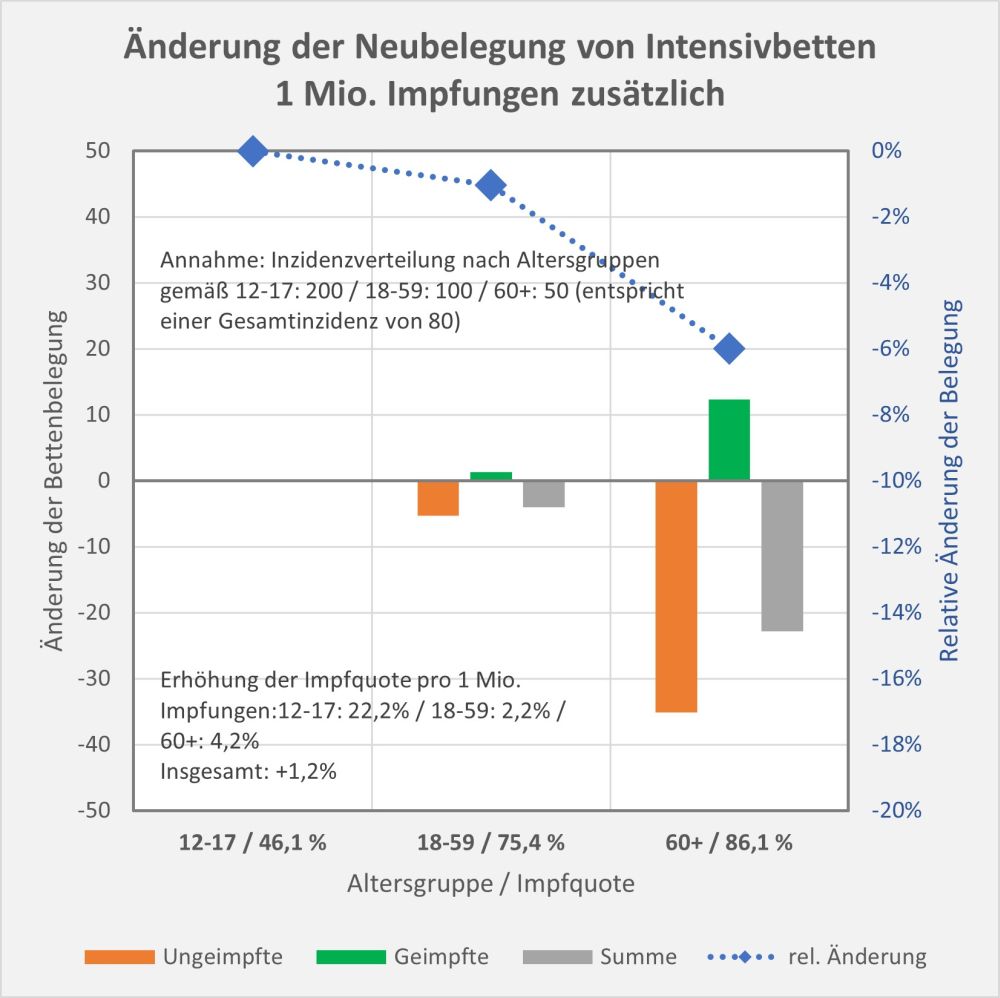
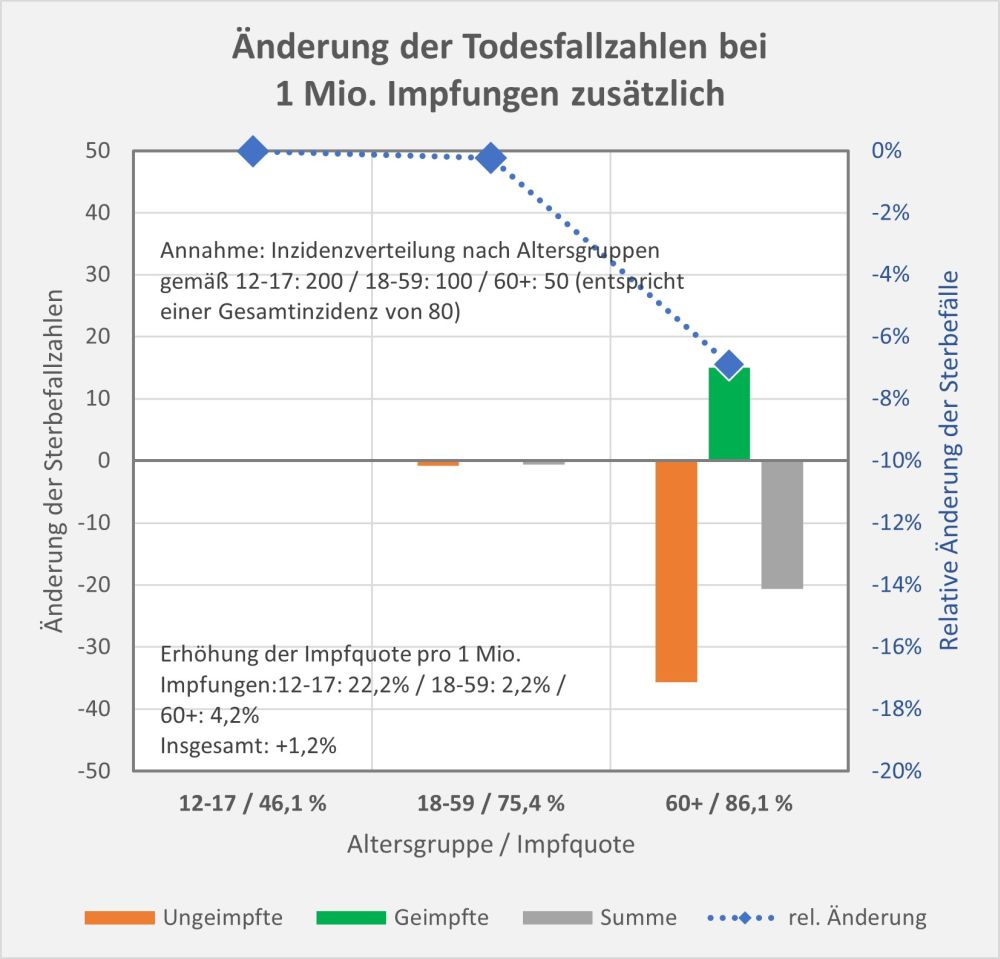
Man kann noch eine weitere, allerdings spekulative Analyse hinsichtlich der potentiell von der Impfung ausgehenden Sterbefälle anschließen. In [14] und [15] wurde gezeigt, wie die hypothetische Änderung der Wirksamkeit des Impfstoffs Einfluss nimmt auf die Anzahl der an oder mit Corona Verstorbenen.
Damit können wir bestimmen, wie viele Geimpfte bei sonst gleichen Rahmenbedingungen bei einer geänderten Wirksamkeit des Impfstoffs an Corona verstorben wären. Aus der statistischen Analyse zu den Fallzahlen für 2020 und 2021 (s. [14]) ergibt sich, dass unter den knapp 70.000 an oder mit Corona Verstorbenen etwa 28.000 geimpft waren. Sie sind also trotz der Impfung Opfer des Virus geworden. Dabei wurden pro Altersgruppe unterschiedliche Impfquoten und Wirksamkeiten des Impfstoffs unterstellt (s. Tab. 1, Spalten 2, 3 und 5).
Tabelle 1: Annahmen zu den altersgruppenspezifischen Impfquoten und den Schutzwirkungen der Impfung vor Tod (an oder mit Corona). Die durchschnittlichen Impfquoten ergeben sich aus dem Verlauf der Impfkampagne im Jahresverlauf aus den Daten des RKI. Die Annahmen zur Schutzwirkung basieren auf den Infektionszahlen und den Todesfallzahlen Geimpfter und Ungeimpfter. Die Istwerte zu den Verstorbenen Geimpften wurden auf Basis des in [14] beschriebenen Modells berechnet. Die Sollwerte ergeben sich aus der im Text dargelegten Überlegung. Generell muss man anmerken, dass vielfach keine genauen Zahlen zu Geimpften und Ungeimpften publiziert werden, deshalb wurden die Werte methodisch abgeschätzt (s. [14]).
Laut Zulassungsstudien sollte die Schutzwirkung vor Tod für alle Altersgruppen bei mindestens 90 % gelegen haben. Das trifft jedenfalls auf die beiden meistgeimpften Vakzine von Biontech und Moderna zu. Indes ist diese hohe Schutzwirkung nicht vereinbar mit der beobachteten großen Anzahl der an oder mit Corona verstorbenen Geimpften. Um den Unterschied zu den realen Fallzahlen aufzulösen, gibt es zwei Ansätze: 1. Die tatsächliche Wirksamkeit (in Tab. 1 „der Istwert“) war deutlich geringer. Das wurde in [14] behandelt. 2. Die Wirksamkeit war unverändert hoch (in Tab. 1 „der Sollwert“), wie vom Hersteller angegeben, aber die Betroffenen sind zu einem gewissen Anteil nicht an oder mit Corona verstorben, sondern an oder mit der Corona-Impfung.
Es gilt als Sakrileg, überhaupt nur die Möglichkeit zu erörtern, von der Corona-Impfung könne eine Gefährdung ausgehen. Indes geht es hier nicht um Glauben, sondern darum, Antworten auf offene Fragen zu finden. Daher ist es zulässig, die aus dem Grundgedanken von Punkt 2 resultierenden Konsequenzen näher zu beleuchten. Das ändert freilich nichts daran, dass die Überlegungen dazu zum jetzigen Zeitpunkt ganz klar spekulativen Charakter haben. Inwieweit die Impfung Risiken birgt, eventuell auch ernsthafte, ist letztlich eine medizinische Frage. Angesichts der nur höchst unzureichend erfassten und ungenauen Daten hinsichtlich fast aller Aspekte der Pandemie – ein Armutszeugnis für einen Industrie- und Wissenschaftsstandort – muss die Aussagekraft der Statistik zwangsläufig beschränkt bleiben.
Im Falle von Punkt 2 können wir die hypothetische Anzahl der an oder mit Corona verstorbenen Geimpften unter der Annahme der Soll-Wirksamkeit direkt aus der beobachteten Fallzahl bei der Ist-Wirksamkeit berechnen.
Sei die beobachtete Ist-Wirksamkeit des Impfstoffs und die hypothetische Soll-Wirksamkeit. Entsprechend bezeichnen wir mit die tatsächliche Anzahl der verstorbenen Geimpften und mit die hypothetische Anzahl unter der Annahme der Soll-Wirksamkeit. Es gilt folgender Zusammenhang (s. [14], Analogie zu Formel (34) bei unveränderter Impfquote):
(1)
Die damit unter der Annahme eines über alle Altersgruppen wirksamen Schutzes vor Tod in Höhe von 90 % (=Soll-Wirksamkeit) errechneten Zahlenwerte finden sich in Tab. 1. Insgesamt ergeben sich statt der 28.000 Todesfälle an oder mit Corona (unter Geimpften) nur knapp 8.000 Fälle (s. Tab. 1, Spalte 6, „Sollwert verstorbene Geimpfte“), die im engeren Sinne an oder mit Corona verstorben sein könnten. Wobei angemerkt werden soll, dass die solchermaßen errechneten Zahlen unsicher sind. Die tatsächliche Wirksamkeit der Impfstoffe ist eben nicht mit der nötigen Genauigkeit bekannt. Bei einer Unschärfe von 10 % könnte der Sollwert in Spalte 6 auch bei etwa 16.000 Fällen zu liegen kommen, so dass am Ende nicht 20.000, sondern nur 12.000 Sterbefälle verblieben (Spalte ganz rechts).
Die Differenz von 20.000 (oder evtl. auch nur 12.000) ginge somit potentiell auf das Konto der Impfung, so dass wir diesbezüglich sagen könnten, „an oder mit Corona oder an oder mit der Corona-Impfung“ verstorben. Diese Interpretation steht nicht im Widerspruch zur Anzahl der an das PEI gemeldeten Verdachtsfälle mit tödlichem Ausgang, da der statistische Erwartungswert dafür sogar innerhalb der ersten 30 Tage nach der Impfung bei über 80.000 Personen liegt, übers volle Jahr gerechnet sogar bei ca. 1 Mio. Toten. Die genannte Zahl von potentiell 20.000 Toten macht daher an den innerhalb von 12 Monaten nach der Impfung Verstorbenen einen Anteil von nur 2,2 % aus. Es gibt also kein statistisches Missverhältnis.
Damit wird nicht behauptet, die genannten 20.000 (oder evtl. auch nur 12.000) Sterbefälle seien definitiv auf die Impfung zurückzuführen. Mit dieser Interpretation würde man die Beweiskraft der Statistik weit überschätzen. Evidenz kann man an dieser Stelle nur auf der Basis von gezielten Untersuchungen der Einzelfälle, im Extremfall also aller verstorbenen positiv getesteten Geimpften, erlangen. Im Minimum sind statistisch signifikante Stichproben erforderlich. Unabhängig davon könnte eine kausal auf die Impfung zurückzuführende und in der beschriebenen Weise erhöhte Sterblichkeit von etwa 0,033 % (= 20.000/61,5 Mio.) die trotz der Verfügbarkeit von im Prinzip hochwirksamen Impfstoffen beobachtete leichte Übersterblichkeit schlüssig erklären. Nichtsdestotrotz bleibt diese Folgerung eine Spekulation, da sie mit rein statistischen Mitteln nicht verifiziert werden kann.
An oder mit Corona verstorben?
Die Todesfallzahlen betreffend Corona sind bekanntermaßen immer mit dem Zusatz „an oder mit“ Corona verstorben versehen. In der öffentlichen Wahrnehmung geht das zunehmend unter. Man kann davon ausgehen, dass die knapp 70.000 Coronatoten in 2021 von einer großen Mehrheit als kausal auf Corona zurückzuführende Fälle verstanden werden. Und in diesem Sinne werden die Zahlen auch kommuniziert. In wie vielen Fällen Corona tatsächlich die Todesursache ist, das ist völlig offen.
Man muss den Eindruck gewinnen, dass es auch niemand interessiert. Es gibt allenfalls einige wenige kritische Stimmen. Genaueres weiß man schlechterdings nicht. Mal liest man die Schlagzeile „29 % der Coronatoten gar nicht an Corona verstorben“, mal hört man gar von bis zu 80 % Fällen, bei denen Corona zumindest nur einer von mehreren Faktoren gewesen sein soll. Letzten Endes sind diese Angaben sämtlich nicht vertrauenswürdig, weil ihnen die wissenschaftliche Grundlage fehlt. Dafür müsste man die Todeskausalität in jedem Einzelfall untersuchen, oder zumindest statistisch signifikante Stichproben nehmen. Warum Letzteres nicht systematisch umgesetzt wird, ist nur eine von vielen unwissenschaftlichen Auffälligkeiten im Pandemiemanagement.
An dieser Stelle kann man dennoch die Plausibilität der Corona-Todesfallzahlen mittels statistischer Methoden auf die Probe stellen. Dazu nehmen wir die Zahl der „an oder mit“ Corona Verstorbenen und vergleichen sie mit der statistisch zu erwartenden Anzahl der Todesfälle im Vergleichszeitraum. Wir fragen also konkret, wie viele der positiv auf Corona getesteten Personen wären denn aufgrund der altersabhängigen statistischen Sterbewahrscheinlichkeit im Vergleichszeitraum gestorben. Im Grundsatz handelt es sich hierbei und dasselbe Verfahren, wie es auch vom Paul-Ehrlich-Institut betreffend die Impfungen im Hinblick auf die Verdachtsfälle mit tödlichem Ausgang angewandt wird.
Die Resultate sind in den Säulendiagrammen Abb. 7, 8 und 9 dargestellt.
Abbildung 7: Vergleich der Sterbefälle „an oder mit“ Corona mit den in 2020 unter den Infizierten aufgrund des allgemeinen altersbezogenen Sterberisikos statistisch zu erwarten gewesenen Todesfällen. Graue Säulen: „an oder mit“ Corona verstorben, wie vom RKI dokumentiert. Grün: statistischer Erwartungswert der Todesfälle p.a. unter den positiv Getesteten. Orange: verbleibende Todesfälle nach Abzug des Erwartungswerts, die man im statistischen Abgleich als Corona-bedingte Sterbefälle werten kann. Nur die Letzteren sind zusätzliche Todesfälle. In den Altersgruppen unter 60 liegt der statistische Erwartungswert über der Anzahl der registrierten Corona-Sterbefälle. Bei den Über-60-Jährigen verbleiben nach Abzug der erwarteten Todesfälle je nach Altersgruppe 1000 bis 9.000 Fälle, die man im Hinblick auf das allgemeine Sterberisiko statistisch Corona zurechnen kann. Rohdaten: RKI, Datenstand: 22.01.2022.
Abbildung 8: Vergleich der Sterbefälle „an oder mit“ Corona mit den in 2021 unter den Infizierten aufgrund des allgemeinen altersbezogenen Sterberisikos statistisch zu erwarten gewesenen Todesfällen. Graue Säulen: „an oder mit“ Corona verstorben, wie vom RKI dokumentiert. Grün: statistischer Erwartungswert der Todesfälle p.a. unter den positiv Getesteten. Orange: verbleibende Todesfälle nach Abzug des Erwartungswerts, die man im statistischen Abgleich als Corona-bedingte Sterbefälle werten kann. Nur die Letzteren sind zusätzliche Todesfälle. In den Altersgruppen unter 60 liegt der statistische Erwartungswert über der Anzahl der registrierten Corona-Sterbefälle. Bei den Über-60-Jährigen verbleiben nach Abzug der erwarteten Todesfälle je nach Altersgruppe knapp 1000 bis zu 12.000 Fälle, die man im Hinblick auf das allgemeine Sterberisiko statistisch Corona zurechnen kann. Rohdaten: RKI, Datenstand: 22.01.2022.
Abbildung 9: Vergleich der Sterbefälle „an oder mit“ Corona in 2020, 2021 und insgesamt mit den unter den Infizierten aufgrund des allgemeinen altersbezogenen Sterberisikos statistisch zu erwarten gewesenen Todesfällen. In beiden Jahren liegt der statistische Erwartungswert der Todesfälle unter der Anzahl der registrierten Corona-Sterbefälle. Nach Abzug der erwarteten Todesfälle verbleiben in 2020 etwa 15.000 und in 2021 etwa 23.000 Fälle, die man im Hinblick auf das allgemeine Sterberisiko statistisch Corona zurechnen kann. Für beide Jahre zusammen sind das in Summe 38.000 Todesfälle. Rohdaten: RKI, Datenstand: 22.01.2022.
Vermöge der vorstehenden Diagramme wird selbstredend nicht belegt oder gar bewiesen, die Anzahl der Coronatoten belaufe sich über beide Jahre tatsächlich nur auf 38.000 statt knapp 114.000. Die Todeskausalität ist – bis auf die wenigen Fälle, in denen sie mittels einer pathologischen Untersuchung zweifelsfrei bestimmt wurde – im Allgemeinen als offen anzusehen. Deswegen muss man auch korrekterweise immer den Zusatz „an oder mit“ davorsetzen. Aus der statistischen Analyse ergibt sich allerdings schon, dass die Zweifel an der hohen Gesamtanzahl der Corona zugerechneten Sterbefälle durchaus berechtigt sind. Zumindest kann man folgendes festhalten:
In 2020 wären etwa 30.000 der insgesamt 44.012 „an oder mit“ Corona im Laufe des Jahres Verstorbenen aufgrund der altersbedingten allgemeinen Sterblichkeit der Infizierten im statistischen Mittel auch ohne die Corona-Infektion verstorben (genauer, innerhalb von 12 Monaten nach dem Positivtest). Nur etwa 32 % der offiziell als Coronatote gezählten Sterbefälle (15.000) sind damit aus statistischer Sicht als zusätzliche Todesfälle zu werten. Das deckt sich im Übrigen mit der rechnerisch bestimmten Übersterblichkeit für 2021, die im Bereich von etwa 1,5 % – 2 % aller Sterbefälle, also bei knapp 20.000 liegt.
In 2021 wären etwa 49.000 der insgesamt 69.810 „an oder mit“ Corona im Laufe des Jahres Verstorbenen aufgrund der altersbedingten allgemeinen Sterblichkeit der Infizierten im statistischen Mittel auch ohne die Corona-Infektion verstorben (genauer, innerhalb von 12 Monaten nach dem Positivtest). Nur etwa 30 % der offiziell als Coronatote gezählten Sterbefälle (23.000) sind damit aus statistischer Sicht als zusätzliche Todesfälle zu werten. Das deckt sich auch hier mit der rechnerisch bestimmten Übersterblichkeit für 2021, die im Bereich von etwa 2 % aller Sterbefälle, also bei etwa 20.000 Toten liegt.
In der Gesamtschau zur Pandemie wären damit etwa 79.000 der insgesamt knapp 114.000 „an oder mit“ Corona Verstorbenen aufgrund der altersbedingten allgemeinen Sterblichkeit der positiv Getesteten im statistischen Mittel auch ohne die Corona-Infektion innerhalb einer Zeitspanne von 12 Monaten nach dem Positivtest verstorben. Nur etwa 31 % der offiziell als Coronatote gezählten Sterbefälle (38.000) sind somit aus statistischer Sicht als zusätzliche Todesfälle zu werten. Diese Zahl spiegelt die durch Corona verursachte rechnerische Übersterblichkeit in Höhe von etwa 2 % wider.
Der vorstehend zusammengefasste Befund ist das Resultat der mit zunehmendem Alter ab etwa 60 bis 70 stark anwachsenden mittleren Sterblichkeit. Das allgemeine Sterberisiko steigt mit dem Alter exponentiell, ähnlich wie auch die Corona-Letalität und die Corona-Mortalität. Daher bleibt es nicht aus, dass in der statistischen Vergleichsbetrachtung insbesondere eine große Anzahl der Älteren auch ohne Corona in der definierten Zeitspanne verstorben wäre. Völlig anders würde sich die Situation darstellen, falls die Corona-Sterblichkeit Jüngere in ähnlicher Weise wie Ältere betreffen würde. Wenn wir für einen Augenblick annehmen, die Corona zugeschrieben Todesfälle würden sämtlich in der Altersgruppe unter 60 aufgetreten sein, dann würde die vorstehende statistische Analyse zum Resultat geführt haben, dass 92 % der Fälle, also über 100.000, als zusätzliche und somit mit hoher Wahrscheinlichkeit auf Corona zurückzuführende Sterbefälle zu werten seien.
Gelegentlich wird gegen die obige Argumentation ins Feld geführt, viele der Coronatoten, auch die Älteren, hätten noch eine Lebenserwartung von mehreren Jahren gehabt und seien daher definitiv „an“ und nicht nur „mit“ Corona verstorben. In dieser Pauschalität ist das Unfug, wie man ganz leicht zeigen kann. Es liegt im Wesen einer statistischen Überlegung, nicht vom Einzelfall, sondern von der großen Zahl auszugehen. Betrachten wir exemplarisch die 80-Jährigen. Ihre statistische Lebenserwartung beläuft sich auf ca. 8 Jahre. Das Risiko, in den nächsten 12 Monaten zu versterben liegt aber im Schnitt dennoch bei 5,5 %. Sofern nun eine Person „an oder mit“ Corona verstirbt, scheinen damit zunächst 8 potentielle Lebensjahre vernichtet. Im Einzelfall könnte das auch zutreffen, unter statistischen Gesichtspunkten (also der Heranziehung der großen Zahl) erweist sich dieser Schluss indes als Fehlurteil.
Von 1000 Achtzigjährigen sterben 55 in der statistischen Erwartung innerhalb eines Jahres. Da hilft der Verweis auf die Restlebenserwartung von 8 Jahren nicht weiter. Die Restlebenserwartung ist keinesfalls garantiert, sie ist lediglich eine statistische Kenngröße, genau wie das Sterberisiko. Tatsächlich stehen nicht alle Todesfälle bei 80-Jährigen im Zusammenhang mit Corona, es ist nur etwa jeder zwanzigste Fall. Deswegen ist der Hinweis auf 8 vernichtete Lebensjahre völlig aus der Luft gegriffen. Statistisch darf man allenfalls von einem im Mittel um einige Monate verfrühten Ableben sprechen.
In Summe ist es deswegen eine absolut zulässige Betrachtung, die Corona-Todesfälle im Hinblick auf die bestehende allgemeine Sterbewahrscheinlichkeit zu bewerten. Wie bereits erwähnt, verfährt man im Übrigen betreffend der Verdachtsfälle von Impfungen mit tödlichem Ausgang seitens des PEI in analoger Weise.
Frage eines besorgten Lesers: Sahra Wagenknecht, Joshua Kimmich und viele andere Ungeimpfte schenken offenbar den Fake News und somit dubiosen Wissenschaftlern mehr Glauben als den Studien renommierter Wissenschaftler. Wie kann man als Laie wissenschaftliche Wahrheit und Fake News erkennen und wie kann man mehr seriöse Infos und so mehr Vertrauen erhalten?
Eine berechtigte Frage: Wie kann man als Laie seriöse wissenschaftliche Informationen von Falschinformationen unterscheiden?
Der Leser garniert die Frage mit seiner Einschätzung zur Urteilsfähigkeit von z.B. Sahra Wagenknecht und vermutet offenbar, dass sie die fragliche Unterscheidung nicht zu treffen in der Lage sei. Nun, es gibt wohl keinen Anlass, am intellektuellen Durchblick von Sahra Wagenknecht zu zweifeln. Von daher darf man darauf vertrauen, dass sie im Allgemeinen durchaus befähigt ist, wissenschaftliche Wahrheit und Falschinformationen, also Fake News, voneinander zu scheiden.
Eine kurze Antwort
Als kürzest mögliche Antwort könnte man dem Leser zurufen: Fragen Sie Frau Wagenknecht, sie weiß, wie es geht.
Das wird den Leser wahrscheinlich nicht zufriedenstellen, deswegen hat er sich ja auch an Prof. Reichl gewandt. Ob er indessen mit der Antwort von Prof. Reichl glücklich wird, ob er überhaupt etwas damit anfangen kann, das darf man mit guten Gründen bezweifeln.
Die Antwort des Experten
Was Prof. Reichl zur Antwort gibt (s. u.), ist zweifellos nicht falsch. Es ist eine ebenso seriöse wie wahre Information. Auf jeden Fall ist es definitiv keine Falschinformation. Aber hilft das wirklich weiter? Ich denke, nein.
Anmerkung: Die angegebenen 94 für den h-Wert bei Drosten sind zu hoch gegriffen, nach anderen Quellen liegt der Wert bei 71. Die genaue Zahl ist hier indes irrelevant, weil es nur ums Prinzip geht.
Wahrheit messen
Das Problem ist doch, dass sich „Wahrheit“ nicht einfach, wie die Höhe eines Turms oder die Temperatur kochenden Wassers messen lässt. Auch Seriosität oder Vertrauenswürdigkeit entziehen sich einem derart simplen Messvorgang. Zunächst einmal klingt es vernünftig, dass Wissenschaftler mit einen hohen h-Index (also einer großen wissenschaftlichen Reichweite gepaart mit entsprechender Anerkennung in Fachkreisen) auch seriöse Erkenntnisse erzielen und daher als vertrauenswürdig anzusehen sind.
Prof. Reichl nennt hier beispielsweise Albert Einstein und Stephen Hawking mit h-Indizes von 40 bzw. 75. Klar, das sind anerkannte Geistesgrößen, über deren wissenschaftliche Glaubwürdigkeit man nicht ernsthaft ins Grübeln kommen wird. Als exakte Naturwissenschaft spielt die Physik, zumal die theoretische Physik, indessen in einer anderen Liga als die Medizin bzw. die Virologie oder Epidemiologie. Im weitesten Sinne handelt es sich hierbei um Humanwissenschaften insofern der Mensch als Forschungsgegenstand im Zentrum steht. Das ist nicht unwichtig, weil hierdurch der wissenschaftlichen Methodik enge Grenzen gesetzt werden. Die erzielten Forschungsergebnisse haben vielfach einen eher unscharfen Charakter. Nicht selten kommen unterschiedliche Studien zum selben Thema zu abweichenden Ergebnissen, manchmal gar zu konträren.
Hinzu kommt, dass sich medizinische Forschung fast immer im Spannungsfeld zwischen reiner Wissenschaft und den Interessen der Pharmaindustrie bewegt. Interessenskonflikte sind weder ausgeschlossen noch selten. Und sei es nur, dass „ungünstige“ Forschungsergebnisse aus Opportunitätsgründen nicht veröffentlicht werden. Jedenfalls wird man z.B. die Medizin nicht als exakte Wissenschaft im engeren Sinne bezeichnen können. Dieser Befund hat Folgen auf die Verlässlichkeit und Tragfähigkeit der kommunizierten Wissensstände. Zumindest sind eine gewisse Skepsis und höhere Wachsamkeit stets angebracht, vor allem dann, wenn finanzielle Interessen dahinter vermutet werden können.
Wahrheit in Zeiten der Pandemie
Nun ging die Frage des Lesers ganz klar in Richtung Corona. Auch hier nennt Prof. Reichl einige Beispiele: Namhafte Virologen haben einen aktuellen h-lndex von 15 (Kekulé), 71 (Drosten) oder 178 (Fauci).
An dieser Stelle fragt man sich, wie das zu bewerten sei? Ist der amerikanische Epidemiologe und Präsidentenberater Fauci glaubwürdiger als Drosten? Und dieser wiederum glaubwürdiger als Kekulé? Da beschleichen einen doch leichte Zweifel, ob daraus bereits ein tragfähiger Ansatz zur Unterscheidung von seriösen wissenschaftlichen Informationen (also wissenschaftlicher Wahrheit) und Falschinformationen, vulgo Fake News, erwachsen könne. Die Zweifel werden genährt durch die folgende Beobachtung: John P. A. Ioannidis, seines Zeichens Professor an der Stanford University und vielfach ausgezeichneter Wissenschaftler, hat einen h-index von (sagenhaften) 204. Zugleich ist er der weltweit prominenteste sogenannte „Corona-Leugner“. Üblicherweise wird Prof. Sucharit Bhakdi, mit einem h-index von immerhin 69, ebenfalls zu den Corona-Leugnern gezählt.
Kein Corona-Leugner, aber ein in kritischer Distanz stehender Virologe ist Prof. Hendrik Streeck mit einem h-index von 40. Angesichts seines fast noch jugendlichen Alters steht dieser Wert gleichfalls für ein sehr hohes Maß an wissenschaftlicher Reputation. Karl Lauterbach ist definitiv niemand, der Corona auf die leichte Schulter nimmt, er kommt aber „nur“ auf einen h-index von 23. Immerhin, mag man konstatieren. Natürlich hatten die wenigsten der Publikationen etwas mit dem Corona-Virus oder den praktischen Auswirkungen in der Corona-Pandemie zu tun. Doch dies steht auf einem anderen Blatt.
Was tun, wenn es vermeintlich viele Wahrheiten gibt?
Soll nun der Leser Studienergebnisse, Interviews im Fernsehen oder die Aussagen in Talkrunden stets mit dem Blick auf den h-Index bewerten? Lauterbach (23) sagt „Schulen schließen“, Kekulé (14) hält dagegen „Schulen offenhalten“. Wer hat Recht? Natürlich Lauterbach, er hat ja den höheren h-Index (weil Kekulé einfach zu wenig publiziert hat). Und wenn am nächsten Sonntag Drosten (71) doch für den regulären Schulbetrieb eintritt? Was soll man dann tun? Öffnen natürlich, es sei denn, Fauci (178) warnt davor. Warum also nicht gleich Ioannidis (204) einladen? Wenn er sich zu Wort meldet, dann müssen alle anderen verstummen. Und wahrscheinlich empfiehlt er die sofortige Beendigung aller Corona-Maßnahmen.
So wird das also nicht funktionieren. Aus einem weiteren Grunde geht es nicht: Die allermeisten wissenschaftlichen Erkenntnisse zu Corona werden eben nicht von einer elitären Gruppe national oder gar weltweit bekannter Wissenschaftler erarbeitet. Es sind vielmehr die namenlosen, meist am Beginn ihrer wissenschaftlichen Karriere stehenden Forscher. Die Mehrzahl von ihnen mit einem einstelligen h-index.
Wissenschaftliche Wahrheit vs. praktische Erfahrung
Sollte man vielleicht eher Experten mit praktischer Erfahrung zu Rate ziehen? Die meisten von ihnen werden einen h-Index nahe Null haben, was indessen nur besagt, dass sie nicht oder kaum in der theoretischen Pandemiebekämpfung tätig waren. Dafür haben sie Erfahrung und wissen, was praktisch umsetzbar ist und wirkt. Natürlich braucht man auch die wissenschaftlichen Begleitstudien. Und selbstverständlich muss man voraussetzen, dass diese Studien wissenschaftlich korrekt durchgeführt und dabei Ergebnisse mit praktischer Relevanz erzielt werden. Der h-Index der Durchführenden hilft dabei aber nur bedingt weiter.
In Wahrheit geht es in der Praxis weniger um die Details in dieser oder jener Studie. Viel wichtiger ist die Einordnung der erzielten Ergebnisse im praktischen Kontext. Oft ist das die größere Herausforderung. Nicht die manchmal banalen Fakten aus den Studien sind entscheidend, sondern ihre Interpretation im Hinblick auf die abzuleitenden Schlussfolgerungen für die Praxis.
Was sind Fake News?
An dieser Stelle ist der richtige Platz, mit einem Missverständnis zu den sogenannten Fake News aufzuräumen. Was sind eigentlich Fake News?
Eine Falschinformation liegt dann vor, wenn ein Tatbestand, also eine objektiv bestehende Tatsache, ein im Grundsatz beweisbarer oder faktisch bewiesener Sachverhalt falsch oder die Wahrheit entstellend wiedergegeben wird. Dabei handelt es sich nicht zwangsläufig und eine „Lüge“. Wer die Unwahrheit sagt, ohne dass er sich dessen bewusst ist oder vielleicht sogar im Glauben, es handelt sich um die Wahrheit, dem kann man nicht vorwerfen, er täusche oder fälsche. Hier geht es um den Irrtum. Was nichts daran ändert, dass die getroffene Aussage in einem solchen Fall unwahr ist.
Von der (bewussten oder unbewussten) Falschdarstellung streng unterscheiden muss man bloße Meinungen. Dazu später, zunächst soll es um die absichtliche Falschinformation gehen.
Verzerrung der Wahrheit
Noch nie konnten sich Fake News so schnell und effizient verbreiten. Ein „Erfolg“ der sozialen Medien. Was früher am Stammtisch gemutmaßt und alsbald wieder in der Versenkung verschwand, das wird heute in Windeseile um den Globus geschickt, modifiziert, zurückgespiegelt und sich selbstverstärkend als vermeintliche „geheime“ Wahrheit, vulgo Verschwörungstheorie, verbreitet.
Beispiele für klassische Verschwörungstheorien sind:
Die Amerikaner waren gar nicht auf dem Mond. Was man als Beweis für die Mondlandung im Fernsehen gesehen hat, das waren gestellte Filmaufnahmen aus Hollywood.
Die Anschläge auf das World Trade Center in 2001 waren in Wirklichkeit vom CIA inszeniert.
Bill Gates will mit einem weltweit verfolgten Impfprogramm den Menschen winzige Computer-Chips implantieren. Es ist sein Ziel, die Menschheit zu manipulieren.
Natürlich kann man solche Aussagen nicht beweisen, sonst wären es ja keine Verschwörungstheorien.
Man sieht an diesen typischen Beispielen, dass sich die von sogenannten Verschwörungstheoretikern verbreiteten Fakes mit einem Minimum an kritischem Verstand als Falschinformationen und Unwahrheiten erkennen lassen. Solche Theorien sind eher amüsant als gefährlich. Eine Gefahr für die Allgemeinheit geht davon jedenfalls kaum aus.
Viel mühsamer als unrichtig zu identifizieren sind die von vermeintlich berufener Seite vorgetragenen Halbwahrheiten. Wenn sie von einer Institution stammen, der man grundsätzlich eine gewisse Glaubwürdigkeit beimisst, dann ist die Gefahr groß, potentiell einer Falschinformation aufzusitzen. Dies gilt insbesondere in dem Fall, wenn Teile der Aussage zutreffen. Dann ist es umso schwerer, die darin verpackte Unwahrheit auszumachen. Solche Fälle sind auch in der Medienberichterstattung nicht ausgeschlossen. Natürlich ist man geneigt, das, was man in der Zeitung liest und in den Rundfunk- oder Fernsehnachrichten hört, ungeprüft für bare Münze zu halten. Mehr noch, wenn solche Informationen von staatlichen Behörden stammen. Aber auch hier muss man wachsam bleiben.
Ein Beispiel zum Themenkreis Falschinformation, Verzerrung der Wahrheit, Interesse und Manipulation: Im Herbst 2021 wurden über viele Wochen hinweg die offiziell ausgewiesenen Corona- Infektionszahlen für Ungeimpfte von staatlichen Stellen mehr oder weniger absichtsvoll künstlich in die Höhe getrieben. Im Ergebnis waren die veröffentlichten Inzidenzen für Ungeimpfte teilweise 10-mal höher als die der Geimpften. Die allermeisten Medien haben brav darüber berichtet und die Botschaft verstärkt. Man hat dabei bewusst die Infektionsfälle mit unbekanntem Impfstatus – und das war die große Mehrheit, weil der Impfstatus nicht konsequent erfasst wurde (und noch immer nicht strikt erfasst wird) – den Ungeimpften zugeschlagen. Das alles wohl in der „guten“ Absicht, damit die Leute zum Impfen zu bewegen.
In die gleiche Richtung geht die generell schlampige oder vielleicht auch vorsätzlich falsche Datenerfassung in Deutschland, die offenbar darauf ausgerichtet ist, die Situation dramatischer darzustellen, als sie tatsächlich ist. Hospitalisierungsraten werden künstlich erhöht, indem jeder eingelieferte Patient mit positivem Test als Corona-Fall gelistet wird, auch wenn er völlig ohne Symptome ist und eigentlich wegen einer Augen-OP ins Krankenhaus gekommen war. Es ist beschämend, dass wir in Deutschland offensichtlich nicht in der Lage sind, die relevanten Daten verlässlich zu erheben, sie vernünftig zu interpretieren und daraus zutreffende Schlüsse zu ziehen.
Impfquoten, Impfwirkung, Wirkungsdauer, Ansteckungsrisiko, Inzidenzen, Hospitalisierung, Todesfälle betreffend Geimpften und Ungeimpften, usw., werden entweder überhaupt nicht oder nicht genau erfasst, manchmal auch nur geschätzt. Wir haben keine Ahnung, wieviel Millionen tatsächlich schon infiziert waren. … Jeder seriös arbeitende Statistiker und Analyst muss daran verzweifeln. Tatsächlich fehlt uns für eine ernsthafte und wissenschaftlich fundierte Strategie in der Pandemie schlichtweg die Datengrundlage.
Apropos Impfen: Natürlich hat die Impfkampagne Menschenleben gerettet, vor allem unter den Älteren. Nach allem, was wir wissen, werden durch die Impfung schwere Krankheitsverläufe viel unwahrscheinlicher. Die Impfung sorgt also für einen hohen Eigenschutz. Den maximalen Nutzen davon haben diejenigen, die das größte Corona-Risiko tragen, also die Älteren. Muss man angesichts dessen nicht applaudieren, wenn Pharmakonzerne subtile Lobbyarbeit für eine Impfpflicht machen? Muss man Ihnen denn nicht glauben, dass sie nur das Beste wollen?
Nein, das muss man nicht, das darf man nicht. Die Pharmakonzerne vertreten ihre eigenen wirtschaftlichen Belange, nicht die Interessen der Menschen. Es geht hier um Milliardengeschäfte. Umso mehr gilt es, das Gesagte auf den Prüfstand zu stellen und nicht einfach so hinzunehmen.
Das Interesse dessen, der eine Aussage tätigt, seien es wirtschaftliche oder weltanschauliche, steht der Wahrheit nicht selten im Wege und gibt immer wieder Anlass zu Fake News oder Halbwahrheiten. Frei nach dem französischen Mathematiker und Philosophen Blaise Pascal kann man dies folgendermaßen zusammenfassen:
„Nie sagt der Mensch so überzeugt die Unwahrheit, als wenn er es mit gutem Gewissen tut.“
Fake News vs. „falsche“ Meinungen
Nehmen wir ein Beispiel mit Bezug auf Corona: Wenn das RKI meldet, per 30.09.2021 seien 107.888.714 Impfungen durchgeführt worden, dann darf man das für wahr halten (auch wenn man es nicht nachprüfen kann). Sofern nun jemand behauptet, es seien tatsächlich nur 70 Mio., Dosen verabreicht worden, so ist das wohl eine Falschinformation, die man mit Verweis auf die Zahlenangabe des RKI richtigstellen kann.
Viel schwieriger ist es bei Meinungen. Wobei es nicht immer leicht fällt, zwischen Meinung und Tatsache klar zu unterscheiden. Wenn z.B. die Ständige Impfkommission (Stiko) die Impfung mit Spikevax für Personen ab 18 Jahren empfiehlt, dann ist diese Empfehlung zunächst einmal eine Tatsache. Sofern weiter ausgeführt wird, das Risiko von Nebenwirklungen sei gering, dann ist dies allerdings eine Meinung. Es ist die profunde und fachliche abgesicherte Bewertung der zuständigen Kommission. Es ist aber keine Tatsache, weil es der Einschätzung des Einzelnen unterliegt, inwiefern ein Risiko bestimmter Höhe in der persönlichen Perspektive noch als gering oder schon als zu hoch erachtet wird.
Sofern also ein Impfskeptiker postet, das Risiko von Nebenwirkungen sei bei Spikevax hoch, dann ist das keine Falschinformation, sondern eine Meinung. Seine persönliche Meinung. Böswillig könnte man sagen, seine persönliche „falsche“ Meinung. Indessen gibt es keine falschen Meinungen. Meinungen sind frei und unterliegen – jenseits des allgemein akzeptierten Wertekanons – keiner inhaltlichen Qualitätskontrolle.
Die Mehrzahl dessen, was täglich in den sozialen Netzen kommuniziert wird, sind Meinungen und keine Fakten. Sogar in den Medien nehmen die Meinungsbeiträge einen immer größeren Raum ein. Eine beliebte Methode zur Tarnung von Meinungen als Fakten ist dabei die Verwendung von geeigneten Statistiken. Je nachdem, was man mitteilt und weglässt, können dabei ganz unterschiedliche Bilder entstehen. Falschbehauptungen im engeren Sinne sind dafür gar nicht vonnöten. Die so oftmals in bester Absicht entstehenden vermeintlichen Fakten sind weder falsch noch wahr, und in gewisser Weise auch beides zugleich.
Tatsachen sind fix, Meinungen nicht
Im Unterschied zu Tatsachen sind Meinungen potentiell volatil. Was gestern noch für richtig erachtet wurde, kann heute in einem ganz anderen Licht erscheinen. Das gilt auch für wissenschaftliche Erkenntnisse, scheinbar festgefügte Lehrmeinungen und natürlich für Vorhersagen.
Und tatsächlich hat die Stiko nach mehreren Monaten der Impfung mit Spikevax per Ende Oktober ihre Empfehlung insofern revidiert, als dass Spikevax nun für junge Männer bis 30 nicht mehr angeraten wird, weil es eine neue Risikoeinschätzung gibt. Nicht die Zusammensetzung des Impfstoffs hat sich geändert, sondern die Haltung der Stiko dazu. Damit wird nochmals klar unterstrichen: Was die Stiko sagt, ist eine Meinung. Es handelt sich um die abgestimmte und profunde Einschätzung von fachkundigen Experten, aber nicht um einen unumstößlichen Tatbestand.
Man mag das Urteil der Stiko für gewichtiger halten als die persönliche Bewertung eines oder auch vieler Impfskeptiker oder unbedingten Impfbefürworter – und das ist es natürlich auch. Das ändert indessen nichts daran, dass es hier mitnichten um eine Tatsachenfeststellung geht. Und weil das so ist, kann es darüber auch keine Fake News geben (sofern man die Meinung der Stiko nicht verfälscht wiedergibt und diese falsche Version der Stiko zuschreibt).
Das gilt auch für die Feststellung des Paul-Ehrlich-Instituts (PEI), es gebe keine Langzeitwirkungen von Impfstoffen. Es konstatiert: Nebenwirkungen treten in zeitlicher Nähe zur Impfung auf, oder gar nicht. Das ist auch in diesem Falle die fachkundige Einschätzung von Experten und somit eine gewichtige Meinung. Es ist aber eben keine Tatsache.
Das Wirkprinzip von mRNA-Impfstoffen ist neu, deswegen kann man auch nachgelagerte oder indirekte Folgen auf das Immunsystem nicht mit Sicherheit ausschließen. Wer dies tut, verstößt gegen elementare wissenschaftliche Prinzipien und handelt unredlich. Analogieschlüsse aus den historischen Impfprogrammen sind nicht hinreichend für den Ausschluss von Langzeitfolgen, weil die Analogie aufgrund des neuartigen Wirkprinzips so nicht besteht.
Auch wenn man eine unmittelbare Gefahr mit größter Sicherheit ausschließen kann, da die Impfstoffe schon millionenfach verabreicht wurden (darauf fußt das Urteil des PEI), so gebietet die wissenschaftliche Skepsis im Verein mit der ärztlichen Vorsicht, solche vorschnellen Verharmlosungen zu unterlassen. Dies vor allem dann, wenn es um Impfprogramme für Kinder geht. Es besteht ein Restrisiko, über das man nichts Genaues weiß. Möglicherweise wird es sich als klein erweisen, das ist aber nicht gewiss. Wer das Risiko jetzt aus politischen Gründen kleinredet, ignoriert eherne wissenschaftliche Grundsätze und wird seiner Verantwortung nicht gerecht.
Natürlich kann man pragmatisch argumentieren, das bekannte von Corona ausgehende Risiko sei höher einzuschätzen als das unbekannte Restrisiko möglicher Spätfolgen. Das ist ein politisch opportuner Zugang, den man durchaus vertreten kann. Man muss ihn aber nicht zwingend gutheißen, weil ihm die wissenschaftliche Grundlage fehlt. Zumindest sollte, wer dies propagiert, sich nicht auf die Wissenschaft berufen. Es ist dennoch ein oft anzutreffendes Verhalten: Risiken, die man in Ermangelung verlässlicher Daten und gezielter Untersuchungen nicht quantifizieren kann, werden kurzerhand als nicht existent deklariert. Manchmal wird das sogar explizit als „wissenschaftlich“ ausgegeben – tatsächlich ist es nicht mehr als Augenwischerei.
Kurzum: Der Ausschluss möglicher Langzeitfolgen ist wissenschaftlich nicht hinreichend begründet. Und wenn nun sogar Journalisten in den Medien diese eher skeptische Haltung rundweg als wissenschaftsfeindlich diskreditieren, dann muss man leider festhalten, dass es um die kritische Vernunft der Presse und der öffentlich-rechtlichen Sender offenbar nicht gut bestellt ist.
Fake News detektieren
Die Hürde für Fake News ist nach dem Vorstehenden nicht einmal niedrig, denn bei den allermeisten Informationen die täglich auf uns einströmen sind Fakten und Meinungen eng miteinander verwoben. Wenn man sich in den sozialen Medien umschaut, könnte man den Eindruck gewinnen, es gebe viele und täglich eine größere Anzahl an „gefälschten Nachrichten“. Zum großen Teil ist das aber ein trügerischer Eindruck. Das meiste davon sind lediglich Meinungen, keine verdrehten Tatsachen. Häufig werden sie indessen nicht als abweichende Meinungen, sondern als falsche Tatsachenbehauptungen verstanden.
Bei den bloßen Fakten lassen sich die Fake News meist leicht ausmachen. Mittlerweile gibt es auch eine Reihe von Internetseiten (z.B. Correctiv, Volksverpetzer), die Fake News mit großem Engagement aufspüren und dokumentieren. Das kann man machen, ein Mehrwert entsteht aber nur selten. Meist handelt es sich um Banalitäten, die sich schon beim ersten kritischen Blick als Falschinformationen entlarven. Vielfach sind sie so abstrus, dass es der Mühe gar nicht wert ist, genauer nachzuforschen.
Das Grundproblem ist: Oft wird in Meldungen und Postings nicht strikt zwischen Fakten und Meinungen unterschieden und vielen fällt es auch schwer, überhaupt diese Unterscheidung zu treffen.
Wahre Meinungen
Wie groß ist die von Corona ausgehende Gefahr? Droht der Menschheit der Untergang, wenn sie nicht drastische Maßnahmen ergreift? Oder ist es nur eine besonders schwere Grippewelle, wie die sogenannten Corona-Leugner das meinen? Die Fragen können und sollen an dieser Stelle nicht endgültig geklärt werden, wir wollen nur zeigen, wie hier Fakten und Meinungen ineinandergreifen.
Das Corona-Sterberisiko (Mortalität p.a.) liegt in der Altersgruppe 20-29 bei 0,001%, bei den 80-89-Jährigen beläuft sich das Risiko dagegen auf 0,5%. Das sind die objektiven Tatsachen, wie sie sich aus den betreffenden vom RKI publizierten Todesfallzahlen („an oder mit“-Corona verstorben) unmittelbar ergeben. Man darf also sagen, das sind Fakten. Oder, noch pointierter: Das ist die Wahrheit. Mögliche Zweifel an der Todeskausalität bei einem Teil dieser Fälle wollen wir bewusst ausklammern.
Die beiden genannten Zahlen repräsentieren also bezüglich der von Corona ausgehenden Gefahr eine wesentliche Einsicht: Junge Menschen sind kaum betroffen, Alte sind sehr viel stärker gefährdet. Nun haben alte Menschen generell ein höheres Sterberisiko. In der Mitte der 80er-Lebensjahre (was ja schon mehr ist als die mittlere Lebenserwartung) liegt es in etwa bei 10% p.a. Ein zwanzigstel dieses Risikos ist daher Corona zuzuschreiben. Wobei dies natürlich von vielen Einzelfaktoren, wie Vorerkrankungen, allgemeiner Gesundheitszustand und Lebensumständen, wie z.B. Heimunterbringung abhängig ist. Ob man das Risiko für hoch oder gering hält, entzieht sich indes der objektiven Bewertung.
Für 25-Jährige liegt das allgemeine Sterberisiko ohne Corona bei etwa 0,05%. Bei jenen macht das zusätzliche Corona-Risiko also nur etwa ein fünfzigstel ihres ohnehin geringen Sterberisikos aus. Auch hier kann man nicht objektiv sagen, das sei viel oder wenig. Was man sagen kann, ist dies: Die absolute von Corona ausgehende Gefahr ist für die Älteren 500-mal höher, was sich auch in der Verteilung der Todesfallzahlen entsprechend niederschlägt.
Das soll zeigen: Objektive Tatsachen sind immer nur der Ausgangspunkt. Das Entscheidende ist die Interpretation der Tatsachen. Dabei handelt es sich nicht mehr um Wahrheit, sondern um Meinung. Gleichviel, welche und wie viele Gründe man anführt, es bleibt eine bloße Meinung. Eine begründete Meinung zwar, aber dennoch keine unumstößliche Wahrheit. Man kann die Tatsachen auch anders interpretieren und daraufhin zu anderen Schlüssen kommen. Im konkreten Fall könnte man andere Corona-Maßnahmen ergreifen, z.B. solche, die weniger einschneidend wirken und mit geringeren Nebenwirkungen einhergehen. Damit leugnet man nicht die Tatsachen, man entscheidet sich vielmehr für eine andere Sicht der Dinge. Und das ist fast immer eine Option.
Die Frage nach der Wahrheit
Kehren wir zurück zum Kern der Frage des Lesers: Wie kann man als Laie seriöse wissenschaftliche Informationen von Falschinformationen unterscheiden?
Es ist eine schwierige Frage! Die ehrliche Antwort ist: Für den Laien gibt es keinen einfachen und sicheren Weg der Unterscheidung. Ja noch nicht einmal Fachleute und ausgewiesene Experten sind vor Irrtümern gefeit. Es gibt aber immerhin einige Grundregeln, die einem dabei helfen, Falschinformationen zu erkennen. Genaugenommen sind es keine Regeln, es ist vielmehr eine kritische Grundhaltung.
Kritikfähigkeit
Die grundsätzliche wissenschaftliche Herangehensweise ist die, den naheliegenden Erklärungen und den blanken Zahlen – vermeintlich also Tatsachen – nicht blind zu vertrauen. Oftmals sind die Zusammenhänge komplexer, als es sich auf den ersten Augenschein hin darstellt. Problematische Abhängigkeiten, versteckte Wechselbeziehungen oder unklare Zuordnungen stehen der tieferen Erkenntnis nicht selten im Wege. Es ist daher unwissenschaftlich, die eigene Argumentation auf einer vordergründigen und damit ungesicherten Grundlage aufzubauen. Das gilt nicht nur für Wissenschaftler. Der Pflicht zur kritischen Auseinandersetzung unterliegt jeder Einzelne.
Einfach strukturierte Menschen ignorieren die Komplexität der Wechselbeziehungen und suchen nach simplen Erklärungen. Meist entsteht so ein unterkomplexes Bild der Realität. An die Stelle der nichtverstandenen Abhängigkeiten werden Feindbilder gesetzt: Bill Gates will uns alle einen Chip implantieren und uns abhängig machen, die Regierung verfolgt einen geheimen Plan zur Abschaffung der Demokratie, die Bevölkerung soll ausgetauscht werden … und was da sonst noch an skurrilen Konstrukten ins Feld geführt wird. Hinsichtlich Corona haben sich einige besonders hartgesottene und geistig offenbar arg limitierte Gegner der politischen Maßnahmen zur Eindämmung der Pandemie in diesem selbstgeschaffenen Dickicht von abstrusen Überzeugungen verlaufen. – Doch ganz so einfach ist es nicht.
Die große Mehrheit der Menschen neigt nicht zu solch abwegigen Theorien und verlässt sich lieber auf die Ansagen der Politiker und die tägliche Medienberichterstattung. Dort kommen ausgewiesene Experten zu Wort, womit sichergestellt wird, dass auch die wissenschaftliche Sicht Berücksichtigung findet. – Ist also das, was über die Medien verbreitet wird nicht per se vertrauenswürdig, ja sogar rundweg richtig und alternativlos? Ist es nicht abwegig, wissenschaftliche Aussagen zu bezweifeln oder politischen Maßnahmen und Entscheidungen zu misstrauen? So sieht es wohl die überwiegende Mehrzahl der Menschen. Dazu gehören auch die Medienschaffenden, die – ungewöhnlich genug – sich in dieser Sache, wie es scheint, bedingungslos auf die Seite der Regierung geschlagen haben. Vielleicht auch deswegen, weil man sich mit Corona-Leugnern wie Trump und Bolsonaro oder auch Johnson nicht gemein machen will.
Im ersten Impuls ist man geneigt, dem beizupflichten. Bei genauerem Hinsehen kommen dann allerdings Zweifel. Aus mehreren Gründen: Die Fakten sind keineswegs so klar und eindeutig, wie das in den Medien und von Politikern dargestellt wird. Auch seitens der Wissenschaft gibt es, wenn auch nur vereinzelt, abweichende Meinungen. Es fällt auf, dass in der Kommunikation nicht an den kritischen Verstand appelliert wird, man schürt vielmehr Angst und Panik und spricht mit erwachsenen Bürgern wie mit Kindern. Die Bedrohung durch Corona wird einseitig und überhöht dargestellt. Nahezu alle anderen Probleme werden als nachrangig behandelt. Zahlen werden manipuliert.
Um es deutlich zu sagen: dahinter steckt keine Verschwörung. Es ist wohl einfach die Unfähigkeit, in der komplexen Situation anders zu agieren, als man das gewohnt ist. Drastischer hat es Helmut Schmidt formuliert: „Die Dummheit von Regierungen sollte niemals unterschätzt werden„. Das kann man so stehenlassen.
Anders als dies von Politikern und Medien dargestellt wird, besteht die Pandemiepolitik zu 90 % aus Aktionismus und Panikmache und nur zu 10% aus Wissenschaft (ganz unabhängig von dem dahinterstehenden ernstzunehmenden Anliegen des Gesundheitsschutzes).
Angesichts dessen ist es in einem demokratischen Staatswesen die erste Bürgerpflicht, die politisch verfügten Maßnahmen und die Medienberichterstattung kritisch zu hinterfragen. Dazu gehört, nicht alles ungeprüft für bare Münze zu nehmen. Auch nicht die Aussagen von vorselektierten Wissenschaftlern. Wissenschaft ist keine Religion und die kritischen Nachfragen sind kein Sakrileg. Sie gehören notwendigerweise zum Prozess des Erkenntnisgewinns – auf allen Seiten.
Vielfach läuft es indes genau umgekehrt. Skeptiker werden als Wissenschaftsleugner hingestellt, die Blindgläubigen und Vertrauensseligen gelten als im besten Sinne kritisch und wissenschaftlich orientiert. Das ist eine eigentlich überwunden geglaubte vor-aufklärerische Geisteshaltung. Warum diese im Kern unwissenschaftliche Einstellung reüssieren konnte, das hängt wohl mit der vielfach anzutreffenden Moralisierung von Sachfragen zusammen. Viele haben sich darin eingerichtet, die Welt unter dem Blickwinkel der moralisch „richtigen“ Fragen und Antworten zu deuten. Nicht mehr die kritische Vernunft soll den Weg zur Erkenntnis weisen, sondern die richtige Haltung.
Skepsis
Die Unterscheidung von Wahr und Falsch setzt auf jeden Fall ein gehöriges Maß an Skepsis voraus. Dazu gehört die Erkenntnis: Es gibt keine absoluten Wahrheiten. Zugegeben, ein paradoxes Statement, nimmt es doch für sich in Anspruch, eine gewissermaßen immer gültige Wahrheit auszudrücken. Um den Widerspruch aufzulösen, müssen wir die Aussage um den Zusatz, „man kann sich dessen nicht sicher sein“, ergänzen. Im verallgemeinerten Sinne soll damit die stets notwendige Skepsis auch dem eigenen Urteil gegenüber zum Ausdruck gebracht werden.
Die Skepsis ist der Gegenentwurf zum bloßen Glauben. Wolfgang Herles sagt dazu: „Erst das Hinterfragen – die Skepsis – beendete die Tyrannei des Glaubens.“ Es gibt keinen Wissenschaftler, keinen Philosophen, der nicht Skeptiker wäre. Ohne diese Skepsis würden wir vielleicht heute noch glauben, unser Schicksal sei von den Göttern bestimmt. Und ob es morgen regnet, das entscheidet der Wettergott.
Es liegt auf der Hand, dass Leichtgläubigkeit keine gute Ausgangsbasis für das Erkennen der Wahrheit ist. Allenfalls ist dieser Zugang bequem und spart Zeit und Mühe. Was aber nützt dies, wenn man so auf die falsche Fährte gerät. Denkfaulheit ist das Gegenteil von Kritikfähigkeit und Skepsis.
Nun mag man einwenden, manche Fragen seien so komplex, dass man ohne das Urteil Anderer kein schlüssiges Bild entwickeln könne. Vielfach kann man auch den nötigen Aufwand gar nicht treiben oder es fehlen einem wichtige Voraussetzungen. Das ist richtig. Dennoch entbindet das den kritischen Geist nicht von der inhaltlichen Auseinandersetzung. Auch komplexe Gedankengänge lassen sich nachvollziehen und sollten am Ende zumindest plausibel erscheinen.
Wahrheit steht für sich
Die Orientierung an so simplen Überzeugungen wie, „A hat es gesagt, deswegen ist es richtig“ oder „B hat es gesagt, deswegen ist es falsch“ ist ebenfalls keine verlässliche Grundlage. Diese Haltung ist eng verwandt mit der Leichtgläubigkeit. Man überlässt das Denken anderen, denen man per se eine absolute oder zumindest eine höhere Glaubwürdigkeit zugesteht. Oder es wird ihnen andersherum unterstellt, stets die Unwahrheit zu sagen.
Schade, das dürfte wohl für viele eine richtig schlechte Nachricht sein. Es wäre aber auch gar zu schön, wenn die Entscheidung zwischen Wahr und Falsch auf so einfacher Grundlage getroffen werden könnte. Nichtsdestotrotz ist genau diese Attitüde sehr weit verbreitet, und man kann durchaus den Eindruck gewinnen, dass sie im Zuge der bereits oben erwähnten Moralisierung von Sachfragen immer weiter um sich greift.
Kürzlich hat eine Gruppe von 400 Ärzten einen offenen Brief zu Corona verfasst, in dem die Spaltung der Gesellschaft in Ungeimpfte und Geimpfte angeprangert und die politischen Maßnahmen in Richtung einer Impfpflicht als ungerechtfertigt und ethisch nicht vertretbar bezeichnet werden. Im Brief werden eine Reihe von Tatsachen zu den objektiv von Corona ausgehenden Risiken genannt und es werden wissenschaftliche Studien zur Begründung der Position der Ärzte ins Feld geführt. Die Reaktionen darauf waren typisch: Auf der einen Seite eine kleinere Gruppe von Personen, die den Vorstoß dankbar begrüßten. Davon sicher viele, ohne sich mit dem Inhalt genau auseinandergesetzt zu haben. Auf der anderen Seite eine viel größere Gruppe, die den Brief radikal ablehnte. Offenbar vor allem deswegen, weil er ihrer Meinung entgegenstand.
Nun könnte man annehmen, dass man sich zunächst einmal mit dem Inhalt des Gesagten befasst, darin dann die eventuellen Argumentationsschwächen ausmacht und schließlich sachliche Kritik übt. Leider nichts davon. Da wird vor allem nach Informationen zu den Unterzeichnern gesucht. Und wenn einer davon fragwürdig ist (staatsanwaltschaftliche Ermittlungen aufgrund von Verstößen gegen Corona-Maßnahmen), dann ist damit das Urteil über den Brief sofort gefällt: Nicht glaubwürdig und damit auch nicht akzeptabel, weil der Inhalt von jemand gestützt wird, gegen den Ermittlungen laufen oder der als „verdächtig“ einzustufen ist. Genau das oben skizzierte Bild: B hat es gesagt, also ist es falsch. Inhaltliche Diskussionen erübrigen sich.
Gestützt wird diese Ablehnung im zweiten Schritt auch von „Faktencheckern“. Sie überfliegen den Inhalt und ziehen stante pede ein Resümee zu angeblichen Falschbehauptungen. Wenn man dann genauer nachforscht, dann sieht man, dass die Faktenchecker falsch liegen, weil sie den Inhalt nicht in der gebotenen Sorgfalt überprüft haben. Tatsächlich werden im Brief selbst nur zutreffende Fakten genannt. Den Unterzeichnern wirft man dennoch Falschinformationen vor, u.a. deswegen, weil man – wie oben erläutert – zwischen Meinung und Tatsachenbehauptung nicht klar unterscheidet. Richtig wäre es, den Brief als das zu debattieren, was er ist: Eine abweichende Meinung zu der von Corona ausgehenden Gefahr. Keine Falschbehauptung, sondern eine andere Meinung. Man muss diese Meinung nicht teilen, man kann sich aber mit ihr auseinandersetzen.
Nochmal: Es ist irrelevant, wer eine wahrheitsgemäße Aussage trifft. Der Wahrheitsgehalt einer Aussage ist unabhängig davon, wer sie tätigt. Wobei wir sophistische Konstruktionen außer Acht lassen wollen.
Wenn man Aussagen widerlegen will, dann muss man sich mit dem Inhalt befassen. Es reicht also auch im vorliegenden Fall nicht aus, die Unterzeichner des Briefs aus einer vorurteilsbehafteten Reflexhaltung heraus zu diskreditieren und damit vom Inhalt abzulenken. Genauso wie es auch umgekehrt noch nie ein Argument war, den Ex-Gesundheitsminister Spahn als Bankkaufmann und den RKI-Präsidenten Wieler als Veterinärmediziner abzukanzeln.
Beständigkeit wissenschaftlicher Aussagen
Es wurde oben schon darauf hingewiesen, dass wissenschaftliche Aussagen eigentlich fast immer einen unfertigen Charakter haben. Das gilt umso mehr, insofern die getroffenen Aussagen als neue Forschungsergebnisse daherkommen.
Nehmen wir wieder das Corona-Beispiel. Was Mediziner und Virologen bisher an vorläufigen Erkenntnissen gewonnen haben, kann den Status gesicherten Wissens (also im eigentlichen Sinne Wissenschaft) nicht für sich beanspruchen. Die Meinungsvielfalt ist ebenso groß wie die Studienaussagen widersprüchlich. Tatsächlich geht es hier (nicht in allen, aber in nennenswert vielen Fällen) um vorläufige Forschungsergebnisse, nicht um gesichertes Wissen und unverrückbare Wahrheiten.
Natürlich gibt es eine vorherrschende Meinung. Indessen geht es in der Wissenschaft nicht nach Mehrheiten. Vielmehr ist gerade die aus der Skepsis geborene abweichende Meinung die Triebfeder für den wissenschaftlichen Fortschritt. Dabei lebt der Fortschritt auch vom Irrtum. Davon haben wir im Laufe dieser Pandemie einiges gesehen. Und das ist absolut nicht ungewöhnlich, weil es im eigentlichen Sinne keine etablierte „Corona-Wissenschaft“ mit einem festgefügten Wissenskanon gibt.
Nichtsdestotrotz wird dem unbedarften Bürger das volatile und noch weitgehend ungesicherte Wissen immer wieder als finaler Stand der Wissenschaft verkauft. Und zwar in einem Duktus, der Zweifel oder Widerspruch im Keim ersticken soll. Dies unter gleichzeitiger Ausblendung kritischer Gegenpositionen. Zweifellos macht das die Kommunikation einfacher. Es ist aber Missbrauch von Wissenschaft. Dieser Missbrauch hat im gesellschaftlichen Diskurs mittlerweile dazu geführt, dass eine Mehrheit glaubt, im Besitz der absoluten Wahrheit zu sein. Fatalerweise gehören dazu auch viele Journalisten, die teilweise mit einem fast schon religiösen Eifer den vermeintlich finalen Stand des Wissens gegen jegliche Kritik verteidigen, als hinge ihr Seelenheil davon ab.
Neben der Politik sind sie die Hauptverursacher der gesellschaftlichen Spaltung, indem sie einen weltfremden Absolutheitsanspruch propagieren und die Verfechter von (begründeten) Gegenpositionen mehr oder weniger ohne Ansehen der Person verunglimpfen. Erst kürzlich ist das Richard David Precht widerfahren, der nach geäußerten Bedenken betreffend die Verabreichung von Corona-Impfstoffen an Kinder von einem Spiegel-Kolumnisten mit der rhetorischen Frage „Wer ist Doktor Wirrkopf?“ geschmäht wurde.
Es gibt nicht „die Wissenschaft“
Oftmals ist die Rede von „der Wissenschaft“. Das klingt, als spreche man von einer höchsten Instanz, deren Urteil keinen Widerspruch duldet. Das ist ein Trugbild, das dem Bürger vorzugsweise dann vorgegaukelt wird, wenn man Maßnahmen durchdrücken will, für die die Argumente fehlen.
Am einfachsten kann man dies an einem Beispiel verdeutlichen. Von Corona Genesene werden für eine gewisse Zeitdauer Geimpften gleichgestellt, weil sie, wie jene, teilweise vor einer erneuten Infektion und in einem hohen Maße vor schweren Krankheitsverläufen geschützt sind. Kürzlich wurde nun in Deutschland die Dauer dieses Genesenen-Status von vormals 6 Monaten auf 90 Tage verkürzt. Aus wissenschaftlichen Gründen, wie es heißt. In Wahrheit wurde der Status auf 62 Tage, also etwa 2 Monate reduziert, da man während der ersten 28 Tage nach dem Positivtest noch nicht als genesen gilt. Doch dies nur am Rande.
Zugleich belässt die EU die Gültigkeit des Status auf 6 Monaten und beruft sich gleichfalls auf die Wissenschaft.
Und die Schweiz verlängert die Gültigkeitsdauer auf 12 Monate – natürlich ebenfalls mit dem Verweis auf wissenschaftliche Erkenntnisse.
Das ist nichts Ungewöhnliches, weil es die Wissenschaft – sozusagen als monolithischen Block – eben nicht gibt. Auch in der Wissenschaft existieren vielfältige Meinungen nebeneinander, vor allem im frühen Prozess des Erkenntnisgewinns. Was sich am Ende durchsetzt, ist offen. Je weniger formal die Disziplin, desto größer das potentielle Meinungsspektrum. Typischerweise besonders groß ist die Meinungsvielfalt in den Humanwissenschaften, zumal in der Medizin. Es werden dabei durchaus begründete Meinungen vertreten, aber eben keine absoluten Wahrheiten.
Auch dies wieder ein Beispiel dafür, dass es sehr oft um Meinungen geht, nicht um Fakten und schon gar nicht um absolute Wahrheiten.
Endgültige wissenschaftliche Wahrheit
Schon weiter oben wurde festgestellt: Absolute wissenschaftliche Wahrheiten gibt es nicht. Es gibt aber einen vorläufigen und im Rahmen unserer Möglichkeiten abgesicherten Stand des Wissens. Mehr kann man ehrlicherweise nicht konstatieren. Und das gilt in besonderem Maße für die Humanwissenschaften.
Die Vorläufigkeit impliziert die Eventualität von Veränderungen in unserem Wissensstand. Wir wissen nicht, worin die Änderungen bestehen werden. Wir wissen auch nichts über die Tragweite oder den Zeitpunkt der neuen Erkenntnisse. Ja wir wissen noch nicht einmal, ob diese Eventualität jemals eintreten wird. Was wir sicher wissen, ist nur dies: Weder können wir ausschließen, dass sich alles als Makulatur, als bloßer Schein erweisen könnte, noch können wir sicher sein, dass sich im konkreten Falle überhaupt irgendetwas als unzutreffend herausstellt.
Wissenschaft ist der Versuch, unser Verständnis, unser Modell der Wirklichkeit zu objektivieren, es von den subjektiven Beliebigkeiten zu befreien. Die Methoden dafür heißen Empirie und Skeptizismus.
Mathematische Exaktheit darf man dabei indessen nur in relativ einfachen oder sehr lange und tiefgründig erforschten Fällen erwarten. Das gilt allenfalls für Teile der Physik und Chemie. Die (axiomatische) Mathematik nimmt hier eine Sonderrolle ein.
Im Hinblick auf die erzielbare Präzision außerhalb der Mathematik hat Einstein die Grenzen folgendermaßen gezogen:
„Insofern sich die Sätze der Mathematik auf die Wirklichkeit beziehen, sind sie nicht sicher, und insofern sie sicher sind, beziehen sie sich nicht auf die Wirklichkeit.“
Absolute Wahrheit übersteigt das menschliche Maß – und auch das Maß der Wissenschaft.
In aller Kürze können wir daher die folgenden Grundsätze formulieren.
Grundsätze zur Diskriminierung von Fake News und zur Annäherung an „die Wahrheit“
(1) Absolutheit: Es gibt keine absoluten Wahrheiten. Und auch diese Aussage ist nicht absolut gesetzt.
(2) Skepsis: Skepsis ist die unabdingbare Voraussetzung wissenschaftlicher Erkenntnis. Eine skeptische Grundhaltung schützt vor Leichtgläubigkeit.
(3) Kritikfähigkeit: Das Erkennen der Wahrheit erfordert eine kritische Grundhaltung. Naheliegende Zusammenhänge und Erwartungen müssen nicht zutreffen.
(4) Plausibilität: Was der Erwartung zuwiderläuft, muss nicht falsch sein, es sollte sich aber im Gesamtkontext als plausibel erkennen lassen.
(5) Falsifikation: Die Wahrheit einer Aussage im strengen Sinne zu beweisen ist in der Realität, von trivialen Ausnahmen abgesehen, fast nie möglich. Wenn die Aussage aber nicht zutrifft, wenn es sich also um eine Falschinformation handelt, dann lässt sich das meist mit vertretbarem Aufwand zeigen.
(6) Unabhängigkeit: Der Wahrheitsgehalt einer Aussage ist unabhängig davon, wer sie tätigt.
(7) Majorität: Inwiefern eine Aussage richtig oder falsch ist, hängt nicht davon ab, ob eine Mehrheit oder eine Minderheit sie für richtig oder falsch hält.
(8) Subjektivität: Im öffentlichen Leben, in den Medien, in den sozialen Netzen und in der Politik geht es nahezu immer um Meinungen oder um Halbwahrheiten. Oft werden diese dennoch als Fakten und damit als vermeintliche Wahrheit ausgegeben. Insofern es um Meinungen geht, lässt sich im strengen Sinne die Frage nach der Wahrheit nicht stellen.
(9) Interesse: Man sollte sich stets fragen, inwiefern die Botschaft von Interessen geleitet ist oder sein könnte. Sofern man Anhaltspunkte dafür findet, ist ein besonderes hohes Maß an Skepsis angeraten. Firmen vertreten meist wirtschaftliche, Parteien und Verbände verfolgen in aller Regel weltanschauliche Interessen. Politiker wollen mit gezielt gestreuten Halbwahrheiten nicht selten von anderen Problemen ablenken.
(10) Egozentrik: Auch das eigene Urteil verdient kritische Distanz und Skepsis.
Das Jahr 2021 ist vorbei und die Corona-Zahlen liegen nun vor. Zu Beginn des Jahres 2021 konnte man erwarten, dass sich das schlimme Corona-Jahr 2020 nicht wiederholen würde, schließlich standen mehrere Impfstoffe zur Verfügung. Allenfalls konnte man es für eine Frage der Organisation halten, bis hinreichend viele Menschen geimpft und die Pandemie damit mehr oder weniger zu Ende sei.
Heute sind wir alle klüger: Die Zahlen für 2021 sind dramatischer als die für 2020 – trotz der Impfung. Fast dreimal so viele Infizierte und immerhin 59% mehr Tote. Mittlerweile wissen wir auch, dass zweimal Impfen nicht reicht. Absehbar ist auch nach der dritten Spritze keine wirkliche Immunität gegeben. Die Impfung schützt zwar oft vor schweren Krankheitsverläufen und Tod, aber wenig vor einer Infektion und vor dem Weitertragen des Virus. Auch Geimpfte sind also nach wie vor Teil der Infektionsdynamik. Zudem ist bekannt, dass der Schutz der Impfung bereits binnen 3 – 4 Monaten nachlässt und der Impfstoff nach 6 Monaten und mehr, je nach Alter, nur noch eine schwache Wirkung entfaltet. Die daraus folgende Problematik wird im Text diskutiert und anhand vieler Grafiken visualisiert.
Aus der tiefergehenden Untersuchung zu den Zahlen für 2021 werden Schlüsse zum altersabhängigen Risiko gezogen: Letalität und Mortalität steigen exponentiell mit dem Lebensalter. Die Sterblichkeit nach einer Infektion (Letalität) verzehnfacht sich pro 18 Lebensjahren. Die Mortalität verzehnfacht sich pro 22 Lebensjahren. Um das richtig einzuordnen, muss man erwähnen, dass das absolute Corona-Sterberisiko von 18-Jährigen bei etwa 0,0005% liegt, das von 84-Jährigen bei etwa 0,5%.
Die nachfolgend präsentierten Corona-Grafiken und Analysen basieren sämtlich auf dem vom Robert-Koch-Institut (RKI) veröffentlichten Zahlenmaterial. Die entsprechenden Referenzen sind im Quellenverzeichnis aufgeführt.
Die Corona-Impfquoten, die Inzidenzen bezüglich der Infizierten, der Hospitalisierten und der Corona-Todesfälle werden vom RKI in hoher zeitlicher Auflösung publiziert. Man muss die Erfassungssystematik nicht in jedem Detail für gelungen und zweckmäßig halten, in Summe ist das RKI dennoch die einzige einigermaßen verlässliche Corona-Datenquelle. Es gibt kleinere Unschärfen, z.B. bezüglich der Impfquoten, und es gibt eklatante Mängel, z.B. hinsichtlich des Erfassung des Impfstatus der Infizierten, der Hospitalisierten und der Todesfälle. Immerhin werden seit August 2021 für die symptomatischen Fälle die Infektionszahlen getrennt nach Geimpften und Ungeimpften erfasst. Weitere für die Analyse wichtige Einflussgrößen wie die verstrichene Zeitspanne seit der Impfung oder das effektive Ansteckungsrisiko aufgrund des Kontaktprofils werden nicht dokumentiert und können daher auch nicht ausgewertet werden.
Die Inzidenzen der Corona-Infektionen und der Fälle der „an oder mit“ Corona Verstorbenen nehmen wir einfach so, wie sie vom RKI veröffentlich wurden, auch wenn man bezüglich der Höhe der Zahlen berechtigte Zweifel ins Feld führen kann. Tatsächlich könnten die Infektionszahlen deutlich höher gelegen haben, weil viele Infektionen unerkannt geblieben sind. Die Zusammensetzung der Testkohorte spiegelt lediglich rechtliche Vorgaben wider. Nötig wäre aber eine Orientierung an wissenschaftlichen Grundsätzen. In letzter Konsequenz sind daher die veröffentlichten Inzidenzen nur grobe Schätzungen.
Umgekehrt könnten viele Todesfälle fälschlicherweise Corona zugerechnet worden sein, weil die Todeskausalität in vielen Fällen nicht näher untersucht worden ist. In letzter Konsequenz könnte die Infektiosität in Wahrheit höher und die Letalität (Sterblichkeit bei einer Corona-Infektion) tatsächlich kleiner sein, als sich dies aus den Zahlen des RKI ergibt. Das ist hier indessen nicht das Thema: Wir stützen uns auf die Daten des RKI, nichts sonst. Alles andere wäre Spekulation.
Corona-Infizierte und -Todesfälle 2020 und 2021 im direkten Vergleich.
Abbildung 1: Corona-Infizierte und -Todesfälle 2020 und 2021 im direkten Vergleich. Man erkennt, dass sich die Infektionszahlen in 2021 gegenüber 2020 in etwa verdreifacht haben. Die Anzahl der Todesfälle ist um ca. 59 % gestiegen. Rohdaten: RKI, Datenstand 22.01.2022.
In Abb. 1 fällt zunächst die hohe Zahl der Infizierten in 2021 auf. Gegenüber 2020 (mit 10 Monaten Pandemiedauer) haben wir in 2021 ein volles Jahr. Das kann den Anstieg sicher nicht erklären. Offenbar liegt ein Grund eher in der höheren Infektiosität der Deltavariante des Virus. Die Anfang 2021 angelaufene Impfkampagne hatte auf die Anzahl der Infektionen offenbar keinen dämpfenden Einfluss. Mit Blick die Todesfallzahlen registriert man den vergleichsweisen deutlich geringeren Anstieg. Ist das womöglich ein Erfolg der Impfung? – Teilweise sicher ja, der Effekt ist aber wohl geringer, als dies der erste Anschein vermuten lässt. Näheres dazu mit einer genauen Analyse weiter unten.
Infizierte und Todesfälle nach Altersgruppen – Vergleich 2020/2021
Corona-Infizierte 2020 und 2021 nach Altersgruppen im direkten Vergleich.
Abbildung 2: Corona-Infizierte 2020 und 2021 nach Altersgruppen im direkten Vergleich. Wie man sieht, sind in 2021 insbesondere die Infektionszahlen bei den jüngeren Altersgruppen erheblich gestiegen. Rohdaten: RKI, Datenstand 22.01.2022.
Corona-Todesfälle 2020 und 2021 nach Altersgruppen im direkten Vergleich.
Abbildung 3: Corona-Todesfälle 2020 und 2021 nach Altersgruppen im direkten Vergleich. Die absoluten Fallzahlen zeigen einen Anstieg insbesondere bei den Über-50-Jährigen. Das größere relative Wachstum verzeichnet man bei den Jüngeren. In der Gesamtschau sind aber dennoch die Älteren mit großem Abstand dominierend. Allein der Zuwachs in 2021 ist bei den Älteren (60+) viermal höher als die Gesamtanzahl der Toten bei den Jüngeren (0-59). Rohdaten: RKI, Datenstand 22.01.2022.
Beim Vergleich der beiden Grafiken nach Abb. 2 und 3 fällt auf, dass die Infektionszahlen weit überwiegend von den Altersgruppen unter 60 getrieben werden, die Todesfälle passieren aber nach wie vor zum größten Teil in der Altersgruppe ab 60. Das werden wir weiter unten genauer beleuchten.
Am vorstehenden Befund hat sich auch durch die Verfügbarkeit von Impfstoffen und der seit Januar 2021 laufenden Impfkampagne offenbar nichts oder nur wenig geändert. Jedenfalls ist der Effekt hier nicht sichtbar. Dabei waren doch gerade die Über-80-Jährigen schon früh im Jahr mit hoher Priorität und in großer Zahl geimpft worden.
Die folgende Abbildung mit zusammengefassten Altersgruppen untermauert dieses vorläufige Resümee in aller Deutlichkeit.
Abbildung 4: Corona-Infizierte und -Todesfälle 2020 und 2021 in ausgewählten Altersgruppen im direkten Vergleich. Bei der Betrachtung der aggregierten Altersgruppen sieht man nochmals deutlicher den starken Anstieg der Infektionen bei den Jüngeren. Tatsächlich ist die Anzahl der Infektionen in der Altersgruppe 0-59 gegenüber 2020 um über 200 % gewachsen. In der Altersgruppe 60+ haben sie sich dagegen nur um gut 100% erhöht. Zugleich sind hier auch die Todesfallzahlen weit weniger gestiegen. Rohdaten: RKI, Datenstand 22.01.2022.
Wenn man den Zahlen etwas Positives abgewinnen will, dann kann man an dieser Stelle immerhin darauf hinweisen, dass die Todesfallzahlen (+53 %) in der Altersgruppe 60+ weniger gewachsen sind als die Infektionszahlen (+104 %). Das darf man zum Teil sicher auch der Impfung zurechnen. Wie groß der Effekt tatsächlich ist, werden wir weiter unten genauer untersuchen. In der Altersgruppe 20-59 (mit einer im Jahresmittel geringen Impfquote) sind die Todesfallzahlen (+202 %) hingegen fast genau so schnell gestiegen wie die Infektionszahlen (+237 %).
Infizierte und Todesfälle nach Altersgruppen – Analyse für 2021
Relative Anteile der Corona-Infizierten und -Todesfälle 2021 nach Altersgruppen.
Abbildung 5: Relative Anteile der Corona-Infizierten und -Todesfälle 2021 nach Altersgruppen. In der linken Säule sind die Infizierten nach ihrem jeweiligen Anteil farbcodiert eingetragen. Die rechte Säule weist entsprechend die altersgruppenspezifischen Anteile unter den Todesfallzahlen aus. Man erkennt, dass die Infektionen überwiegend bei den Jüngeren auftreten, die Todesfälle indes bei den Älteren. Die gelb-braunen Farbtöne in der linken Säule stehen für die Altersgruppe 0-39 mit einem Anteil an den Infektionen von über 55%. In der rechten Säule kann man diese Farbtöne kaum ausmachen. Der Anteil an den Todesfallzahlen liegt bei etwa 0,7%. Umgekehrt am oberen Ende der Säule: 8,4% der Infizierten werden der Altersgruppe 70+ zugerechnet. Zugleich stellt diese Gruppe 82% aller Corona-Toten. Rohdaten: RKI, Datenstand 22.01.2022.
Auch wenn man mit Blick auf Abb. 5 dem ersten Anschein nach denkt, es sei anders: Die Farbcodierung ist in beiden Säulen gleich. Die ausgeprägt asymmetrische Verteilung zwischen Infektionszahlen und Todesfällen über die Altersgruppen hinweg wird mittels der Grafik klar vor Augen geführt. Das wirft ein denkbar grelles Licht auf die Corona-Maßnahmen. Abgesehen von der prioritären Impfung der Ältesten setzen sie überwiegend an der linken Säule im gelb-braunen und im grünen Bereich an (Altersgruppen 0-39 und 50-69). Der Effekt soll sich aber in der rechten Säule zeigen, wo diese Gruppen gerade einmal 17% ausmachen.
Das ist in etwa so, als würde man nach der Brandmeldung im Seniorenstift die Feuerwehr zur Grundschule schicken.
Es zeigt sich hier überdeutlich, dass viele der getroffenen Maßnahmen schon deswegen nicht wirken können, weil sie am falschen Ende ansetzen. Vielleich noch etwas klarer kommt das mittels der nachfolgenden beiden Abbildungen zum Ausdruck.
In der ersten (Abb. 6) sind die Altersgruppen teilweise zusammengefasst, um die zentrale Botschaft noch stärker hervortreten zu lassen. In der zweiten (Abb. 7) wurde eine andere Darstellung gewählt.
Relative Anteile der Corona-Infizierten und -Todesfälle 2021 nach ausgewählten Altersgruppen.
Abbildung 6: Relative Anteile der Corona-Infizierten und -Todesfälle 2021 nach ausgewählten Altersgruppen. In der linken Säule sind die Infizierten nach ihrem jeweiligen Anteil farbcodiert eingetragen. Die rechte Säule weist entsprechend die altersgruppenspezifischen Anteile unter den Todesfallzahlen aus. Man erkennt, dass die Infektionen überwiegend bei den Jüngeren auftreten, die Todesfälle indes bei den Älteren. Die Altersgruppe 0-19 stellt 25% der Infizierten, aber nur 0,1% der Todesfälle. Dem fast 84%-igen Anteil der den Altersgruppen 0-19 und 20-59 zugerechneten Infektionen stehen 6,6% der Todesfälle entgegen. Dagegen treten 93,3% der Todesfälle in den Altersgruppen 60-79 und 80+ auf, die ihrerseits nur etwa 16% der Infektionsfälle zu verantworten haben. Rohdaten: RKI, Datenstand 22.01.2022.
Relative Anteile der Corona-Infizierten und -Todesfälle 2021 nach Altersgruppen.
Abbildung 7: Relative Anteile der Corona-Infizierten und -Todesfälle 2021 nach Altersgruppen. Die gelben Säulen zeigen die relativen Infektionshäufigkeiten, die grauen die Todesfälle. Kurz gefasst sieht man auch hier, dass die Infektionen und die Todesfälle in unterschiedlichen Altersgruppen auftreten. Wo nur noch ein Bruchteil der Infektionen verzeichnet wird, sind die Todesfallzahlen am höchsten. Rohdaten: RKI, Datenstand 22.01.2022.
Die Unwirksamkeit vieler politisch verfügter Corona-Maßnahmen kann nach dieser Betrachtung kaum noch verwundern: Sie gehen schlichtweg am Ziel vorbei.
Um den obigen Feuerwehrvergleich nochmals aufzunehmen: Natürlich ist die potentielle Brandgefahr bei der Grundschule endgültig gebannt, die Feuerwehr ist ja schon vor Ort. Das kann sich man als Erfolg schönreden. Aber: Der Unterricht ist gestört und die Schüler leiden. Zugleich steht das Seniorenstift lichterloh in Flammen.
Überblick zu den kritischen Größen Infektionsrisiko, Letalität und Mortalität
Grundsätzlich gilt zwischen den drei Faktoren Infektionsrisiko, Letalität und Mortalität der folgende Zusammenhang:
Die Mortalität ist der relative Anteil der an einer bestimmten Krankheit Verstorbenen bezogen auf die Gesamtheit der Bevölkerung oder bezogen auf eine bestimmte Personengruppe (z.B. Menschen eines gegebenen Alters oder die Bevölkerung in einer Region).
Die Letalität ist der relative Anteil der Verstorbenen bezogen auf die Gesamtheit der Infizierten oder die Gesamtheit der Infizierten einer bestimmten Personengruppe.
Das Infektionsrisiko beschreibt die Wahrscheinlichkeit für eine (Coronavirus-)Infektion. Es ist abhängig von den Eigenschaften des Virus, von den Umweltbedingungen, von individuellen Faktoren sowie von Maßnahmen zur Kontrolle der Verbreitung des Virus.
Die Letalität ist ein Maß für die Gefährlichkeit des Virus bzw. der Infektion bei gegebener Leistungsfähigkeit des Gesundheitssystems und gegebenem Gesundheitszustand des betreffenden Personenkreises sowie ggf. auch der Impfung. Dagegen misst die Mortalität darüber hinaus das Infektions- bzw. Erkrankungsrisiko. In Bezug auf Corona steckt in der Maßzahl der Mortalität somit auch die Wirksamkeit von Schutzmaßnahmen.
Bei 100%-iger Wirksamkeit der Schutzmaßnahmen ist das Infektionsrisiko = 0 und somit die spezifische Mortalität ebenfalls 0. Ohne Schutzmaßnahmen oder mit wenig effektiven Schutzmaßnahmen liegt das Infektionsrisiko in Abhängigkeit von individuellen Faktoren (z.B. Kontakthäufigkeit, Kontaktdauer, Kontaktintensität) irgendwo zwischen 0 und 100%. Im Extremfall, wenn alle Personen der relevanten Bezugsgruppe infiziert sind, ist die Mortalität gleich der Letalität.
Letalität nach Altersgruppen – Vergleich 2020/2021
Covid-19-Letalität (Sterblichkeitsrate nach einer Corona-Infektion) für 2020 und 2021 nach Altersgruppen im Vergleich.
Abbildung 8: Covid-19-Letalität (Sterblichkeitsrate nach einer Corona-Infektion) für 2020 und 2021 nach Altersgruppen im Vergleich. Für 2021 ist jeweils der Letalitätswert explizit eingetragen. Man sieht, dass die 2021er-Säulen meist etwas kürzer sind als die 2020er. Stark gesunken ist die mittlere Sterblichkeit über alle Altersgruppen. Sie hat sich von 2,47% in 2020 auf 1,28% in 2021 etwa halbiert. Dieser positive Effekt ist indes nur zu einem geringen Teil auf die Impfung zurückzuführen. Trotz der sehr hohen Impfquote in der Altersgruppe 90+ ist die Letalität für die Ältesten sogar gestiegen. Rohdaten: RKI, Datenstand 22.01.2022.
Wie man Abb. 8 entnimmt, ist die Sterblichkeit nach einer Corona-Infektion in einigen Altersgruppen zurückgegangen, in anderen gestiegen, wenn auch beides nur geringfügig. Für die Altersgruppen ab 60 liegt die Letalität in 2021 aber immer noch höher als 1%, zum Teil drastisch höher. Die anderen Altersgruppen, also alle unter 60, weisen hingegen viel kleinere Sterblichkeitsraten p.a. auf. Unter-40-Jährige liegen bei max. 0,03%. Im Diagramm sind diese Säulen skalierungsbedingt daher nicht mehr sichtbar.
Der Rückgang der durchschnittlichen Sterblichkeit (nach einer Corona-Infektion) über alle Altersgruppen in 2021 ist i. W. auf die hohen Infektionszahlen bei den Jüngeren, wie sie oben dokumentiert wurden, zurückzuführen. Sie sind wenig von schweren Verläufen und Tod betroffen und tragen daher kaum zu den Todesfällen bei. Es ist also ein statistischer Effekt.
Um das an einem Beispiel plausibel zu machen: Wenn sich die Infektionszahlen in der Altersgruppe 0-39 verdoppeln, dann hat dies auf die Todesfallzahlen keinen nennenswerten Einfluss. Allenfalls werden die Beträge in Summe um einige 100 Fälle steigen. Prozentual würde das weniger als ein Prozent ausmachen. Zugleich würden aber die Infektionszahlen insgesamt um mehr als 50% steigen. Im Ergebnis würde daher die Sterblichkeitsrate p.a. nach Corona-Infektion auf etwa Zweidrittel (1/1,5) des aktuellen Wertes sinken (also -33%). Und dies völlig ohne irgendeine steuernde Maßnahme, wie z.B. eine Impfpflicht. Genau diesen Effekt kann man in 2021 im Vergleich zu 2020 beobachten, wie wir oben gesehen haben (s. Abb. 3 und 4).
Covid-19-Letalität (Sterblichkeit nach einer Corona-Infektion) für 2020 und 2021 in ausgewählten Altersgruppen im Vergleich
Abbildung 9: Covid-19-Letalität (Sterblichkeit nach einer Corona-Infektion) für 2020 und 2021 in ausgewählten Altersgruppen im Vergleich. In der Relation erkennt man in den höheren Altersgruppen den Rückgang der Sterblichkeit nach einer Infektion. Die mittlere Sterblichkeit über alle Altersgruppen hat sich von 2,47% in 2020 auf 1,28% in 2021 etwa halbiert. Die leichte Abnahme der Sterblichkeit bei den Altersgruppen 60-79 und 80+ ist mit großer Wahrscheinlichkeit ein Ergebnis der prioritären Impfung seit Anfang 2021. Rohdaten: RKI, Datenstand 22.01.2022.
Die Abnahme der Letalitätswerte gegenüber 2020 ist erwähnenswert, vor allem in der Altersgruppe 60-79, sie bleibt aber letztlich doch schwach ausgeprägt. Genau wie in der Altersgruppe 80+ dürfte dieser Rückgang auf die Wirkung der Impfung zurückzuführen sein. Dazu mehr weiter unten bei der Untersuchung der Sterblichkeitsraten für Geimpfte und Ungeimpfte. Die Letalität in den Altersgruppen 60-79 und 80+ bleibt aber dennoch auf hohem Niveau. Auffällig sind die extremen Unterschiede in den Letalitätsraten beim Vergleich zwischen den Älteren und den Jüngeren. Diesbezüglich hat sich zwischen 2020 und 2021 nahezu nichts geändert. Die Säulen für die Altersgruppen 0-19 (0,004%, also ein Fall pro 25.000 Infizierten) und 20-59 (0,014%, also 1 Fall pro 710 Infizierten) sind im Diagramm nicht bzw. gerade noch ansatzweise sichtbar.
Kurvenverlauf der Covid-19-Letalität (Sterblichkeit nach einer Corona-Infektion) für 2020 und 2021 in Abhängigkeit vom Alter.
Abbildung 10: Kurvenverlauf der Covid-19-Letalität (Sterblichkeit nach einer Corona-Infektion) für 2020 und 2021 in Abhängigkeit vom Alter. Um die großen Unterschiede in den Sterblichkeitsraten zu veranschaulichen, wurde in der Darstellung eine logarithmische Skalierung gewählt. Im Lebensalter bis etwa 25 bewegen wir uns hier bei Letalitätswerten von 0,01% und darunter. Hingegen liegen die Sterblichkeitsraten für Lebensalter über 80 höher als 10%. In der Relation sind das in beiden Jahren etwa 1000-fach höhere Werte. Die Kurve für 2021 verläuft im oberen Bereich geringfügig flacher, was vermutlich auf die Wirkung der Impfkampagne zurückzuführen ist. Rohdaten: RKI, Datenstand 22.01.2022.
Der Vergleich der beiden Kurvenverläufe in Abb. 10 zeigt nochmals deutlich, dass sich in 2021 unter dem Gesichtspunkt der Sterblichkeit bei einer Corona-Infektion gegenüber 2020 kaum etwas geändert hat. Letztlich bleiben die Unterschiede jedenfalls gering. Die noch am meisten ins Auge fallenden Abweichungen bei den Unter-30-Jährigen sind in der Gesamtschau belanglos, weil wir hier von sehr niedrigen absoluten Risikoraten um 0,02% und darunter sprechen.
Tatsächlich größer (max. 1%) sind die Differenzen bei höherem Alter etwa zwischen 60 und 90. Der ab einem Alter von 60 gegenüber der 2020er Kurve partiell flachere Verlauf der Kurve für 2021 steht für einen geringeren Anstieg der Sterblichkeit in diesem Altersbereich. Allerdings zeigen sich auch die Grenzen: Bei den 90-Jährigen konnte auch der grundsätzlich positive Effekt der Impfung den Anstieg der Sterblichkeit nicht stoppen. Dabei liegt es auf der Hand: Die Impfung kann vor allem dort einen merklichen Effekt nach sich ziehen, wo das Risiko höher ist. Bei den Jüngeren mit den sehr niedrigen absoluten Risiken bleibt der Einfluss in der Gesamtschau vernachlässigbar.
Mortalität nach Altersgruppen – Vergleich 2020/2021
Covid-19-Mortalität (Sterblichkeit p.a.) für 2020 und 2021 nach Altersgruppen im Vergleich.
Abbildung 11: Covid-19-Mortalität (Sterblichkeit p.a.) für 2020 und 2021 nach Altersgruppen im Vergleich. Man sieht, dass die 2021er-Säulen stets etwas höher sind als die 2020er. Die Sterblichkeit aufgrund von Corona ist daher in 2021 gegenüber 2020 angestiegen. Die Größe des Effekts erkennt man anhand der mittleren Sterblichkeit über alle Altersgruppen: Sie hat sich von 0,053% in 2020 auf 0,084% in 2021 in der Relation um 59% erhöht. Diese ungünstige Entwicklung ist auf die stark angewachsenen Infektionszahlen zurückzuführen und spiegelt die Zunahme bei den Todesfallzahlen wider. Durch die im Jahresverlauf ohnehin noch nicht voll wirksame Impfung konnte der Anstieg nicht kompensiert werden (s. Text). Rohdaten: RKI, Datenstand 22.01.2022.
Wie man Abb. 11 entnimmt, ist die Corona-Sterblichkeit insbesondere in den Altersgruppen ab 50 gewachsen, teilweise durchaus signifikant. Für die Altersgruppen 80-89 liegt die Mortalität in 2021 bei 0,57%, in der Altersgruppe 90+ gar bei 1,54%. Damit hat sich die Sterblichkeit in der Spitze um 0,15% bis 0,3% gegenüber dem Wert für 2020 erhöht. In absoluten Zahlen macht das allein bezüglich der Altersgruppen 80-89 und 90+ fast 12.000 Sterbefälle mehr aus. In den Altersgruppen 40-49 bis hinunter zu 0-9 verbleibt die Mortalität hingegen im Wertebereich zwischen 0,009% und 0,0004% (also 1 Fall pro 11.000 in der Altersgruppe 40-49 bzw. 1 Fall pro 250.000 in der Altersgruppe 0-19). Im Diagramm sind diese Säulen skalierungsbedingt nicht mehr sichtbar.
Die Erhöhung der durchschnittlichen Sterblichkeit über alle Altersgruppen in 2021 ist also i. W. auf die nochmals gestiegenen Todesfallzahlen bei den Älteren zurückzuführen. Die Altersgruppen ab 60 und insbesondere ab 80 tragen zum weit überwiegenden Teil zu den Todesfällen bei. Auch die prioritäre Impfung der Älteren und die erzielte hohe Impfquote in dieser Altersgruppe konnte den beobachteten Anstieg der Mortalität nicht verhindern. Durch die Impfung wurde der Zuwachs zwar abgemildert, dies aber nicht so durchgreifend, wie man das zu Beginn des Jahres wohl erhofft hatte. Ein Grund dafür dürfte die relativ schnell nachlassende Schutzwirkung der Impfung sein. Dies spricht nicht grundsätzlich gegen die Impfung, es relativiert aber den zu erwartenden Effekt.
Covid-19-Mortalität (Sterblichkeit p.a.) für 2020 und 2021 in ausgewählten Altersgruppen im Vergleich.
Abbildung 12: Covid-19-Mortalität (Sterblichkeit p.a.) für 2020 und 2021 in ausgewählten Altersgruppen im Vergleich. Die 2021er-Säulen sind stets etwas höher sind als die 2020er. Die Corona-Sterblichkeit ist daher in 2021 gegenüber 2020 angestiegen. Die größten relativen Zuwächse sind bei den Jüngeren zu verzeichnen. Im Hinblick auf die Sterblichkeit dominieren indessen die Altersgruppen 60-79 und 80+ mit riesigem Abstand. Das spiegelt die Erhöhung der absoluten Fallzahlen der Toten in 2021 wider (s. a. Abb. 4). Rohdaten: RKI, Datenstand 22.01.2022.
Der direkte Vergleich der Säulenhöhen in Abb. 12 zeigt in allen Altersgruppen einen Anstieg der Corona-Sterblichkeit p.a. Die relative Zunahme der Sterblichkeit ist dabei hinsichtlich der Altersgruppen unter 80 am stärksten ausgeprägt, wobei die Gruppen 0-19 und 20-59 aufgrund des absolut gesehen sehr niedrigen Risikos in Summe nicht ins Gewicht fallen. Anders sieht es aus in der Altersgruppe 60-79. Hier liegt der relative Zuwachs bei über 95%, was in absoluter Höhe immerhin eine Zunahme um 0,062% bedeutet. Bezüglich der Todesfallzahlen gehen über 11.000 Tote allein auf dieses Konto. Man kann vermuten, dass durch ein schnelleres Voranschreiten Impfung in der Altersgruppe 60-79 ein gewisser Anteil dieser Fälle hätte vermieden werden können (s. dazu die Diskussion zur weiter unten).
Kurvenverlauf der Covid-19-Mortalität (Sterblichkeit p.a.) für 2020 und 2021 in Abhängigkeit vom Alter.
Abbildung 13: Kurvenverlauf der Covid-19-Mortalität (Sterblichkeit p.a.) für 2020 und 2021 in Abhängigkeit vom Alter. Um die großen Unterschiede in den Sterblichkeitsraten zu veranschaulichen, wurde in der Darstellung eine logarithmische Skalierung gewählt. Im Lebensalter bis etwa 25 bewegen wir uns hier bei Mortalitätswerten von 0,001% und darunter. Hingegen liegen die Sterblichkeitsraten für Lebensalter oberhalb 90 bei 1% und darüber. In der Relation sind das in beiden Jahren etwa 1000-fach höhere Werte. Im Vergleich zu 2020 verläuft die Kurve für 2021 insgesamt etwas flacher, was z. T. vermutlich auf die Wirkung der Impfkampagne zurückzuführen ist. Daneben haben aber vor allem die hohen Infektionszahlen bei den Jüngeren einen markanten Einfluss auf den flacheren Kurvenverlauf. Rohdaten: RKI, Datenstand 22.01.2022.
Der Vergleich der beiden Kurvenverläufe in Abb. 13 zeigt nochmals in aller Klarheit, dass in 2021 unter dem Gesichtspunkt der Gesamtsterblichkeit gegenüber 2020 kein wirklicher Fortschritt erzielt wurde. Im Gegenteil: Die Mortalität hat sich durchweg erhöht. Als Verbesserung kann man allenfalls den geringeren relativen Anstieg bei den Älteren konstatieren. Zumindest zum Teil dürfte dieses Resultat auf den risikosenkenden Effekt der Impfung zurückzuführen sein. Ohne die Impfung würde die Mortalität in den Altersgruppe 60+ und damit auch insgesamt sicher höher liegen. Im Rahmen der Diskussion zur Letalität von Geimpften und Ungeimpften wird dieses Szenario näher beleuchtet.
Detailanalyse zur Letalität nach Alter
Die obigen Kurvendarstellungen für die Letalität und die Mortalität über das Alter erlauben aufgrund der über weite Altersbereiche nahezu linearen Verläufe einfache Näherungsdarstellungen oder andere polynomiale Approximationen. In Abb. 14 ist der Kurvenverlauf der Letalität zusammen mit zwei Näherungskurven in Abhängigkeit vom Alter dargestellt. Erfreulicherweise kann man die effektive Letalität für einen weiten Bereich der interessierenden Lebensalter mittels einer (in logarithmischer Darstellung linear erscheinenden) Exponentialfunktion darstellen.
Die lineare Näherung bringt die entscheidende Aussage in aller Deutlichkeit zum Ausdruck:
Die Letalität steigt exponentiell mit dem Lebensalter.
Das Wesen der Corona-Pandemie liegt bei Lichte betrachtet nicht darin, dass das Virus sich exponentiell ausbreiten kann. Für die effektive Bekämpfung viel wichtiger ist die Erkenntnis des mit dem Alter exponentiell steigenden Risikos. Übersetzt heißt dies: Maßnahmen zur Eindämmung der Todesfallzahlen müssen dort ansetzen, wo die Fallzahlen auftreten. Also bei den Alten, nicht bei den Jungen oder gar bei Kindern. Der Hebel bei den Ersteren hat eine bis zu 1000-fache Übersetzung (s.u.). Umgekehrt ist bei Letzteren das Kosten-Nutzen-Verhältnis um denselben Faktor kleiner.
Kurvenverlauf der Covid-19-Mortalität (Sterblichkeit p.a.) für 2020 und 2021 in Abhängigkeit vom Alter.
Abbildung 14: Kurvenverlauf der Covid-19-Letalität (Sterblichkeit nach Infektion p.a.) für 2021 in Abhängigkeit vom Alter. Man beachte die logarithmische Darstellung. Zusätzlich eingezeichnet sind zwei Näherungskurven: Eine exponentiell-lineare Näherung (gestrichelte Linie in braun) und eine exponentiell-kubische Näherung (strichpunktierte Linie in grün). Rohdaten zur Letalitätskurve: RKI, Datenstand 22.01.2022.
Ausgedrückt in Prozentwerten lautet die Formel für die Letalität:
Letalität ≈ 0,01% * 10^(Alter-25)/18
Nach vorstehender Approximationsformel verzehnfacht sich der Letalitätswert pro 18 Lebensjahren. Verglichen mit einem 24-Jährigen hat demzufolge ein 42-Jähriger ein 10-fach, ein 60-Jähriger ein 100-fach und ein 78-Jähriger ein 1000-fach höheres Corona-Sterberisiko p.a. bei vorliegender Corona-Infektion. Für die richtige Einordnung sollte man die Höhe des absoluten Risikos nicht unerwähnt lassen. Es liegt bei 0,008% p.a. für 24-Jährige und folglich bei etwa 8% p.a. für 78-Jährige.
Dargestellt als Zweierpotenz besagt die lineare Näherung Letalität~ 2^(Alter/5,41). Daher kann man auch festhalten, dass sich die Corona-Sterblichkeit p.a. bei vorliegender Infektion pro etwa 5,5 Lebensjahren verdoppelt.
Der Kurvenverlauf der Mortalität ist in Abb. 15 zusammen mit einer linearen Näherung in Abhängigkeit vom Alter dargestellt. Den tatsächlichen Verlauf kann man auch in diesem Falle durch eine Exponentialfunktion gut approximieren. Die lineare Näherung bringt das Grundsätzliche im Mortalitätsverlauf in aller Klarheit zum Ausdruck:
Die Mortalität wächst exponentiell mit dem Lebensalter.
Damit wird die obige Aussage zum Wesen der Corona-Pandemie auch im Hinblick auf die Mortalität unterstrichen. Die effektive Bekämpfung und Überwindung der Pandemie erfordert daher zielgenaue Maßnahmen, weil ansonsten die um mehrere Größenordnungen unterschiedlichen Risiken bei Älteren und Jungen in einen Topf geworfen und gleichartig behandelt werden. So erzielt man nur einen Bruchteil der möglichen Wirkung bei gleichzeitig maximalem Kosteneinsatz.
Kurvenverlauf der Covid-19-Mortalität (Sterblichkeit p.a.) für 2021 in Abhängigkeit vom Alter.
Abbildung 15: Kurvenverlauf der Covid-19-Mortalität (Sterblichkeit p.a.) für 2021 in Abhängigkeit vom Alter. Man beachte die logarithmische Darstellung. Zusätzlich eingezeichnet ist eine exponentiell-lineare Näherung (gestrichelte Linie in braun). Rohdaten zur Letalitätskurve: RKI, Datenstand 22.01.2022.
Ausgedrückt in Prozentwerten lautet die Formel für die Mortalität p.a.:
Mortalität ≈ 0,001% * 10^(Alter-24)/22
Nach dieser Approximationsformel verzehnfacht sich der Mortalitätswert p.a. pro 22 Lebensjahren. Verglichen mit einem 18-Jährigen hat demzufolge ein 40-Jähriger ein 10-fach, ein 62-Jähriger ein 100-fach und ein 84-Jähriger ein 1000-fach höheres Corona-Sterberisiko p.a.. Um das richtig einzuordnen, muss man erwähnen, dass das absolute Risiko von 18-Jährigen bei etwa 0,0005% liegt, das von 84%-Jährigen bei 0,5%.
Dargestellt als Zweierpotenz besagt die lineare Näherung Mortalität ~ 2^(Alter/6,62). Daher kann man konstatieren, dass sich das Corona-Sterberisiko p.a. bei vorliegender Infektion pro etwa 6,5 Lebensjahren verdoppelt.
Der Kurvenverlauf des Infektionsrisiko ist in Abb. 16 zusammen mit zwei Näherungskurve in Abhängigkeit vom Alter dargestellt. Der Verlauf kann durch eine lineare Näherung nicht gut approximiert werden. Es geht hier eher darum, das grundsätzliche Verhalten im Verlauf des Infektionsrisikos in eine einfache Formel zu fassen. Für weite Altersbereiche ist die Abweichung vom tatsächlichen Verlauf nicht allzu groß. Die kubische Approximation ist insbesondere für die interessierenden Lebensalter ab 45 sehr viel präziser, aber natürlich auch unhandlicher. Das Wesentliche kommt bereits durch die lineare Näherung zum Ausdruck.
Kurvenverlauf des Covid-19-Infektionsrisikos (Infektionswahrscheinlichkeit p.a.) für 2021 in Abhängigkeit vom Alter.
Abbildung 16: Kurvenverlauf des Covid-19-Infektionsrisikos (Infektionswahrscheinlichkeit p.a.) für 2021 in Abhängigkeit vom Alter. Man beachte die logarithmische Darstellung. Zusätzlich eingezeichnet sind zwei Näherungskurven: Eine exponentiell-lineare Näherung (gestrichelte Linie in braun) und eine exponentiell-kubische Näherung (strichpunktierte Linie in grün). Rohdaten zur Letalitätskurve: RKI, Datenstand 22.01.2022.
Ausgedrückt in Prozentwerten lautet die Formel für das Infektionsrisiko p.a.:
Infektionsrisiko ≈ 10% * 1/10^(Alter-25)/100
Im Unterschied sowohl zur Letalität wie auch zur Mortalität, die beide mit zunehmendem Alter exponentiell wachsen, sehen wir bezüglich des Infektionsrisikos ein gegenteiliges Verhalten: Je höher das Alter, desto geringer die Infektionswahrscheinlichkeit. Diese Abhängigkeit ist zwar nicht so stark und eindeutig ausgeprägt, sie führt aber dennoch dazu, dass das Infektionsrisiko mit dem Alter signifikant zurückgeht. Vermutlich deswegen, weil die Anzahl der Kontakte gleichfalls sinkt.
Ganz grob kann man sagen, dass sich die Infektionswahrscheinlichkeit p.a. pro 30 Lebensjahren in etwa halbiert. Ein Blick auf die Zweierpotenz-Näherungsformel macht das unmittelbar klar.
Berechnung der Letalität für Geimpfte und Ungeimpfte nach Altersgruppen
Die Letalitätswerte pro Altersgruppe haben wir oben aus den Daten des RKI abgeleitet und diskutiert. Eine Unterscheidung in Geimpfte und Ungeimpfte kann daraus nicht unmittelbar abgeleitet werden, da die Impfstatus der Infizierten und der Verstorbenen in 2021 nicht konsequent erfasst wurden (jedenfalls wurden diese Zahlen vom RKI nicht veröffentlicht). Über einen kleinen Umweg ist es indessen möglich, die Zahl der infizierten und verstorbenen Geimpften, und , indirekt zu berechnen. Gleiches geht natürlich auch für die Ungeimpften ( und ).
Das Rechenverfahren mit der Herleitung der nötigen Formeln wird im Anhang näher dargestellt. Die Datengrundlage für die angenommenen altersgruppenspezifischen Impfquoten und Wirksamkeiten ist in Tab. 1 aufgelistet.
Annahmen zu den altersgruppenspezifischen Impfquoten und den Schutzwirkungen der Impfung im Hinblick auf eine Covid-19-Infektion und Tod (an oder mit Corona).
Tabelle 1: Annahmen zu den altersgruppenspezifischen Impfquoten und den Schutzwirkungen der Impfung im Hinblick auf eine Covid-19-Infektion und Tod (an oder mit Corona). Die durchschnittlichen Impfquoten ergeben sich aus dem Verlauf der Impfkampagne im Jahresverlauf aus den Daten des RKI. Die Annahmen zur Schutzwirkung basieren auf den Infektionszahlen Geimpfter und Ungeimpfter (wurden in der zweiten Jahreshälfte für symptomatisch Erkrankte erfasst). Hinsichtlich des Schutzes vor Tod wurden die Todesfallzahlen des RKI in den Kalenderwochen 40-49/2021 zugrunde gelegt. Ferner wurden Studienaussagen über das Nachlassen der Schutzwirkung in den Monaten nach der zweiten Impfdosis berücksichtigt (s. [8]).
Abbildung 17 zeigt die Ergebnisse der Berechnung auf Basis der angenommenen Jahresmittelwerte für die Impfquoten und die Wirksamkeiten (s. Tab. 1).
Berechnete Covid-19-Letalität (Sterblichkeitsrate nach einer Corona-Infektion) in 2021 für Geimpfte und Ungeimpfte nach Altersgruppen.
Abbildung 17: Berechnete Covid-19-Letalität (Sterblichkeitsrate nach einer Corona-Infektion) in 2021 für Geimpfte und Ungeimpfte nach Altersgruppen. Die grauen Säulen zeigen die mittlere Sterblichkeit pro Altersgruppe. Man erkennt, dass die Sterblichkeitsraten von Geimpften in den interessierenden und am meisten gefährdeten Altersgruppen 60-69, 70-79 80-89 und 90+ gegenüber den jeweiligen Referenzwerten (graue Säulen) gesunken sind. Die Letalität der Ungeimpften liegt dagegen überall höher. Der Unterschied zwischen Geimpften und Ungeimpften macht in der Relation z.T. mehr als 100 % aus. Die mittlere Sterblichkeit über alle Altersgruppen liegt natürlich nach wie vor bei 1,28 %. Rohdaten: RKI, Datenstand 22.01.2022.
Die mittlere Letalität der Geimpften liegt nach den berechneten Daten bei etwa 3,68%, die der Ungeimpften bei 0,89%. Unter den Geimpften ist demnach die Sterblichkeit im Mittel 4-mal höher. Das erscheint auf den ersten Blick paradox und absolut unplausibel. Indessen lässt sich dieser Effekt sehr leicht erklären. Wie man Tab. 1 entnimmt und wie es ja auch der Realität entspricht, war die Impfquote bei den Älteren ab 60 im Jahresmittel deutlich höher als die Impfquote bei den Jüngeren (Altersgruppen, 0-9, 10-19, 20,29, 30-39, sogar 40.49). Die Ungeimpften rekrutieren sich daher zu einem großen Teil aus diesen zwar nicht geimpften, aber absolut ungefährdeten Altersgruppen, die zu den Todesfallzahlen in Summe weniger als 1% beitragen. Umgekehrt sind gerade die vulnerablen Gruppen geimpft – und sie haben natürlich trotz der Impfung immer noch ein vielfach höheres Corona-Sterberisiko als die jungen Ungeimpften.
Wir haben oben gesehen, dass sich die Letalität (also die Sterblichkeit bei einer vorliegenden Infektion) pro 18-Lebenjahren verzehnfacht. Wenn nun andererseits die Impfung im Idealfall eine Wirksamkeit von 90% entfaltet, dann wird dieser positive Schutzeffekt im Ergebnis pro 18-Lebensjahren Unterschied aufgezehrt. Demnach hat also z.B. ein 24-Jähriger Ungeimpfter immer noch ein 100-fach geringeres Risiko an Corona zu versterben als ein 78-Jähriger Geimpfter. Tatsächlich ist die Schutzwirkung der Impfung in der Realität gerade für die Ältesten deutlich geringer als 90%, teilweise geht sie eher in Richtung 50%. Deswegen kann es nicht verwundern, dass die Sterblichkeitsrate der Geimpften im Schnitt höher liegt als die der Ungeimpften.
Im Wesentlichen geht es hier um einen statistischen Effekt aufgrund der ungleichen Risikomischung in den beiden Gruppen. Der entscheidende Punkt ist die gewichtete Mittelwertbildung mit den jeweiligen Anteilen unter den Geimpften bzw. Ungeimpften in der Bevölkerung. Vorausgesetzt, die Impfquote in allen Altersgruppen wäre gleich (also gleiche Risikomischung), dann würde die Letalität der Geimpften auch in der Mittelwertbildung über alle Altersgruppen kleiner ausfallen als die der Ungeimpften.
Hypothetische Todesfallzahlen auf Basis der berechneten Letalitätswerte für Geimpfte und Ungeimpfte
Auf Basis der berechneten Letalitätswerte für Geimpfte und Ungeimpfte kann man grob bestimmen, wie hoch die Todesfallzahlen in 2021 gewesen wären, wenn niemand oder alle geimpft gewesen wären. Natürlich ist dieser Ansatz in gewisser Weise spekulativ, weil man nicht sicher vorhersagen kann, welchen Einfluss eine geänderte Impfquote auf die Infektionsfallzahlen gehabt haben würde. Nach allem, was wir heute wissen, kann man in erster Näherung davon ausgehen, dass dieser Einfluss eher gering ist. Nach den Daten des RKI zu den symptomatischen Covid-19-Fällen, tragen Geimpfte und Ungeimpfte in ähnlichem Grade zum Infektionsgeschehen bei. Geimpfte sind demzufolge, schon wegen ihrer zahlenmäßigen Dominanz, nicht wegzudenkende Treiber der Infektionsdynamik. Unterstellen wir daher in einer ersten Betrachtung, es gebe durch die Impfung keine unmittelbare Rückwirkung auf die Inzidenzen. Wie hoch wären unter dieser Annahme die Todesfallzahlen für 2021 in den beiden Extremszenarien ausgefallen?
In Abb. 18 sind die entsprechenden, auf Basis der berechneten Letalitätswerte und der geschilderten Annahme bestimmten hypothetischen Todesfallzahlen im Vergleich zu den tatsächlichen Fallzahlen nach Altersgruppen getrennt hintereinander dargestellt.
Tatsächliche und hypothetische Todesfallzahlen für 2021 bei unterschiedlichen Annahmen.
Abbildung 18: Tatsächliche und hypothetische Todesfallzahlen für 2021 bei unterschiedlichen Annahmen. Die Reihenfolge der Legende entspricht der Höhe der Säulen von vorne nach hinten. Die grünen Säulen im Vordergrund zeigen die Todesfallzahlen unter der Annahme, alle seien schon zu Beginn des Jahres geimpft (Impfquote 100%) gewesen und würden die Sterblichkeitsrate in Höhe der berechneten Letalität aufgewiesen haben. Im Hintergrund orange dargestellt sind die Säulen für das Alternativszenario ganz ohne Impfung (Impfquote 0%). Die tatsächlichen Fallzahlen werden durch die grauen Säulen aufgezeigt. Zusätzlich dargestellt sind die hypothetischen Fallzahlen unter der gleichfalls nicht abwegigen Annahme, die Letalitätswerte aus 2020 würden auch in 2021 zutreffend gewesen sein (blauen Säulen). Rohdaten: RKI, Datenstand 22.01.2022.
In der Gesamtschau macht Abb. 18 klar, dass die Impfung die Fallzahlen in allen Altersgruppen ab 60 merklich verringert. Umgekehrt würde der völlige Verzicht auf die Impfung in genau diesen Altersgruppen für eine signifikante Erhöhung der Fallzahlen gesorgt haben. Keinen nennenswerten Effekt sieht man bei den Altersgruppen unter 50, einen geringen in der Altersgruppe 50-59.
Die Summenwerte der Todesfallzahlen für die vier Szenarien sind in Abb. 19 dargestellt.
Tatsächliche und hypothetische Todesfallzahlen für 2021 in unterschiedlichen Szenarien.
Abbildung 19: Tatsächliche und hypothetische Todesfallzahlen für 2021 in unterschiedlichen Szenarien. Die Grafik zeigt die Summenwerte der Todesfallzahlen für die vier betrachteten Szenarien. Grün: alle schon zu Beginn des Jahres geimpft (Impfquote 100%), Sterblichkeitsrate in Höhe der berechneten Letalität. Orange: Alternativszenario ganz ohne Impfung (Impfquote 0%). Grau: Tatsächliche Fallzahlen in 2021. Blau: Hypothetische Fallzahlen unter der Annahme, die Letalitätswerte aus 2020 würden auch in 2021 gegolten haben. Rohdaten: RKI, Datenstand 22.01.2022.
Das blaue (Sterblichkeit 2020 auch in 2021) und das orange Szenario (berechnete Sterblichkeit für Ungeimpfte aus den 2021-er Daten) belegen, dass die partielle Impfung in 2021 wohl eine Wirkung entfaltet hat. Jedenfalls würden die Fallzahlen ohne die Impfung mit einiger Wahrscheinlichkeit um einen hohen vierstelligen bis niedrigen 5-stelligen Zahlenwert höher ausgefallen sein. Auch wenn die Szenarien die Realität nicht 1:1 widerspiegeln mögen, so geben sie doch einen validen Hinweis. Das gilt auch für die Grenzen im Hinblick auf die Höhe des zu erwartenden Resultats.
Die beiden Szenarien „blau“ und „orange“ sind im Ergebnis nicht deckungsgleich. Das war aufgrund der höheren Gefährdung durch die in 2021 verbreitete Delta-Variante auch nicht zu erwarten. Sie weisen aber in dieselbe Richtung. Das stützt die Sinnhaftigkeit des beschriebenen Ansatzes (s. Anhang) zur separaten Ableitung der Letalitätswerte für Geimpfte und Ungeimpfte. Der Vergleich der tatsächlichen Fallzahlen mit dem grünen Szenario zeigt überdies den möglichen Effekt einer hohen Impfquote. Die Fallzahlen gehen sicher nicht auf Null, das ist angesichts der begrenzten und im Zeitverlauf rasch nachlassenden Wirksamkeit der verfügbaren Impfstoffe auch nicht zu erwarten. Dennoch ist die mögliche Reduzierung der Anzahl der Todesfälle signifikant, wenn auch nicht durchschlagend.
Hypothetische Todesfallzahlen bei Änderung der Impfquote
Im vorstehenden Abschnitt haben wir den Aspekt der Infektionszahlen außer Acht gelassen. Deswegen müssen die Ergebnisse zunächst als Fingerzeige gelten. Es ist indessen möglich, die Auswirkungen einer geänderten Impfquote und oder einer anderen Wirksamkeit des Impfstoffes mit einer etwas höheren Präzision aus den Felddaten abzuleiten. Dabei gehen wir von folgenden Überlegungen aus:
Eine Veränderung der Impfquote hat Einfluss auf die Anzahl der Geimpften und Ungeimpften und damit auch auf die Infektionszahlen. Die Sterblichkeit sowohl unter den Geimpften wie auch den Ungeimpften berührt das aber in erster Näherung nicht. Daher erscheint die Annahme konstanter Letalitätswerte pro Altersgruppe plausibel. Anders verhält es sich bezüglich der (Gesamt-)Letalität über alle Infizierten. Wenn die Impfquote modifiziert wird oder sich der Infektionsschutz verändert, dann verschieben sich auch die relativen Anteile der Geimpften und Ungeimpften unter den Infizierten und in der Folge auch das Verhältnis zwischen den Todesfallzahlen. Daher wird die (Gesamt-)Letalität bei der beschriebenen Änderung in der Regel nicht gleichbleiben.
Ausgangspunkt für die Ableitung der Formelbeziehungen ist das Invarianz-Postulat:
Die altersgruppenspezifischen Letalitätswerte der Geimpften und der Ungeimpften sind invariant hinsichtlich einer Modifikation der Impfquote und / oder einer Veränderung der Wirksamkeit des Impfstoffs im Hinblick auf den Schutz vor Infektion (vorausgesetzt, der Todesfallschutz bleibt gleich).
Die mathematischen Überlegungen finden sich im Anhang.
Folgende Formeln kommen für die Bestimmung der Todesfallzahlen bei modifizierter Impfquote und/oder Wirksamkeit zur Anwendung.
Anzahl der Fälle unter Ungeimpften pro Altersgruppe:
(3)
Anzahl der Fälle unter Geimpften pro Altersgruppe:
(4)
Neue (Gesamt-)Letalität pro Altersgruppe:
(5)
Gesamtanzahl der Fälle pro Altersgruppe:
(6)
Sofern die Wirksamkeit unverändert bleibt:
(7)
Die erzielten Ergebnisse für insgesamt 7 unterschiedliche Szenarien mit altersgruppenspezifisch variierten Impfquoten finden sich in den Abbildungen 20 und 21.
Tatsächliche und hypothetische Todesfallzahlen für 2021 bei unterschiedlichen Annahmen zur Höhe der Impfquote.
Abbildung 20: Tatsächliche und hypothetische Todesfallzahlen für 2021 bei unterschiedlichen Annahmen zur Höhe der Impfquote. Die Grafik zeigt die Summenwerte der Todesfallzahlen für sieben unterschiedliche Szenarien betreffend der Impfquoten über die Altersgruppen. Zum Vergleich sind die tatsächlichen Fallzahlen aus 2021 (Rubrik ganz links) aufgeführt. Die Säulen sind von links nach rechts nach der Höhe der Gesamtimpfquote geordnet. Ganz oben sind die jeweiligen Differenzen der Fallzahlen zum Vergleichswert aus 2021 notiert. Rohdaten: RKI, Datenstand 22.01.2022.
Man sieht, dass die Höhe der Impfquote allein nur eine begrenzte Aussagekraft im Hinblick auf die erzielbare Reduzierung der Fallzahlen besitzt. Die zweite Rubrik von rechts steht für eine Impfquote von 85%, dennoch liegen die Todesfallzahlen gleich hoch wie in 2021. Warum? Es sind die Falschen geimpft. Nicht die Alten, sondern die Jungen. Umgekehrt kann man mit einer Impfquote von nur 52% (hellgrüne Säule, vierte Rubrik von links) eine Verringerung der Anzahl der Todesfälle auf einem ähnlichen Niveau erzielen, wie das im Szenario mit 73% Impfquote (dunkelbaue Säule, fünfte Rubrik von links) oder im Szenario mit 90% Impfquote (grüne Säule, Rubrik ganz rechts) möglich ist. Entscheidend ist die Durchimpfung von den höheren zu den niedrigeren Altersgruppen.
In der letzten Grafik wird für die Fallzahlen in den betrachteten Szenarien zusätzlich die Unterscheidung in Geimpfte und Ungeimpfte vorgenommen. Dies wirft noch einmal ein Schlaglicht auf die Grenzen des durch eine hohe Impfquote Erreichbaren im Hinblick auf die am Ende verbleibenden Todesfallzahlen unter Ersteren. Anderes als manche das meinen, gehen die Fallzahlen nicht auf null, wenn es keine Ungeimpften mehr gibt. Die Todesfallinzidenzen reduzieren sich auch nicht auf 10 %, weil die angegebene Impfstoffwirksamkeit von 90 % eher ein theoretischer Wert ist, der z.B. aufgrund der nachlassenden Schutzwirkung in der Praxis nicht erreicht wird.
Ohne Zweifel hat eine hohe Impfquote einen bedeutsamen Effekt auf die Verringerung der Fallzahlen. Es bleibt aber immer noch eine beträchtliche und mit den verfügbaren Impfstoffen offenbar nicht weiter reduzierbare Anzahl von Sterbefällen, weil mit der Impfquote natürlich auch die Todesfallzahlen unter den Geimpften ansteigen. In Abb. 21 sieht man das ganz deutlich. Das spricht nicht gegen die Impfung, denn die Gesamtanzahl der Corona-Todesfälle geht auf jeden Fall zurück. Es relativiert aber den erwartbaren Erfolg.
Tatsächliche und hypothetische Todesfallzahlen (Geimpfte und Ungeimpfte) für 2021 bei unterschiedlichen Annahmen zur Höhe der Impfquote.
Abbildung 21: Tatsächliche und hypothetische Todesfallzahlen (Geimpfte und Ungeimpfte) für 2021 bei unterschiedlichen Annahmen zur Höhe der Impfquote. Die Grafik zeigt die Summenwerte der Todesfallzahlen für sieben unterschiedliche Szenarien betreffend der Impfquoten über die Altersgruppen. Die Säulen sind von links nach rechts nach der Höhe der Gesamtimpfquote geordnet. Grün: Anzahl der Todesfälle bei Geimpften. Orange: Todesfälle bei Ungeimpften. Orange-weiß: Verringerung der Gesamtfallzahlen im Vergleich zu den tatsächlichen Werten aus 2021 (Rubrik ganz links). Rohdaten: RKI, Datenstand 22.01.2022.
Mathematischer Anhang
Die altersabhängige Corona-Sterblichkeit bei Infektion (Letalität)
Die Letalität pro 100.000 Infizierten kann durch die folgende exponentiell-lineare Näherungsformel ausgedrückt werden:
(8)
Ausgedrückt in Prozentwerten lautet die Formel für die Letalität:
(9)
Für den Altersbereich 5-80 bleibt der absolute Fehler unter 0,25%. Der relative Fehler liegt für die Altersgruppe 20-80 meist unter 5%. Es gibt zwei Ausreißer mit einer Überschätzung des Risikos für die Altersgruppen 40-49 (30%) und 50-59 (22%).
Nach obiger Approximationsformel verzehnfacht sich der Letalitätswert pro 18 Lebensjahren. Verglichen mit einem 24-Jährigen hat demzufolge ein 42-Jähriger ein 10-fach, ein 60-Jähriger ein 100-fach und ein 78-Jähriger ein 1000-fach höheres Corona-Sterberisiko p.a. bei vorliegender Corona-Infektion. Für die richtige Einordnung sollte man die Höhe des absoluten Risikos nicht unerwähnt lassen. Es liegt bei 0,008% p.a. für 24-Jährige und folglich bei etwa 8% p.a. für 78-Jährige.
Dargestellt als Zweierpotenz ergibt sich . Daher kann man festhalten, dass sich das Corona-Sterberisiko p.a. bei vorliegender Infektion pro etwa 5,5 Lebensjahren verdoppelt.
Eine bessere Approximation an den Letalitätsverlauf bietet die nachstehende exponentiell-kubische Näherungsformel:
(10)
Für den Altersbereich 5-95 bleibt der absolute Fehler bis auf zwei Ausnahmen für die Altersgruppe 70-79 (0,65%) und 90+ (2,6%) unter 0,02%. Der relative Fehler ist für die Altersgruppen 20-29, 40-49, 60-69 und 80-89 kleiner als 0,0001%. Für die Altersgruppen 10-19, 30-39, 50-59, 70-79 und 90+ liegt er bei 33%, 19%, 5%, 10% bzw. 11%.
Die altersabhängige Corona-Sterblichkeit (Mortalität)
Eine exponentiell-lineare Näherungsformel für die Mortalität pro 100.000 Einwohnern ist durch die folgende Beziehung gegeben:
(11)
Ausgedrückt in Prozentwerten lautet die Formel für die Mortalität p.a.:
(12)
Für den Altersbereich 5-80 bleibt der absolute Fehler unter 0,005%, für 80-89 und 90+ liegt er bei 0,012% bzw. 0,1%. Der relative Fehler liegt für die Altersgruppe 30-90+ unter 8%. Für die Altersgruppe 20-29 wird das Risiko um 23% überschätzt, für die Altersgruppen 10-19 und 0-9 um 17% bzw. 65% unterschätzt. Das allerdings auf einem sehr niedrigen absoluten Risikoniveau unter 0,0005%.
Nach vorstehender Approximationsformel verzehnfacht sich der Mortalitätswert p.a. pro 22 Lebensjahren. Verglichen mit einem 18-Jährigen hat demzufolge ein 40-Jähriger ein 10-fach, ein 62-Jähriger ein 100-fach und ein 84-Jähriger ein 1000-fach höheres Corona-Sterberisiko p.a.. Um das richtig einzuordnen, muss man erwähnen, dass das absolute Risiko von 18-Jährigen bei etwa 0,0005% liegt, das von 84%-Jährigen bei 0,5%.
Wegen kann man ebenfalls konstatieren, dass sich das Corona-Sterberisiko p.a. pro etwa 6,5 Lebensjahren verdoppelt.
Das altersabhängige Corona-Infektionsrisiko
Eine passable exponentiell-lineare Näherungsformel für das Infektionsrisiko in Prozent kann folgendermaßen formuliert werden:
(13)
Für die Altersgruppen 30-39, 60-69 und 70-79 bleibt der absolute Fehler unter 0,25%, für 50-59 liegt er bei 0,7%, für 10-29 und 80-89 bei max. 2,2%. Etwas größer ist die Abweichung für die Altersgruppen 0-9 (8,5%) und 90+ (4,3%). Der relative Fehler bleibt für die Altersgruppe 10-90 unter 30%.
Die etwas größeren Abweichungen der linearen Näherungsformel bei den Älteren werden auf Basis der untenstehenden exponentiell-kubischen Approximation vermieden:
(14)
Für den Altersbereich 40-90+ bleibt der absolute Fehler der kubischen Näherung unter 0,6%. Die Approximation liegt für die Altersgruppen 0-39 um max. 3,3% daneben. Dabei bleibt der relative Fehler zwischen 20% (10-19) und 45% (0-9). Deutlich kleiner ist der relative Fehler für die Altersgruppen 40-59 (max. 2,4%) sowie 60-69 und 80-89 (<1%). Für die Altersgruppen 70-79 und 90+ liegt er bei max. 12,5%.
Im Unterschied sowohl zur Letalität wie auch zur Mortalität, die beide mit zunehmendem Alter exponentiell wachsen, sehen wir bezüglich des Infektionsrisikos ein gegenteiliges Verhalten: Je höher das Alter, desto geringer die Infektionswahrscheinlichkeit. Diese Abhängigkeit ist zwar nicht so stark und eindeutig ausgeprägt, sie führt aber dennoch dazu, dass das Infektionsrisiko mit dem Alter signifikant zurückgeht. Vermutlich deswegen, weil Ältere im Allgemeinen weniger Kontakte haben oder sich bei ihren Kontakten besser schützten.
Ganz grob kann man sagen, dass sich die Infektionswahrscheinlichkeit p.a. pro 30 Lebensjahren in etwa halbiert. Ein Blick auf die Zweierpotenz-Näherungsformel macht das unmittelbar klar.
(15)
Für die Lebensalter 20 – 80 ist die Approximation nahe an der Realität.
Bestimmung der Letalitäten für Geimpfte und Ungeimpfte bei unzureichender Erfassung des Impfstatus
Die Letalität für alle Infizierten sowie die Letalitäten für die infizierten Geimpften und Ungeimpften sind folgendermaßen definiert:
(16)
Der Wert für ergibt sich direkt aus den Statistiken des RKI. Da indessen die Impfstatus der Infizierten und der Verstorbenen in 2021 nicht konsequent erfasst wurden (jedenfalls wurden diese Zahlen vom RKI nicht veröffentlicht), können die Letalitätswerte der Geimpften und der Ungeimpften nicht unmittelbar aus dem Datenmaterial des RKI bestimmt werden. Über einen kleinen Umweg ist es indes möglich, die Zahl der infizierten und verstorbenen Geimpften, und , zu berechnen. Gleiches geht auch für die Ungeimpften ( und ).
Dabei sind und die entsprechenden Impfstoff-Wirksamkeiten für den Schutz vor Infektion und den Schutz vor Tod.
Für die Anzahl der Ungeimpften ergibt sich analog
(18)
(19)
Die unbekannten Letalitäten der Geimpften und der Ungeimpften können nun leicht aus den vorstehenden Formeln bestimmt werden:
(20)
Und somit
(21)
sowie
(22)
(23)
Das Verhältnis der beiden Letalitäten ergibt sich zu
(24)
Datengrundlage für die Berechnung der Letalitäten
Die altersgruppenspezifischen Impfquoten und Wirksamkeiten sind grundsätzlich bekannt. Die Impfkampagne begann Anfang 2021, so dass im Hinblick auf die Anwendung der obigen Formel zur Bestimmung der Letalitätswerte für das Gesamtjahr mittlere Impfquoten abgeschätzt werden müssen. Dasselbe gilt für die Wirksamkeiten bezüglich es Infektionsschutzes und des Schutzes vor Tod. Die betreffenden Annahmen sind in Tab. 1 (s.o.) aufgelistet.
Bestimmung der Todesfallzahlen für Geimpfte und Ungeimpfte
Nach obigen Formeln erhalten wir für die Anzahl der verstorbenen Geimpften und Ungeimpften zusammenfassend die folgenden Beziehungen:
(25)
Die simple Mathematik zum Effekt von Massenimpfungen
Der Quotient bringt die Wirkung der Massenimpfung in kompakter Form zum Ausdruck:
(26)
Für und für gibt es keine verstorbenen Geimpften, für gibt es keine Ungeimpften.
Das relative Sterberisiko von Geimpften im Vergleich zu Ungeimpften ist . Daher sind die Todesfallzahlen bei Geimpften und Ungeimpften gleich hoch, wenn das Zahlenverhältnis zwischen Geimpften und Ungeimpften reziprok proportional zum Verhältnis der Todesfallrisiken ist, wenn also
(27)
Die Anzahl der Todesfälle von Ungeimpften überwiegt, sofern die linke Seite kleiner ist. Das ist sicher dann der Fall, wenn die Impfquote die Wirksamkeit nicht übersteigt. Umgekehrt gibt es mehr Todesfälle bei Geimpften, wenn das Zahlenverhältnis zwischen Impfquote und „Nicht-Impfquote“ über den Wert für das Risikoverhältnis auf der rechten Seite hinauswächst.
Der Zusammenhang gilt auch ganz allgemein für Infizierte oder Hospitalisierte.
(28)
Herleitung der zu erwartenden Infektions- und Todesfallzahlen bei einer geänderten Impfquote und Wirksamkeit des Impfstoffs
Es stellt sich die Frage, wie sich denn die Todesfallzahlen in 2021 entwickelt haben würden, wenn die Imfpquote höher oder niedriger gewesen oder die Wirksamkeit des Impfstoffs eine andere gewesen wäre. Natürlich ist diese Frage spekulativ. Dennoch kann man sich der Antwort nähern und begründete Aussagen zum Effekt solcher Änderungen auf die Todesfallzahlen ableiten. Ausgangspunkt ist das oben formulierte Invarianz-Postulat.
Im Folgenden bestimmen wir die zu erwartenden Infektions- und Todesfallzahlen bei modifizierter Impfquote und Impfstoffwirksamkeit. Das versetzt uns in die Lage, Was-Wäre-Wenn-Analysen durchzuführen.
Grundformeln für Ableitung der hypothetischen Infektions- und Todesfallzahlen
Die modifizierte Impfquote bezeichnen wir mit , die geänderte Wirksamkeit für den Schutz vor Infektion nennen wir . Der Einfachheit halber verzichten wir dabei auf das Subskript, wenn es aus dem Zusammenhang heraus keine Verwechslungen geben kann; meint also .
Wir fragen nach dem formelmäßigen Zusammenhang zwischen den neuen Infektions- und Todesfallzahlen bei der Impfquote und der Infektionsschutz-Wirksamkeit und den Bezugswerten bei der Impfquote und der Wirksamkeit . Dabei setzen wir eine unveränderte Wirksamkeit bezüglich des Schutzes vor Tod voraus. Die neuen Infektions- und Todesfallzahlen bezeichnen wir mit , , , die Bezugswerte mit , , .
Wir erhalten die folgenden Beziehungen:
(29)
Erläuterung und Plausibilisierung der Beziehungen
Zur Motivation der Formeln betrachten wir eine Kohorte von 1000 Personen, 400 Geimpften und 600 Ungeimpften. Die Impfquote ist daher 40%. Der Infektionsschutz möge bei 60% liegen. Nehmen wir an, 30 Ungeimpfte seien infiziert. Demnach gibt es nun also infizierte Geimpfte. Wenn wir nun die Impfquote auf 70% erhöhen, dann haben wir 700 Geimpfte und nur noch 300 Ungeimpfte. Entsprechend geht die Zahl der infizierten Ungeimpften auf zurück. Zugleich steigt die Anzahl der infizierten Geimpften auf .
Die Anzahl der infizierten Ungeimpften verändert sich demnach proportional zur Quote der Nicht-Geimpften, wie man das intuitiv erwartet. Im Beispiel ist das der Faktor . Auf der anderen Seite wird die Anzahl der infizierten Geimpften entsprechend im Verhältnis der Impfquoten erhöht.
Wenn sich die Wirksamkeit verändert, hat das offensichtlich keinen Einfluss auf die Anzahl der infizierten Ungeimpften. Doch wie verhält es sich bei den Geimpften? Gehen wir noch einmal zum obigen Beispiel und lassen nun die Impfquote konstant bei 40%, verändern aber die hypothetische Wirksamkeit von 60% auf 80%. Im Ergebnis sinkt die Anzahl der infizierten Geimpften auf . Ihre Anzahl verändert sich daher proportional zum Verhältnis der Restrisiken. Im Beispiel . Zugleich sinkt die Gesamtzahl der Infizierten von auf .
Wenn sowohl die Impfquote als auch die Wirksamkeit modifiziert werden, so ändert sich gegenüber den beiden Beispielen nichts bei den Ungeimpften, ihre Zahl geht auf zurück. Die Zahl der infizierten Geimpften verändert sich dagegen proportional zum Verhältnis auf .
Werfen wir noch einen kurzen Blick auf die Gesamtzahl der Infizierten. Im ersten Beispiel sinkt sie von auf . Das ist das Verhältnis . Analog im zweiten Beispiel: Die Gesamtzahl der Infizierten verringert sich von auf und geht damit proportional zum Verhältnis zurück. Schließlich stellt sich im dritten Fall bei der gleichzeitigen Veränderung von Impfquote und Wirksamkeit die neue Anzahl der Infizierten, also , entsprechend dem Verhältnis ein.
Formeln für die Bestimmung der Infektionszahlen Geimpfter und Ungeimpfter
Kommen wir zurück zur Berechnung der Anzahl der infizierten Geimpften und Ungeimpften. Für die Fallzahlen bei Änderung der Impfquote und der Wirksamkeit erhalten wir
(30)
Formeln für die Bestimmung der Todesfallzahlen Geimpfter und Ungeimpfter
Im Weiteren können wir auf Basis obiger Formeln auch die Höhe der zu erwartenden Todesfallzahlen der infizierten Geimpften und Ungeimpften nach einer Modifikation von Impfquote und Wirksamkeit direkt aus den Werten für die Gesamtzahl der Infizierten vor der Veränderung errechnen. Wie oben bezeichnen wir die neuen Todesfallzahlen mit , , und die Bezugswerte mit , , .
(31)
(32)
Diese Beziehungen können wir nur deswegen so formulieren, weil sich die Letalitäten für die Geimpften und Ungeimpften im betrachteten Szenario nicht verändern, weil also und . Das Invarianz-Postulat wurde oben erläutert. Für die Gesamtletalität gilt dagegen .
Die Bestimmung der Gesamtletalität bei geänderter Impfquote und Wirksamkeit
Zur Bestimmung von gehen wir aus von
(33)
Wegen
(34)
bekommen wir für den Ausdruck
(35)
Die Gesamtletalität bei geänderter Impfquote und gleicher Wirksamkeit
Für vereinfacht sich die -Formel auf
(36)
womit sich der Zusammenhang zwischen den nach der Modifikation zu erwartenden Todesfallzahlen und den ursprünglichen Infektionszahlen für diesen Spezialfall deutlich kürzer fassen lässt:
Es scheint klar: Infektionstreiber sind die Ungeimpften
In den letzten Wochen gab es vermehrt Diskussionen darüber, wer denn nun hauptverantwortlich für die hohen Inzidenzen sei, die Ungeimpften oder die Geimpften? Für die Medien und die Politik scheint der Fall ziemlich eindeutig: Es sind die Ungeimpften. Tenor: Die Ungeimpften verweigern die Solidarität und gefährden sich und andere. Untermauert wurde das Ganze durch entsprechende Presseberichte und die Veröffentlichung von separaten Inzidenzzahlen für Geimpfte und Ungeimpfte. Dabei kam fast immer heraus: Die Inzidenzen für Ungeimpfte liegen teilweise um den Faktor 10 und mehr höher als bei den Geimpften.
Scheinbar dramatisch hohe Inzidenzen bei Ungeimpften in Bayern
Betrachten wir exemplarisch die Zahlen in Bayern vom 24.11.2021. Laut dem Bayerischen Landesamt für Gesundheit und Lebensmittelsicherheit (LGL) wurden für diesen Tag die folgenden Zahlen ausgewiesen.
Infektionszahlen vom 24.11.2021 in Bayern
Tabelle 1: Infektionszahlen vom 24.11.2021 in Bayern. Quelle: Bayerischen Landesamt für Gesundheit und Lebensmittelsicherheit (LGL).
Inzidenz für Geimpfte 110, für Ungeimpfte aber 1469. – Das ist schon ein eklatanter Unterschied. Und die Differenz war auch an anderen Tagen erheblich. So berichtete die Augsburger Allgemeine am 11.11.2021 unter dem Titel „So viel häufiger stecken sich Ungeimpfte mit Corona an“ unter Berufung auf das LGL von einer noch größeren Divergenz: „Inzidenz der Ungeimpften in Bayern liegt bei 1616 – die der Geimpften bei 103“. Dabei hat man auch nicht vergessen, Impfskeptikern den Segen der Impfung nahezubringen, wo doch die Zahlen so offensichtlich seien. Gleichartig die Süddeutsche Zeitung am 19.11.2021.
Bayern ist kein Einzelfall: hohe Inzidenzen bei Ungeimpften auch anderswo
In anderen Bundesländern ein ähnliches Bild: Hamburg gibt am 24.11.2021 für die Geimpften eine Inzidenz von 223 an, für die Ungeimpften aber 715. Solche Zahlen empören Journalisten im öffentlich rechtlichen Rundfunk, die daraufhin die allgemeine Impfpflicht fordern. Offenbar, weil man ja anders den uneinsichtigen Ungeimpften nicht beikommen kann.
Dann wird das wohl so stimmen, mag der wohlmeinende Bürger dazu sagen. Eine staatliche Behörde wird doch keine Falschmeldungen verbreiten. Und wenn es eine Falschinformation wäre, würden doch nicht nahezu alle Medien solche Zahlen quasi ungeprüft wiederholen. Leider ist genau das eingetreten – zumindest war dies über viele Wochen der Fall. Erst Anfang Dezember ist aufgefallen, dass die Zahlen so nicht stimmen können. Und dies aus mehreren Gründen.
Analyse der exemplarischen bayerischen Zahlen
Kehren wir zurück zum o.g. Beispiel aus Bayern. Bei der Berechnung für den 24. November wurden gut 72 000 Personen als ungeimpft in die Rechnung mit einbezogen. Tatsächlich war aber für mehr als 57 000 davon der Impfstatus unbekannt. Man hat also kurzerhand den Impfstatus dieser Personengruppe auf „ungeimpft“ gesetzt. Natürlich kann dies das Ergebnis massiv verzerren: Die Sieben-Tage-Inzidenz der Geimpften könnte tatsächlich viel höher, die der Ungeimpften deutlich niedriger sein.
Wenn man im Beispiel nur die Personen mit bestätigtem Impfstatus nimmt, dann verbleiben lediglich 15.000 Ungeimpfte. Im Ergebnis reduziert sich die Inzidenz der Ungeimpften von 1469 auf 306 (auch dieser Wert ist noch systematisch überhöht, dazu weiter unten). Diese Zahl liegt jetzt sehr viel näher an dem für die Geimpften angegebenen Wert von 110. Wobei man berücksichtigen muss, dass Geimpfte seltener getestet werden als Ungeimpfte. Und selbstverständlich könnten unter den Personen mit unbekanntem Impfstatus auch viele Geimpfte sein, was die Inzidenz der Geimpften erhöhen würde.
Die Einsicht kommt spät – und sie kommt nur halbherzig
Wie oben schon erwähnt, ist dies leider kein bayerischer Sonderfall. In allen Bundesländern bestehen oder bestanden Ungereimtheiten betreffend die separate Berechnung von Inzidenzen für Geimpfte und Ungeimpfte. Nachdem das offenbar geworden war, findet man z.T. absurde Ausflüchte. So kontert der bayerische Gesundheitsminister Holetschek die entsprechende Kritik der FDP an der Zurechnung der Personen mit unbekannten Impfstatus zu den Ungeimpften mit dem Satz: „Es handle sich um eine fachliche Frage, über die man aber streiten und diskutieren könne“. Da fehlen einem die Worte.
Das ist in etwa so, als würde sich der Steuerbetrüger damit rechtfertigen, er habe einfach nur eine fachlich andere Ansicht zur Steuerpflicht auf seine Einkünfte gehabt, deswegen handle es sich gar nicht um Steuerhinterziehung.
Ebenso kreativ ist der Erste Bürgermeister der Hansestadt Hamburg. Er nennt einen technischen Fehler, eine „IT-Panne“, als Grund für die scheinbar irrtümlicherweise Ungeimpften zugerechneten Infektionsfälle (s. Focus). „Scheinbar“, also „barer Schein“ und damit nur „dem Schein nach unabsichtlich“ ist an dieser Stelle vermutlich eine sehr treffende Vokabel.
Grundsätzliches zu den Inzidenzen für Ungeimpfte
Wie wir gesehen haben, wurden die offiziell ausgewiesenen Inzidenzzahlen für Ungeimpfte mehr oder weniger absichtsvoll künstlich in die Höhe getrieben. Damit allerdings nicht genug. Es gibt darüber hinaus noch einen weiteren Kritikpunkt, der selbst bei korrekter Zählung der Infektionszahlen nach Impfstatus ins Gewicht fällt und geeignet ist, die Inzidenzen der Ungeimpften gegenüber den Geimpften massiv zu verzerren.
Es ist Usus, die Inzidenz für die Ungeimpften und die Geimpften jeweils auf 100.000 Ungeimpfte bzw. Geimpfte zu beziehen. Zunächst klingt das durchaus vernünftig. Tatsächlich ist es aber nicht sachgerecht, die Inzidenzen für Geimpfte und Ungeimpfte auf die jeweiligen Gruppengrößen zu beziehen, denn für das Infektionsgeschehen sind die absoluten Zahlen der Neuinfizierten relevant, nichts sonst. Die Infektionsdynamik wird bestimmt durch die Summe der aktuell Infektiösen und offensichtlich nicht durch die Anzahl die Infizierten in einer wie auch immer abgegrenzten Bevölkerungsgruppe. Dennoch wird diese doch eigentlich recht triviale Erkenntnis weitgehend ignoriert.
Gewollt oder ungewollt wird das teilweise noch weiter verschleiert, indem nicht immer scharf zwischen dem Inzidenzwert bezogen auf 100.000 Ungeimpfte und der Inzidenzangabe bezogen auf 100.000 Einwohner unterschieden wird.
Am Beispiel der nachstehenden Grafik von Statista kommt diese Unschärfe erst beim zweiten Blick zum Ausdruck. Dabei sind die Ausgangsdaten des RKI, auf die sich Statista hier bezieht, diesbezüglich unmissverständlich klar.
Statista Infografik – Inzidenzen Ungeimpft vs. Geimpft
Abbildung 1: Höhere Inzidenzen bei Ungeimpften. Symptomatische COVID-19-Fälle nach Impfstatus. Statista Infografik vom 13.12.2021. Anmerkung: Die in der Grafik vermittelte Information ist so nicht richtig. Zur Korrektur s. Abb. 3.
In der Überschrift zur Statista-Grafik ist angegeben: „Symptomatische COVID-19-Fälle pro 100.000 Einwohner:innen“ (Anmerkung: „Einwohner:innen“ ist der Statista-Code für „Einwohner“). Richtig ist aber „Symptomatische COVID-19-Fälle pro 100.000 Ungeimpften bzw. Geimpften der Altersgruppe“. Das macht einen erheblichen Unterschied, wie wir gleich sehen werden.
Beispiel zur Inzidenzberechnung für Ungeimpfte und Geimpfte
Um die Problematik an einem Beispiel plausibel zu machen, nehmen wir eine Stadt mit 100.000 Einwohnern, etwa Siegen, Hildesheim, Gütersloh, Kaiserlautern oder Cottbus. Aktuell seien im 7-Tage-Intervall 500 Menschen als neuinfiziert gemeldet. Offensichtlich sind genau diese 500 Personen kausal für die Ausbreitungsdynamik in der Stadt relevant. Und natürlich haben wir auch eine Inzidenz von 500. Was wird nun offiziell daraus gemacht?
Die Impfquote in der Stadt betrage 75 %. Nehmen wir ferner an, die eine Hälfte der 500 seien geimpft, die andere Hälfte ungeimpft. Für die Inzidenzen der Geimpften erhalten wird jetzt 250/0,75 = 333, und für die Ungeimpften 250/0,25 = 1000. Die Stadt wird also sagen, die Inzidenzen der Ungeimpften liegen dreimal höher als die der Geimpften. Dabei ist es unabweisbar Fakt, dass es in beiden Gruppen gleichviele Infizierte gibt und sie folglich auch gleich stark zur Infektionsdynamik beitragen.
Nehmen wir für ein weiteres kleines Gedankenspiel an, in Deutschland seien alle geimpft bis auf einen kleinen Rest von 100.000. Sofern nun bei diesen Ungeimpften 1000 Personen positiv getestet werden, haben wir also eine spezifische Ungeimpften-Inzidenz von 1000. Das hört sich bedrohlich an. Tatsächlich bedeutet dies, dass die allgemeine auf die Bevölkerung bezogene Inzidenz lediglich 1,2 beträgt. Und es ist nur die letztere Zahl, die für den allgemeinen Corona-Risikostatus von Bedeutung ist.
Systematische Verzerrung der Inzidenzen
Im Grundsatz wird damit das Kernproblem der verzerrten Inzidenzzahlen offenbar. Tatsächlich haben wir derzeit eine allgemeine Impfquote von 67 % – 70 %. Damit erscheinen die Inzidenzen der Ungeimpften ca. um den Faktor 3 vergrößert. Wenn man die Inzidenzen auf Altersgruppen bezieht – was zum Zwecke der Analyse durchaus sinnvoll ist – dann vergrößert sich die Schieflage u. U. noch weiter, da die altersgruppenspezifischen Impfquoten teilweise höher liegen.
Betrachten wir exemplarisch die Altersgruppe 60+. Die hohe Impfquote von 86 % führt hier zu einer Verfälschung der Ungeimpften-Inzidenzen um den Faktor 7 (= 1/(1-0,86)). Statt 50 wird dann z.B. eine Inzidenz von 350 ausgewiesen. Das ist eine eindeutige Aussage zuungunsten der Ungeimpften, sozusagen eine Zusatzlast auf ihr Sündenkonto. Der Beitrag der Ungeimpften an der Infektionsdynamik wird so optisch massiv überhöht. Rational ist das nicht. Der Anteil der Ungeimpften liegt in diesem Falle bei einer Inzidenz von 50, und nichts sonst. Angesichts der Stimmungslage ist die Angabe der überhöhten Inzidenz keine objektive und wertfreie Information. M. E. muss man hier die Intention der Meinungsmanipulation unterstellen. Zumindest ist es eine Form von Zahlenmanipulation oder „kreativer Statistik“.
Die korrigierten Zahlen zum obigen Beispiel aus Bayern
Kehren wird zurück zum obigen Beispiel aus Bayern. Nach Abzug der Getesteten mit unbekanntem Impfstatus hatten wir die erwiesene spezifische Inzidenz der Ungeimpften schon auf 306 korrigiert. Wenn man sich nun noch auf 100.000 Personen der Bevölkerung bezieht, dann erhält man auf Basis der bayerischen Impfquote von Ende November (66,5 %) eine weiter reduzierte tatsächliche Ungeimpften-Inzidenz von 306*0,335 = 102,51. Das ist nicht wesentlich mehr als die gleichfalls korrigierte Inzidenz unter den Geimpften, die sich zu 110*0,665 = 73 bestimmt. Aus dem ursprünglich von der Behörde angegebenen Inzidenz-Zahlenverhältnis Ungeimpft : Geimpft von 1468:110 wird nun also 103:72.
Bayerische Inzidenzahlen für Ungeimpfte und Geimpfte vom 24.11.2021
Abbildung 2: Bayerische Inzidenzahlen für Ungeimpfte und Geimpfte vom 24.11.2021, vor (Rubrik links) und nach (mittige Rubrik) der Aufdeckung der Falschzuweisung von Personen mit unbekanntem Impfstatus zu den Ungeimpften. Die Rubrik ganz rechts zeigt die im Hinblick auf die Infektionsdynamik relevanten Inzidenzwerte bezogen auf 100.000 Einwohner. In den Ellipsen ist jeweils das resultierende Verhältnis der Inzidenzen von Ungeimpften und Geimpften eingetragen.
Es soll noch einmal ausdrücklich hervorgehoben werden: Die Wahrheit zum Infektionsgeschehen steckt ausschließlich in der rechten Rubrik des Diagramms von Abb. 2.
Ungeimpfte versus Geimpfte: Der Blick wird klarer
Die in vielen Medien veröffentlichten und von einigen Bundesländern erhobenen Inzidenzen zu Geimpften und Ungeimpften sind, wie man an diesem Beispiel und der obigen Diskussion sieht, offensichtlich nicht vertrauenswürdig. Eher verlässlich sind die vom RKI publizierten Zahlenwerte zu den symptomatischen Inzidenzen. Symptomatisch infiziert heißt, die Betroffenen weisen Symptome auf und sind positiv getestet. Bei diesem Personenkreis wird der Impfstatus erfasst. Jedenfalls trifft das für etwa 84 % der Fälle zu. Es gibt also immer noch eine Unsicherheit, aber sie erscheint tolerabel. Die symptomatischen Inzidenzen sind somit ein vernünftiger Ausgangspunkt für die Beurteilung der Infektionsdynamik im Hinblick auf Geimpfte und Ungeimpfte.
Oben hatten wir auf die nach Altersgruppen aufgesplitteten symptomatischen Inzidenzen für Ungeimpfte und Geimpfte in Kalenderwoche 47 (s. Abb. 1) abgehoben. Es war schon angemerkt worden, dass hier die spezifischen Inzidenzen dargestellt sind (also die Entsprechung zur mittleren Rubrik in Abb. 2). Das werden wir aber gleich korrigieren (s. Abb. 3).
Korrigierte Inzidenzen für Ungeimpfte und Geimpfte zur Statista Infografik
Abbildung 3: Korrigierte Inzidenzen für Ungeimpfte und Geimpfte hinsichtlich symptomatischer COVID-19-Fälle in KW 47 mit ausgewertetem Impfstatus. Korrektur zur eingebetteten Statista Infografik vom 13.12.2021 (s. Abb. 1). Man beachte die eklatanten Unterschiede bezüglich der Verhältnisse der Inzidenzen in den beiden Grafiken (s. Pfeile bei den Altersgruppen 18-59 und 60+).
Wie man Abb. 3 entnimmt, liegen die auf 100.000 Einwohner bezogenen Zahlenwerte deutlich niedriger als die auf die jeweiligen Gruppen bezogenen Inzidenzen (s. Abb. 1). Es zeigt sich eine gänzlich andere Botschaft als die von der Originalgrafik suggerierte. Besonders auffallend ist, dass nun die Inzidenzen der Geimpften höher liegen als die der Ungeimpften. Lediglich in der Altersgruppe 12-17 ist das nicht so, sie ist indes mit ca. 4,5 Mio. Individuen eine kleine Gruppe und schlägt daher in der Gesamtschau (Rubrik rechts: alle) nicht durch. Insgesamt können wir daher festhalten, dass im Hinblick auf die symptomatischen Inzidenzen Ungeimpfte und Geimpfte die Infektionsdynamik in etwa gleicher Stärke bestimmen.
Was sagt die Wissenschaft zum Anteil der Ungeimpften am Infektionsgeschehen?
In einer neuen Studie der Humboldt-Universität Berlin wird deutlich der hohe Anteil der Ungeimpften an der Infektionsdynamik hervorgehoben. Darüber wird z.B. so berichtet:
„Eine neue Studie zeigt, wie Geimpfte auf das Infektionsgeschehen einwirken: Nicht besonders stark“ (SZ).
„Ungeimpfte am Großteil der Corona-Neuinfektionen beteiligt“ (SWR).
Oder: „Ungeimpfte an bis zu 90 Prozent aller Infektionen beteiligt“ (ntv).
Die letzte Aussage noch kürzer und prägnanter formuliert „Ungeimpfte (sind) an 8 bis 9 von 10 Neuinfektionen beteiligt“. – Das ist schon eine ziemlich klare Ansage zur Verantwortlichkeit am Infektionsgeschehen. Die Infektionstreiber sind also offenbar die Ungeimpften.
Doch ist das so eindeutig? Kann man das der Studie tatsächlich entnehmen? Oder werden hier Modellrechnungen überinterpretiert?
Wie entsteht ein mathematisches Modell?
Das grundsätzliche Vorgehen hinsichtlich des Modellaufbaus ist üblicherweise etwa folgendermaßen: Auf der Basis von Annahmen über die Infektionswege, Annahmen über die Kontakthäufigkeit von Ungeimpften und Geimpften, Annahmen über die Wahrscheinlichkeit einer Ansteckung unter Ungeimpften, unter Geimpften und zwischen den beiden Gruppen wird ein mathematisches Modell formuliert, das diese angenommenen Verhältnisse anhand von formelmäßigen Beziehungen adäquat widerspiegelt.
Mittels des Modells wird dann untersucht, ob die beobachteten Inzidenzen und ihre dynamische Entwicklung auf diese Weise nachgebildet werden können. Anschließend werden die Modellannahmen und ggf. die Zusammenhänge so lange verändert, bis sich eine gute Übereinstimmung zwischen den tatsächlichen Infektionszahlen und den vom Modell errechneten Zahlen ergibt.
Sofern dieses Ziel erreicht ist, darf man es in erster Näherung für plausibel halten, dass das aufgestellte mathematische Modell die realen Zusammenhänge angemessen abbildet. Ob es sich indes tatsächlich so verhält, ist damit nicht bewiesen. Es ist i. A. sogar absolut unsicher, inwiefern ggf. andere Annahmen oder modifizierte Modellparameter zum selben Ergebnis führen könnten.
Modellrechnung versus Feldbeobachtung
Zunächst einmal muss man festhalten, dass die Aussage der Studie, an 9 von 10 Corona-Ansteckungen seien Ungeimpfte beteiligt, nicht das Ergebnis einer Feldbeobachtung ist. Es handelt sich vielmehr um das Resultat aus einer Modellierung. Ob die Modellaussage richtig oder falsch ist, hängt davon ab, inwiefern die Modellannahmen zutreffend sind.
Insofern im Modell die Annahme getroffen wird, Ungeimpfte seien erheblich ansteckender als Geimpfte, wird das Modell natürlich auch das Ergebnis ausweisen, dass Ungeimpfte deutlich häufiger als Geimpfte Verursacher von Infektionen sind. Im Allgemeinen wird durch die Wahl der Eingangsparameter das Modellverhalten und damit auch das Untersuchungsergebnis wesentlich vorherbestimmt – wäre es anders, brauchte man das Modell nicht.
Modelle haben beschreibenden Charakter, sie können (möglicherweise) mathematisch abbilden, was man beobachtet, und können unter Umständen z. B. zur Vorhersage künftiger Entwicklungen eingesetzt werden. Prinzipbedingt kann ein Modell aber keinen Beweis liefern.
Es ist also keineswegs evident, dass „an 9 von 10 Corona-Ansteckungen Ungeimpfte beteiligt sind“, vielleicht ist es lediglich eine mögliche Erklärung für die beobachtete Entwicklung der Infektionszahlen – sofern sonst alles richtig gemacht wurde und – das ist ganz wichtig – die Annahmen in der Realität zutreffen.
Kurzanalyse zur zentralen Modellaussage
Was heißt eigentlich, Ungeimpfte seien „an 9 von 10 Corona-Ansteckungen beteiligt“? Das ist eine etwas spitzfindige Formulierung, denn es wird ja nicht gesagt, dass 9 mal mehr Ungeimpfte als Geimpfte infiziert seien. Es wird damit auch nicht behauptet, Geimpfte seien nur an einer von 10 Ansteckungen beteiligt, obwohl man sicher sein kann, dass nicht wenige genau diesen Schluss daraus ziehen werden.
Wie dem auch sei, die Aussage könnte man etwa folgendermaßen ausdeuten:
(1) Ein Ungeimpfter infiziert 9 Geimpfte, und einer der Geimpften infiziert einen weiteren Geimpften. Dann waren also die Ungeimpften an 9 von 10 Ansteckungen beteiligt.– Das ist die ausgesprochene Botschaft, wie sie sich in den Köpfen festsetzt. Nebenbei bemerkt, aber das geht unter: In diesem Falle sind die Geimpften bei 10 von 10 Übertragungen direkt involviert.
Es könnte aber auch so sein:
(2) Ein Ungeimpfter infiziert 5 andere Ungeimpfte und 4 Geimpfte. Einer der Geimpften infiziert einen weiteren Geimpften. Es gibt 10 Ansteckungen, an 9 davon 10 waren Ungeimpfte beteiligt.Zum Vergleich: Geimpfte waren nur in 5 Ansteckungen involviert.
Oder so:
(3) 5 Geimpfte infizieren 5 Ungeimpfte und einen Geimpften. Vier Ungeimpfte infizieren 4 andere Ungeimpfte. Wieder sind Ungeimpfte an 9 von 10 Ansteckungen beteilig, Geimpfte an 6 von 10.
Vielleicht auch so:
(4) 10 Geimpfte infizieren 9 Ungeimpfte und einen weiteren Geimpften. An 9 von 10 Ansteckungen waren wieder Ungeimpfte beteiligt, Geimpfte aber an 10.
Oder gar so:
(5) Ein Geimpfter infiziert einen anderen Geimpften und 9 Ungeimpfte. Dann waren also die Ungeimpften ebenso an 9 von 10 Ansteckungen beteiligt, Geimpfte waren immer dabei. – Diese Lesart drängt sich nicht auf, sie steht aber nicht im Widerspruch zur zentralen Aussage.
Was sagen die Felddaten?
Unabhängig von der vorstehenden – zugegebenermaßen sophistischen – Relativierung der Studienaussage, darf man ernsthafte Zweifel an eben diesem zentralen Resultat, Ungeimpfte seien „an 9 von 10 Corona-Ansteckungen beteiligt“, anmelden. Ein Befund, der insbesondere in dieser zugespitzten Form geeignet ist, die einseitige Schuldzuweisung an Ungeimpfte weiter zu verfestigen. So als sei diese Gruppe alleinverantwortlich für die teilweise hohen Inzidenzen. Und dies ohne wirklich belastbare Belege.
Nach Meinung des Autors legen die Fakten eine andere Sicht nahe.
Laut Daten des RKI wurden z.B. für die Kalenderwoche 45 insgesamt 84.000 Fälle mit symptomatischer Erkrankung an Covid-19 gemeldet, davon 41.500 Ungeimpfte und 42.500 Geimpfte. Diverse Feldstudien belegen, dass sich bei etwa einem Drittel der Infizierten eine Symptomatik ausbildet. Demnach kann die Anzahl der infizierten Ungeimpften in KW 45 auf ca. 125.000 taxiert werden. Wenn man nun davon ausgeht, dass Geimpfte einen mindestens 50-prozentigen Schutz vor einer symptomatischen Erkrankung aufweisen, dann müssen ursprünglich sogar 255.000 (= 42.500*3*2) Geimpfte als Infizierte gezählt werden. Mithin entfallen auf einen infizierten Ungeimpften zwei infizierte Geimpfte.
Das ist ein ganz anders Bild als das aus dem Modell abgeleitete. Abbildung 4 zeigt den aus den genannten RKI-Daten resultierenden Inzidenzverlauf für Geimpfte und Ungeimpfte über mehrere Wochen hinweg. Man erkennt, dass die Inzidenzen für Geimpfte und Ungeimpfte bis zu KW 40 nicht wesentlich voneinander abweichen. Danach steigen die Inzidenzen der Geimpften stärker an und liegen aktuell knapp doppelt so hoch wie die der Ungeimpften.
Korrigierte Inzidenzen für Ungeimpfte und Geimpfte errechnet auf Basis der symptomatischen COVID-19-Fälle nach Daten des RKI
Abbildung 4: Korrigierte Inzidenzen für Ungeimpfte und Geimpfte errechnet auf Basis der symptomatischen COVID-19-Fälle nach Daten des RKI von KW 28 bis KW 47. Die angegebenen Inzidenzwerte sind ggf. höher als die jeweils veröffentlichten Infektionszahlen. Das rührt daher, dass die vorliegenden Inzidenzen hochgerechnet sind und daher auch Anteile der Dunkelziffer an Infektionen enthalten können.
Welche Folgerungen kann man daraus ziehen?
Die aus den Daten des RKI bestimmte Relation zwischen der Anzahl der infizierten Ungeimpften und Geimpften entspricht bei der gegenwärtigen Impfquote in etwa dem Zahlenverhältnis zwischen Ungeimpften und Geimpften in der Bevölkerung (etwa 1:2).
Wenn also die absolute Zahl der infektiösen Geimpften doppelt so groß ist, wie die Zahl der infektiösen Ungeimpften, dann darf man davon ausgehen, dass in der Realität, also abseits der oben exemplifizierten Kasuistik, Geimpfte im Vergleich zu den Ungeimpften auch einen entsprechend hohen Anteil am Infektionsgeschehen haben. Das ist jedenfalls plausibel. Es ist kaum vorstellbar, dass die Kausalität für diese hohe Infektionszahl bei den Geimpften zu fast 90 % auf Ungeimpfte zurückzuführen sein sollte. Sofern dies zuträfe, müsste sich dies auch in sehr hohen Inzidenzen der Ungeimpften zeigen.
Auch im internationalen Vergleich gibt es nach derzeitigem Stand keine greifbare Wechselbeziehung zwischen Inzidenzahlen und Impfquoten (s. [20]). Würde es eine Korrelation geben, dann müssten Länder mit hoher Impfquote, also zahlenmäßig wenigen Ungeimpften, i.A. niedrige Inzidenzen aufweisen. Das ist nicht der Fall.
Ein plausibles Alternativmodell
Eigene Modellüberlegungen (s. Anhang) basierend auf einem differenzierten Ansatz nach Altersgruppen und Impfstatus deuten auf eine in etwa ausgeglichene Kausalität der Ansteckungen zwischen Geimpften und Ungeimpften hin. Jedenfalls dann, wenn man von der Annahme ausgeht, infizierte Geimpfte seien um 50 % weniger ansteckend als Ungeimpfte und ihrerseits im Vergleich zu Ungeimpften um 50 % vor einer Ansteckung geschützt. Die Ergebnisse dazu finden sich in Abb. 5.
Aus Modellanalysen abgeleitete relative Häufigkeiten der Übertragungswege Ungeimpft-Ungeimpft (U-U), Ungeimpft-Geimpft (U-G), Geimpft-Ungeimpft (G-U) und Geimpft-Geimpft (G-G)
Abbildung 5: Aus Modellanalysen abgeleitete relative Häufigkeiten der Übertragungswege Ungeimpft-Ungeimpft (U-U), Ungeimpft-Geimpft (U-G), Geimpft-Ungeimpft (G-U) und Geimpft-Geimpft (G-G). Diese Verhältnisse stellen sich weitgehend unabhängig von der initialen Inzidenzverteilung ein. Annahmen: (1) infizierte Geimpfte sind um 50 % weniger ansteckend als Ungeimpfte; (2) Geimpfte sind gegenüber Ungeimpften um 50 % vor einer Ansteckung geschützt. (3) Betrachtungsdauer min. 3 Monate.
Natürlich ist auch das kein Beweis. Indes leuchtet das Resultat unmittelbar ein: Es gibt unter den Geimpften zwar doppelt so viele Infizierte (aufgrund der zweifachen Anzahl an Geimpften), da sie aber nur halb so infektiös sind, gleicht sich das in der Infektionsdynamik wieder aus. Analoges gilt auch für den umgekehrten Infektionsweg: halb so viele infektiöse Ungeimpfte, allerdings mit der doppelt so hohen Ansteckungsgefahr.
Das ist eine Momentaufnahme basierend auf der gegenwärtigen Impfquote. Mit steigender Impfquote wachsen erwartbar die Anteile der Geimpften und sinkt der Einfluss der Ungeimpften. Auf die absoluten Inzidenzzahlen hat das voraussichtlich keine durchschlagende Auswirkung (s. [20]).
Weitere Plausibilisierung
In Großbritannien hat man in einer großangelegten Studie über einige Monate hinweg PCR-Tests gleichermaßen für Ungeimpfte und Geimpfte durchgeführt. Dabei hat sich Folgendes ergeben: Die dort ebenfalls etwa doppelt so große Gruppe der Geimpften wies im Vergleich zur Gruppe der Ungeimpften eine doppelt so hohe Infektionszahl auf. D. h., die spezifischen Inzidenzen in den beiden Gruppen waren also gleich.
Dieses Ergebnis deckt sich mit der oben aus den vorliegenden Felddaten der symptomatischen Inzidenzen abgeleiteten Aussage für Deutschland. Es liegt daher nahe, dass die Ungeimpften und die Geimpften gleichermaßen und in etwa gemäß ihrem Anteil in der Bevölkerung die Infektionsdynamik bestimmen. Der wesentliche Unterschied besteht allerdings darin, dass die Ungeimpften, und darunter insbesondere die Älteren, die Intensivstationen überproportional belasten. Das aber ist ein ganz anderes Thema.
Es soll nicht unerwähnt bleiben, dass die Aussage zur in derselben Weise bestehenden Verantwortlichkeit sowohl der Ungeimpften wie auch der Geimpften nicht das bloße Ergebnis aus einer Modelluntersuchung ist, sondern vielmehr durch Feldbeobachtungen (Daten des RKI zu symptomatisch Infizierten, s. [18], Studie des UK Health Service, s. [19]) untermauert wird.
Anhang
Kurzbeschreibung des mathematischen Modells
= Größe der Population.
= Anzahl der Individuen in der Altersgruppe .
(1)
= Anzahl infektiöser Ungeimpfter in der Altersgruppe und in der Periode .
= Anzahl infektiöser Geimpfter in der Altersgruppe und in der Periode .
= Anzahl infizierter Ungeimpfter in der Altersgruppe zu Beginn des Betrachtungszeitraums.
= Anzahl infizierter Geimpfter in der Altersgruppe zu Beginn des Betrachtungszeitraums.
= Summe der infizierten Ungeimpften in der Altersgruppe am Ende der Periode .
= Summe der infizierten Geimpften in der Altersgruppe am Ende der Periode .
(2)
(3)
= Impfquote in der Altersgruppe am Ende der Periode .
Infizierte nach Impfstatus:
(4)
Entwicklungsgesetz:
(5)
Hierin ist die Transformationsmatrix zur Berücksichtigung der Anzahl der bereits Infizierten:
(6)
Dabei gilt für :
(7)
Ferner wird die nach Geimpften und Ungeimpften differenzierende Reproduktionsmatrix eingesetzt, wobei:
(8)
Die Matrixelemente sind für folgendermaßen definiert:
(9)
Hierin steht für den Reproduktionsfaktor von infektiösen Ungeimpften der Altersgruppe auf Ungeimpfte der Altersgruppe . Analog steht für den Reproduktionsfaktor von infektiösen Geimpften der Altersgruppe auf Ungeimpfte der Altersgruppe , für den Reproduktionsfaktor von infektiösen Ungeimpften der Altersgruppe auf Geimpfte der Altersgruppe sowie für den Reproduktionsfaktor von infektiösen Geimpften der Altersgruppe auf Geimpfte der Altersgruppe .
Die Anzahl der Infektionen in der Periode nach Kausalität und Ziel wird wie folgt bestimmt:
(10)
Dabei sind die Matrizen , , definiert gemäß
(11)
(12)
Aufgelöst erhalten wir:
(13)
(14)
(15)
(16)
Über den Betrachtungszeitraum von Perioden ergeben sich daher mit die folgenden 4 Summen zur Gesamtanzahl der Infektionen in Bezug auf die entsprechenden Übertragungswege:
(17)
Für die obige Rechnung wurden drei Altersgruppen angesetzt (also ): 12-17, 18-59 und 60+ und ferner die folgenden Annahmen getroffen:
Infektionswahrscheinlichkeiten:
(18)
Impfquoten (näherungsweise konstant über den Betrachtungszeitraum):
Im Beitrag wird der Begriff der Impfstoff-Wirksamkeit erläutert und mit der Impfquote sowie der Hospitalisierung von Geimpften in Beziehung gesetzt. Auf dieser Basis wird eine Sensitivitätsanalyse der Fallzahlen von Geimpften und Ungeimpften hinsichtlich der Impfquote durchgeführt. Mit Hilfe von Felddaten des RKI werden auf dieser Grundlage ferner Abschätzungen zum Einfluss auf die Belegung der Intensivstationen und die Sterbefälle vorgenommen.
Im Ergebnis bringen höhere Impfquoten eine spürbare Entlastung bezüglich der Hospitalisierung und der Belegung von Intensivbetten. Die Fallzahlen werden merklich gesenkt, sie gehen aber nicht auf Null. Es bleibt ein immer noch hoher Sockelbestand an offenbar durch die Impfung allein – aufgrund von partiellem Impfwirkungsversagen – nicht vermeidbaren Fällen. Die Fallzahlen in der Altersgruppe 60+ überwiegen dabei deutlich.
Bezüglich der Todesfälle ein ähnlicher Befund: In der Altersgruppe 18-59 wird das – allerdings ohnehin schon geringe – Covid-19 Sterberisiko nochmals deutlich reduziert. Auch die Altersgruppe 60+ profitiert, wenn auch bei weitem nicht so stark. Das Covid-19 Sterberisiko der Älteren bleibt – aus ähnlichen Gründen wie oben – auch mit der Impfung auf einem vielfach höheren Niveau als bei den Jüngeren.
In der Gesamtbetrachtung spielt die Altersgruppe 12-17 keine Rolle, da hier nur sehr wenige Fälle von Intensivpflichtigen auftreten und Todesfälle nahezu überhaupt nicht vorkommen.
Derzeit registrieren wir eine hohe Anzahl von hospitalisierten Geimpften. Viele fragen sich, wie kann das sein, angesichts einer angegebenen Wirksamkeit der Impfstoffe von teilweise 90 % und mehr?
Sicher, wir haben bereits eine hohe Impfquote, insbesondere in der Altersgruppe 60+. Von daher liegt es auf der Hand, dass auch der Anteil der Geimpften unter den an Covid-19 Erkrankten bzw. der intensiv-medizinisch behandelten Patienten wächst und mit steigender Impfquote weiter steigen wird. Die Impfung schützt bekanntlich nicht zu 100 % vor einer symptomatischen oder asymptomatischen Infektion und auch nicht zu 100 % vor schweren Krankheitsverläufen. Es ist daher klar: Wenn im Extremfall alle geimpft sind, werden selbstverständlich nur noch Geimpfte erkranken.
Impfdurchbruch versus Impfstoffversagen
Im RKI-Wochenbericht vom 25.11.2021 ist der Anteil der Geimpften unter den Hospitalisierten der Altersgruppe 60+ für die Kalenderwochen 43 – 46 mit 56,0 % angegeben. Das ist eine erstaunliche hohe Zahl, wenn man bedenkt, dass zugleich die Impfquote in dieser Altersgruppe bei 86 % liegt.
Das RKI spricht hier von „Impfdurchbrüchen“. Eine etwas missverständliche Bezeichnung, denn es wird ja kein „Durchbruch“ erzielt, vielmehr handelt es sich um ein Impfstoffversagen. Richtigerweise sollte man daher davon sprechen, dass bei 56,0 % der Hospitalisierten der Altersgruppe 60+ ein Impfwirkungsversagen vorliegt.
Dieser exemplarische Befund mag grundsätzliche Zweifel an der Wirksamkeit der Impfstoffe nähren. Intuitiv vermutet man eine drastisch reduzierte Wirksamkeit der Impfung als Ursache für den hohen Anteil der hospitalisierten Geimpften. Dem ist indessen nicht so. Tatsächlich liegt die Impfwirksamkeit im konkreten Fall bei knapp 80 %. Das ist zwar weniger als die in der Zulassungsstudie bestimmte Zahl von 90 – 95 %, aber immer noch ein vergleichsweise hoher Schutz.
Was heißt eigentlich Wirksamkeit?
Um zu verstehen, wie die Impfwirksamkeit bestimmt wird betrachten wir ein Beispiel. Nehmen wir eine Kohorte von 1000 Geimpften und eine Vergleichsgruppe von 1000 Ungeimpften. Wenn in der Gruppe der Ungeimpften 20 Personen hospitalisiert werden und in der Gruppe der Geimpften nur 3, wie hoch ist dann die Impfwirksamkeit?
Wir unterstellen, dass die Personen in den beiden Gruppen nach Risikofaktoren, Alter und Geschlecht usw. identisch verteilt sind. Daher dürfen wir so tun, als sei die Impfung der einzige Unterschied zwischen den beiden Gruppen. Die Reduzierung um 17 Personen gegenüber den 20 Hospitalisierten in der Gruppe der Ungeimpften ist daher auf die Wirkung der Impfung zurückzuführen. Demnach ist die relative Wirksamkeit der Impfung einfach die Größe dieser Minderung bezogen auf die Anzahl der hospitalisierten Ungeimpften. Im konkreten Fall also (20 – 3) / 20 = 0,85 (= 85 %). Die Versagensquote ist das Komplement davon, also 1 – 0,85 = 0,15 (= 15 %).
Wie bestimmt man die Wirksamkeit?
Normalerweise hat man selbstredend keine gleich große Vergleichsgruppe zu Verfügung. Wie sieht es also aus, wenn von 1000 Personen 900 geimpft und 100 ungeimpft sind? Angenommen, in der Gruppe der Ungeimpften treten 20 Erkrankungen auf, in der Gruppe der Geimpften dagegen 27. Wie hoch ist dann die Impfwirksamkeit? – Die obige Berechnung können wir nun nicht mehr direkt anwenden, weil die Gruppen unterschiedlich groß sind. Wir müssen also die Gruppen gedanklich gleich groß machen, indem wir z.B. die Anzahl der Ungeimpften auf 900 hochskalieren. Entsprechend erhöht sich dann auch die Anzahl der Hospitalisierten um den Faktor 9 auf nun 180 Erkrankte. Diese stehen den 27 erkrankten Geimpften gegenüber. Wie oben erhalten wir die Impfwirksamkeit zu (180 – 27) / 180 = 0,85 (= 85 %).
Obwohl also die Impfwirksamkeit 85 % beträgt, liegen mehr Geimpfte als Ungeimpfte im Krankenhaus. In diesem Beispiel ist es konkret nachvollziehbar, wie das zustande kommt. Wenn aber nur die Impfquote und der Hospitalisierungsgrad der Geimpften bekannt sind, erscheint das viel abstrakter. Tatsächlich gelten indessen dieselben Prinzipien. Der allgemeine formelmäßige Zusammenhang zur Bestimmung der Impfwirksamkeit ist
(1)
Dabei gilt:
= Anzahl der Fälle unter den Geimpften
= Anzahl der Fälle unter den Ungeimpften
= Impfquote
Gekürzt erhalten wir
(2)
Mit als Gesamtanzahl der Inzidenzen sowie mit als Anteil der Geimpften und als Anteil der Ungeimpften folgt
(3)
Wenn wir berücksichtigen, erhalten wir schließlich die einfache symmetrische Formel
(4)
Analyse der Wirkungsformel
Der resultierende Zusammenhang zwischen der Hospitalisierung Geimpfter und der Wirksamkeit des Impfstoffs ist nachfolgend grafisch gargestellt (s. Abb. 1).
Abbildung 1: Retrograde Bestimmung der Wirksamkeit des Impfstoffs aus der Hospitalisierung Geimpfter für unterschiedliche Impfquoten.
Abbildung 1: Retrograde Bestimmung der Wirksamkeit des Impfstoffs aus der Hospitalisierung Geimpfter für unterschiedliche Impfquoten. Man erkennt, dass bei gegebener Impfquote die resultierende Wirksamkeit mit steigendem Hospitalisierungsgrad erst langsam, dann aber rasch (überproportional schnell) fällt. Beispiel: Bei einer Impfquote von 80 % (dunkelgrüne Kurve) und einem Geimpften-Anteil unter den Hospitalisierten von 20 % ergibt sich eine Impfstoffwirksamkeit von 94 %.
Ein Beispiel: Wenn sich bei gleichbleibender Impfquote von 80 % die Hospitalisierung von 20 % auf 50 % erhöht, dann spricht das für eine Reduzierung der Impfstoffwirksamkeit von ca. 94 % auf 75 %.
Solange der Hospitalisierungsgrad kleiner als bleibt, liegt die Wirksamkeit noch über 90 %. Bei einer Impfquote von 70 % wird diese Grenze ab einem Geimpften-Hospitalisierungsanteil von knapp 19 % unterschritten. Eine höhere Impfquote von 90 % führt dagegen noch bei einem Hospitalisierungsanteil von Geimpften in Höhe von 47 % zu einer Wirksamkeit von über 90 %. Bei 95 % Impfquote wird die entsprechende Hospitalisierungsgrenze auf etwa 65 % hinausgeschoben.
Grenzbetrachtungen zur Wirkungsformel
Für Hospitalisierungsgrade um Null fällt die Wirksamkeit um Prozent für einen Anstieg der Hospitalisierung um 10 Prozent (also z.B. um 10 % bei einer Impfquote von 50 % und um etwa 1 % bei einer Impfquote von 90 %).
Die Wirksamkeit ist Null, wenn der Hospitalisierungsgrad bis zur Höhe der Impfquote ansteigt. Die Steigung der Kurve ist dabei , so dass z.B. bei einer Impfquote von die Wirksamkeit pro Erhöhung des Hospitalisierungsgrads um 1 Prozent um 4 % fällt; bei gar um etwa 11 %.
Der Hospitalisierungsanteil Geimpfter aus Impfquote und Wirksamkeit
Eigentlich wollen wir wissen, wie hoch der erwartete Anteil der Geimpften unter den Hospitalisierten bei gegebener Wirksamkeit der Impfung sein wird. Dazu müssen wir die obige Formel nach umstellen und erhalten:
(5)
Analyse der Hospitalisierungsformel
Man entnimmt dem Zusammenhang unmittelbar, dass bei einer Wirksamkeit von , wie nicht anders zu erwarten, der Anteil der Geimpften unter den Hospitalisierten stets gleich 0 ist. Wenn die Impfquote den Betrag übersteigt, dann liegt der Geimpften-Anteil mindestens bei 50 %. Bei einer Wirksamkeit von 80 % ist das demnach schon bei einer Impfquote von 83 % der Fall. Sofern die Impfquote mindestens gleich der Impfstoff-Wirksamkeit ist, erreicht der Anteil der Geimpften unter den Hospitalisierten knapp 50 %. Das ist es, was wir derzeit angesichts einer Impfquote von 86,1 % in der Altersgruppe 60+ und einer Wirksamkeit in ähnlicher Höhe sehen.
In Abb. 2 ist die Abhängigkeit von der Impfquote für den Geimpften-Anteil unter den Hospitalisierten bei unterschiedlichen Wirksamkeiten grafisch dargestellt.
Abbildung 2: Hospitalisierung Geimpfter in Abhängigkeit von der Impfquote für unterschiedliche Stufen der Wirksamkeit des Impfstoffs.
Abbildung 2: Hospitalisierung Geimpfter in Abhängigkeit von der Impfquote für unterschiedliche Stufen der Wirksamkeit des Impfstoffs. Man erkennt, dass bei gegebener Wirksamkeit des Impfstoffs der Anteil der Geimpften unter den Hospitalisierten mit wachsender Impfquote erst leicht und dann rasch (überproportional) steigt. Beispiel: Bei einer Impfstoffwirksamkeit von 70 % (gelbe Kurve) und einer Impfquote von 70 % ergibt sich der Anteil der hospitalisierten Geimpften zu ca. 40 %.
Wenn die Impfquote bei einer Impfstoffwirksamkeit von 90 % (dunkelgrüne Kurve) von 80 % auf 90 % erhöht wird, dann wächst der Anteil der Geimpften unter den Hospitalisierten bereits um fast 20% von etwa 28 % auf 47 %.
Für Impfquoten gleich der Wirksamkeit oder höher steigt der Anteil der Geimpften für jedes weitere Prozent an höherer Impfquote mindestens um den Prozentbetrag (also z.B. um > 2,5 % bei einer Steigerung der Impfquote von 90 % auf 91 % und einer Wirksamkeit von 90 %).
Grenzbetrachtungen zur Hospitalisierungsformel
Bei einer Impfquote von Null steigt der Hospitalisierungsgrad bei einer kleinen Änderung der Impfquote um (also z.B. um 5 % bei einer Steigerung der Impfquote von 0 auf 10 % und einer Wirksamkeit von 50 %).
Den steilsten Anstieg registriert man für hohe Impfquoten nahe 100 %. Der Anteil der Geimpften wächst hier um knapp Prozent für jedes weitere Prozent an höherer Impfquote (also z.B. um ca. 10 % bei einer Steigerung der Impfquote von 99 % auf 100 %) und einer Wirksamkeit von 90 %.
Vertiefte Analyse über den Zusammenhang zwischen Wirksamkeit, Hospitalisierungsanteil und Impfquote
Die Erhöhung der Impfquote zieht bei gleichbleibender oder sinkender Wirksamkeit des Impfstoffs immer auch einen Anstieg beim Anteil der Hospitalisierten unter den Geimpften nach sich. Scheinbar paradoxerweise fällt der Anstieg umso steiler aus, je höher die Impfquote ist.
Für kleine Variationen der Impfquote und kleine Variationen in der Wirksamkeit kann man die resultierende Veränderung der Hospitalisierung mittels des folgenden Differentials bestimmen.
(6)
Die Hospitalisierung bleibt dabei gleich, wenn die kleine Variation der Impfquote bezüglich der Wirksamkeit entsprechend
(7)
kompensiert wird. Das gilt auch umgekehrt für die Impfquote bezüglich einer eventuellen Veränderung in der Wirksamkeit.
Grafische Darstellung als Hospitalisierungs-Heatmap
Das nachfolgende Diagramm (s. Abb. 3) zeigt den Zusammenhang zwischen der Impfquote, der Wirksamkeit des Impfstoffs und dem Anteil der hospitalisierten Geimpften in Form einer Heatmap. Man erkennt hier ganz klar, dass die gewünschten und im Sinne der Pandemiebekämpfung sinnvollen hohen Impfquoten unweigerlich zu einem höheren Anteil der hospitalisierten Geimpften führen. Die von der Sache her auf der Hand liegende Notwendigkeit einer möglichst hohen Wirksamkeit des Impfstoffs wird daraus ebenfalls deutlich.
Wenn der Schutz auf Werte von etwa 75 % zurückgeht (was bei einer länger zurückliegenden Impfung i.d.R. zu erwarten ist), steigt der Anteil der hospitalisierten Geimpften bei Impfquoten über 80 % schnell auf Werte von über 50 %. Derzeit beobachten wird das teilweise im Hinblick auf die Altersgruppe 60+, was die Dringlichkeit der Auffrischungsimpfung insbesondere für die Ältesten nachdrücklich belegt. Umgekehrt bleibt man bei Wirksamkeiten über 90 % sogar noch bei Impfquoten um 90 % im grün-gelben Bereich und damit bei Hospitalisierungsanteilen der Geimpften von unter 50 %.
Abbilddung 3: Zusammenhang zwischen der Impfquote, der Wirksamkeit des Impfstoffs und dem Anteil der hospitalisierten Geimpften in Form einer Heatmap.
Abbilddung 3: Zusammenhang zwischen der Impfquote, der Wirksamkeit des Impfstoffs und dem Anteil der hospitalisierten Geimpften in Form einer Heatmap. Gleiche Farben bedeuten gleiche Hospitalisierungsanteile. Der grüne Bereich steht für Anteile < 40 %, der gelbe für Werte um 50 %, der rote für Hospitalisierungsanteile > 60 %. Für ausgewählte Werte sind die Linien gleicher Hospitalisierung gestrichelt eingetragen. Am Schnittpunkt einer gestrichelten Kurve mit der x-Achse kann der betreffende Hospitalisierungsanteil unmittelbar abgelesen werden. Beispiel: Für eine Impfquote von 70 % und eine Impfstoffwirksamkeit von 80 % entnehmen wir dem Diagramm, dass der Anteil der hospitalisierten Geimpften ca. 30 % beträgt (vierte gestrichelte Kurve von links).
Anwendung auf die erhobenen Zahlenwerte
Mit dem erarbeiteten Rüstzeug können wir nun die eingangs formulierten Fragen zur Wirksamkeit und zur Hospitalisierung im Hinblick auf die aktuellen Felddaten schlüssig klären. Nach den RKI-Zahlen liegt die Impfquote für die Altersgruppe 60+ bei , zugleich ist die Inzidenzquote der Geimpften unter den Hospitalisierten mit angegeben. Daraus errechnen wir die resultierende Impf-Wirksamkeit zu
(8)
Felddaten zur Hospitalisierung Geimpfter und Ableitung der Impfstoff-Wirksamkeit
Nachfolgend sind für die Altersgruppen 60+ und 18-59 die Hospitalisierung, die Belegung der Intensivstationen und die Corona-Todesfälle bei Geimpften und Ungeimpften in der Kalenderwoche 43-46 grafisch dargestellt. Aus den entsprechenden Inzidenzen wurden mit obiger Formel die resultierenden Impfwirksamkeiten berechnet, die sämtlich bei um 80 % und teilweise über 90 % liegen und damit die hohe Impfstoff-Wirksamkeit bestätigen.
Abbildung 4: Altersgruppe 60+ – Hospitalisierung, Belegung der Intensivstationen und Corona-Todesfälle bei Geimpften und Ungeimpften in der Kalenderwoche 43-46.
Abbildung 4: Altersgruppe 60+ – Hospitalisierung, Belegung der Intensivstationen und Corona-Todesfälle bei Geimpften und Ungeimpften in der Kalenderwoche 43-46. Die blaue Linie zeigt die resultierende Impfwirksamkeit im Hinblick auf die drei genannten Inzidenzarten. Der relativ große Anteil der Geimpften in allen drei Kategorien steht nicht im Widerspruch zur (im Mittel immer noch) hohen Wirksamkeit der Impfstoffe und erklärt sich vielmehr aufgrund der Impfquote von fast 90 %.
Abbildung 5: Altersgruppe 18-59 – Hospitalisierung, Belegung der Intensivstationen und Corona-Todesfälle bei Geimpften und Ungeimpften in der Kalenderwoche 43-46.
Abbildung 5: Altersgruppe 18-59 – Hospitalisierung, Belegung der Intensivstationen und Corona-Todesfälle bei Geimpften und Ungeimpften in der Kalenderwoche 43-46. Die blaue Linie zeigt die resultierende Impfwirksamkeit im Hinblick auf die drei genannten Inzidenzarten. Der Anteil der Ungeimpften auf den Intensivstationen ist in dieser Altersgruppe mit fast 85 % sehr hoch. Das ist auf die im Vergleich zur Altersgruppe 60+ geringere Impfquote von ca. 75 % zurückzuführen. Die Wirksamkeit der Impfstoffe liegt bei knapp 90 % und darüber.
Aus den vorstehenden Grafiken zeigt sich deutlich, dass es völliger Unsinn ist, von einer „Pandemie der Ungeimpften“ zu sprechen. Zwar betrifft die Mehrzahl der im Krankenhaus behandelten Covid-19-Fälle – insbesondere auch derer auf der Intensivstation – die Ungeimpften, allerdings ist der Anteil der Geimpften mit immerhin 46 % bis 56 % in der Altersgruppe 60+ erheblich.
Analyse der Felddaten nach absoluten Zahlen
Mit Fortschreiten der Impfquote wird der Anteil der geimpften Covid-19-Patienten zwangsläufig weiter steigen, wie wir oben gesehen haben. Entscheidend für die Lage in den Krankenhäusern sind indes die absoluten Fallzahlen, nicht der Impfstatus der Patienten. Dazu betrachten wir die beiden nachfolgenden Grafiken.
Abbildung 6: Absolute Zahlen für die Hospitalisierung von Geimpften und Ungeimpften in den Altersgruppen 18-59 und 60+ im Zeitraum KW 43-46.
Abbildung 6: Absolute Zahlen für die Hospitalisierung von Geimpften und Ungeimpften in den Altersgruppen 18-59 und 60+ im Zeitraum KW 43-46. Die Zahl der ungeimpften Patienten überwiegt deutlich, doch ist die Anzahl der Geimpften erheblich und keinesfalls vernachlässigbar.
Abb. 6 kann man entnehmen, dass die Zahl der ungeimpften Patienten überwiegt, allerdings ist die Anzahl der Geimpften erheblich und keinesfalls vernachlässigbar. Ähnlich ist es bezüglich der Neubelegung von Intensivbetten und der zu verzeichnenden Todesfälle, wie wir in Abb. 7 sehen können.
Abbildung 7: Absolute Zahlen für die Neubelegung von Intensivbetten und Todesfällen von Geimpften und Ungeimpften in den Altersgruppen 18-59 und 60+ im Zeitraum KW 43-46.
Abbildung 7: Absolute Zahlen für die Neubelegung von Intensivbetten und Todesfällen von Geimpften und Ungeimpften in den Altersgruppen 18-59 (im Vordergrund mit helleren Farbtönen) und 60+ (im Hintergrund mit dunkleren Farbtönen) im Zeitraum KW 43-46. Auffällig ist die relativ hohe Anzahl von Ungeimpften aus der Altersgruppe 18-59 auf der Intensivstation.
Eine nennenswerte Anzahl von ungeimpften Intensivpflichtigen kommt aus der Altersgruppe 18-59. Insgesamt überwiegen jedoch deutlich die Patienten und Todesfälle aus der Altersgruppe 60+. Damit zeigt sich einmal mehr das schon sein Beginn der Pandemie beobachtete Bild, nachdem insbesondere die Älteren von Covid-19 betroffen sind. Die Verfügbarkeit von Impfstoffen und die in dieser Altersgruppe hohe Impfquote von fast 90 % haben daran nur wenig geändert.
Theoretische Bestimmung der Fallzahlen
Im Folgenden werden wir untersuchen, wie sich die Änderung der Impfquote auf die absolute Anzahl der Hospitalisierten, der Belegung der Intensivbetten und der Todesfälle auswirkt. Wir können die oben dokumentierte Formel über den Zusammenhang zwischen der Wirksamkeit, der Impfquote und dem Anteil der Geimpften auf die Kohorte der symptomatisch an Coivid-19 Erkrankten anwenden. Im Ergebnis erhalten wir so aus der symptomatischen Wirksamkeit den Anteil der symptomatisch erkrankten Geimpften und entsprechend auch den Anteil der Ungeimpften. Wenn wir also die Gesamtanzahl der symptomatisch Erkrankten kennen, so können wir daraus unmittelbar die absoluten Zahlen der Ungeimpften und Geimpften mit Symptomen bestimmen.
Völlig analog gilt das auch für die hospitalisierten und die intensivpflichtigen Patienten. Sogar die Sterbefälle können wir so bestimmen. Dazu brauchen wir nur noch die entsprechenden Risikofaktoren. Wir müssen also z.B. das Risiko für die Hospitalisierung eines symptomatisch an Covid-19 erkrankten Geimpften oder Ungeimpften kennen. Des Weiteren das Risiko eines symptomatisch an Covid-19 erkrankten Geimpften oder Ungeimpften für die Einweisung auf die Intensivstation. Und zuletzt auch das Sterberisiko eines symptomatisch an Covid-19 erkrankten Geimpften oder Ungeimpften.
Nennen wir die Gesamtanzahl der symptomatisch Erkrankten in einem betrachteten Zeitraum sowie die Risikofaktoren für die Hospitalisierung bzw. . Ferner nennen wir die Anzahl der hospitalisierten Geimpften und die der Ungeimpften .
(9)
Die resultierende Gesamtanzahl der Hospitalisierten ist folglich
(10)
Feinanalyse der Fallzahlen
Für die Bestimmung der Sensitivität bei Änderungen der Impfquote ist es nützlich, die Ableitung nach zu betrachten:
(11)
Die relative Änderung der Hospitalisierung bei Änderungen der Impfquote kann auf dieser Basis folgendermaßen errechnet werden:
(12)
Völlig analog ergeben sich auch die entsprechenden Formeln für die Intensivpflichtigen und die Sterbefälle. Dabei verwenden wir die analog benannten Risikofaktoren und bzw. und . Für die Fallzahlen der Geimpften und Ungeimpften schreiben wir , , , , sowie .
Sensitivitätsanalyse – Überblick
Die aus den Formelbeziehungen resultierenden typischen Abhängigkeiten stellen wir nachfolgend exemplarisch anhand der Belegung von Intensivbetten dar. Es soll dabei zunächst nur um die Sensitivitätsanalyse gehen. Die realen Zahlen aufgesplittet nach Altersgruppen folgen weiter unten. Für die Sensitivitätsanalyse legen wir die folgenden Zahlenwerte zugrunde:
Wirksamkeit des Impfstoffs in Bezug auf eine symptomatische Erkrankung = 75 %.
Risiko eines symptomatisch an Covid-19 erkrankten Geimpften für die Einweisung auf die Intensivstation = 1,0 %.
Risiko eines symptomatisch an Covid-19 erkrankten Ungeimpften für die Einweisung auf die Intensivstation = 4,0 %.
Prinzipielle Abhängigkeit der Fallzahlen von der Impfquote
Basis für die exemplarischen Berechnungen ist die Annahme von insgesamt 10.000 symptomatisch Infizierten (Summe der Geimpften und Ungeimpften).
Abbildung 8: ITS-Neueinweisungen in Abhängigkeit von der Impfquote.
Abbildung 8: ITS-Neueinweisungen in Abhängigkeit von der Impfquote. Als Bezugsgröße wurden 10.000 symptomatisch Infizierte angenommen.
Man sieht, dass mit steigender Impfquote die Fallzahlen für die Ungeimpften (orangefarbene Säulen) kontinuierlich abnehmen. Zugleich steigen die Zahlen für die Geimpften (grüne Säulen). Indessen wird die Zunahme bei Letzteren durch den Rückgang der Einweisungen bei den Ungeimpften überkompensiert, so dass in Summe (gestrichelte Linie) die Fallzahlen sinken. Ein Beispiel für eine Impfquote von 80 %: Die Anzahl der Neueinweisungen von Ungeimpften liegt bei etwa 200 Personen (orange Säule). Entsprechend haben wir hier 50 intensivpflichtige Geimpfte (grüne Säule). Insgesamt beträgt die Fallzahl der neu Intensivpflichtigen somit 250 (gestrichelte Linie bei 80 %).
Änderung der Fallzahlen bei Erhöhung der Impfquote
Je höher die Impfquote, desto größer ist offensichtlich der Effekt auf den weiteren Rückgang der Fallzahlen bei Fortsetzung der Impfkampagne. Der prinzipiell bestehende Zusammenhang wird in Abb. 9 visualisiert.
Abbildung 9: Differenz der ITS-Neueinweisungen bei Erhöhung der Impfquote um 1 %. Als Bezugsgröße wurden 10.000 symptomatisch Infizierte angenommen.
Abbildung 9: Differenz der ITS-Neueinweisungen bei Erhöhung der Impfquote um 1 %. Als Bezugsgröße wurden 10.000 symptomatisch Infizierte angenommen. Der obere Rand der grünen Fläche steht für die Erhöhung der Neubelegung von Intensivbetten mit Geimpften bei einer Steigerung der Impfquote um 1 %. Entsprechend markiert der untere Rand der orangefarbenen Fläche die gleichzeitige Abnahme der Fallzahlen bei den Ungeimpften. Die gestrichelte Linie zeigt die Summe daraus.
Ein Beispiel: Wenn die bestehende Impfquote von 85 % um 1 % erhöht wird, sinkt die Anzahl der Neueinweisungen von Ungeimpften im Mittel um etwa 7,5 Personen (orange Kurve bei 85 %). Zugleich erhöht sich die Anzahl der Neueinweisungen von Geimpften um 2 Personen (grüne Kurve bei 85 %). Insgesamt müssen daher im Mittel ca. 5,5 Personen weniger neu auf die Intensivstation verlegt werden.
Relative Änderung der Fallzahlen bei Erhöhung der Impfquote
In den vorangegangenen Betrachtungen wird Bezug genommen auf die zugrundeliegende Inzidenz der symptomatisch Erkrankten. Eine davon unabhängige Sicht bietet Abb. 10. Hier wird der relative Rückgang der Fallzahlen exemplarisch quantifiziert.
Abbildung 10: Relativer Rückgang der ITS-Neueinweisungen bei Erhöhung der Impfquote um 1 %.
Abbildung 10: Relativer Rückgang der ITS-Neueinweisungen bei Erhöhung der Impfquote um 1 %. Die Kurve zeigt an, um wieviel Prozent die Fallzahlen für die neu Intensivpflichtigen bei einer Erhöhung der Impfquote um 1 % zurückgehen. Beispiel: Wenn eine bestehende Impfquote von 65 % um 1 % erhöht wird, sinkt die Gesamtanzahl der Neueinweisungen (von Geimpften und Ungeimpften) im Mittel um etwa 1 %. Bei einer Impfquote von 80 % verdoppelt sich der relative Rückgang bei einer weiteren Erhöhung auf 2 %.
Man erkennt, dass der Effekt auf die Fallzahlen mit steigender Impfquote überproportional schnell wächst. Bei niedrigen Impfquoten bringt die Steigerung der Quote nur einen geringen Gewinn. Je höher die Impfquote, desto größer der resultierende relative Rückgang der Fallzahlen bei einer weiteren Anhebung der Impfquote. Der Maximalwert ist abhängig von den zugrunde gelegten Risikofaktoren. Für die maximal mögliche Steigerung erhält man
(13)
Zahlenwerte mit näherem Realitätsbezug – Überblick
Nach dieser eher theoretischen Sensitivitätsanalyse kommen wir nun zu den nach Altersgruppen aufgesplitteten Zahlen mit näherem Realitätsbezug. Für die relevanten Risikofaktoren werden die in Tab. 1 aufgelisteten Werte angesetzt.
Tabelle 1: Risikofaktoren
Tabelle 1: Risikofaktoren für Hospitalisierung, Intensivbehandlung und Tod nach einer symptomatischen Erkrankung an Covid-19 für Geimpfte und Ungeimpfte getrennt nach Altersgruppen. Zugrunde gelegt wurden die Rohdaten des RKI aus den Kalenderwochen 41 – 47. Die tatsächlichen Werte schwanken und wurden daher für die Tabelle über 7 Wochen gemittelt und gerundet.
Wir haben im vorangehenden Abschnitt gesehen, welchen grundsätzliche Einfluss die Impfquote auf die Fallzahlen hat. Nun wollen wir fragen, wie sich die entsprechende Steigerung der Quote bzw. die Impfung einer bestimmten Personenanzahl je nach Altersgruppe auf die Fallzahlen auswirkt. Für die drei betrachteten Altersgruppen werden die Wirksamkeiten 90 % (12-17), 75 % (18-59) und 70 % (60+) angesetzt.
Das RKI hat im Wochenbericht vom 02.12.2021 mit 90 % (12-17), 65 % (18-59) und 58 % (60+) etwas geringere Werte genannt (s. [2]). Wir legen dennoch die höheren Wirksamkeiten zugrunde. Begründung: Man kann davon auszugehen, dass die aktuell niedrigeren Zahlen auf einen nur temporär bestehenden größeren Anteil von Personen mit nachlassendem Impfschutz zurückzuführen ist. Sobald die ausstehenden Auffrischungsimpfungen nachgeholt sind, wird sich das aller Voraussicht nach wieder normalisieren. Mit den kleineren Wirksamkeiten wird der Effekt höherer Impfquoten auf die Reduzierung der Fallzahlen abgeschwächt. Hinsichtlich der Sensitivitätsanalyse ändert sich indes nichts Grundsätzliches.
Änderung der Neu-Hospitalisierung bei Erhöhung der Impfquote um 1 %
In Abb. 11 ist der Einfluss einer um 1 % höheren Impfquote auf die Neu-Hospitalisierung pro Altersgruppe dargestellt.
Abbildung 11: Änderung der Neu-Hospitalisierung bei einer um 1% höheren Impfquote.
Abbildung 11: Änderung der Neu-Hospitalisierung bei einer um 1% höheren Impfquote. Annahme: Inzidenzverteilung nach Altersgruppen gemäß 12-17: 200 / 18-59: 100 / 60+: 50 (entspricht einer Gesamtinzidenz von 80). Links ist die Änderung in der Bettenbelegung aufgetragen. Darauf beziehen sich die Säulen. Die punktierte Linie mit den Rauten zeigt die relative Änderung der Gesamt-Bettenbelegung (über alle Altersgruppen) an. S. hierzu die rechte Achse.
Die Impfquotenänderung bezieht sich jeweils auf die entsprechende Altersgruppe mit den auf der x-Achse dokumentierten Bezugsgrößen. Je nach Altersgruppe hat die 1-prozentige Erhöhung einen unterschiedlichen Effekt auf die resultierende Gesamtimpfquote. Die Auswirkung ist unten links im Diagramm aufgelistet.
Wie ist das Diagramm zu interpretieren? In der Altersgruppe 12-17 bringt die Steigerung der Impfquote um 1 % (bei gleicher symptomatischer Inzidenz) nahezu nichts. Man erkennt weiter, dass Impfungen in der Altersgruppe 60+ den größten Ertrag nach sich ziehen, trotz der mit 0,29 % nur etwa halb so hohen Steigerung der Gesamt-Impfquote im Vergleich zur Gruppe der 18-59-Jährigen. Im Beispiel verringert sich die Fallzahl bei den Ungeimpften um 43. Zugleich erhöht sich die Fallzahl um 23 bei den Geimpften. In Summe kommt es zu einer Reduzierung um 20 Personen. In der Altersgruppe 18-59 ist der Effekt in Summe nur halb so stark ausgeprägt.
Änderung der Neu-Hospitalisierung bei 1 Million zusätzlichen Impfungen
Betrachten wir zum Vergleich den Fall von 1 Million zusätzlichen Impfungen in den jeweiligen Altersgruppen (s. Abb. 12). Der Aufwand ist in diesem Fällen stets derselbe. Welchen Nutzen bringt dies?
Abbildung 12: Änderung der Neu-Hospitalisierung bei 1 Mio. zusätzlichen Impfungen.
Abbildung 12: Änderung der Neu-Hospitalisierung bei 1 Mio. zusätzlichen Impfungen. Annahme: Inzidenzverteilung nach Altersgruppen gemäß 12-17: 200 / 18-59: 100 / 60+: 50 (entspricht einer Gesamtinzidenz von 80). Links ist die Änderung in der Bettenbelegung aufgetragen. Darauf beziehen sich die Säulen. Die punktierte Linie mit den Rauten zeigt die relative Änderung der Gesamt-Bettenbelegung (über alle Altersgruppen) an. S. hierzu die rechte Achse.
Die resultierenden Impfquotenänderungen 1 Mio. Impfungen sind unten links im Diagramm aufgelistet. In der kleinsten Gruppe der 12-17-Jährigen macht dies eine um 22 % höhere Impfquote aus. Trotzdem ist der Nutzen in Form der Reduzierung von Fallzahlen null. Die Altersgruppe 18-59 ist die größte, 1 Mio. Impfungen führen hier nur zu einer um 2,2% höheren Impfquote. Immerhin ergibt sich bei 37 weniger hospitalisierten Ungeimpften und 13 mehr hospitalisierten Geimpften in der Bilanz eine Verringerung der Fallzahlen um 24.
Deutlich größer ist wieder der Effekt in der Altersgruppe 60+. Eine Million zusätzliche Impfungen (das entspricht hier einer um 4,2 % höheren Impfquote) reduzieren die Zahl der neu hospitalisierten Ungeimpften um 180 Personen. Auch wenn dem ein Anstieg bei den neu hospitalisierten Geimpften um 95 Personen entgegensteht, bleibt unterm Strich mit einer Reduzierung der Neubelegung um 85 Personen mit Abstand der größte Gewinn. Es sind mehr als 3-mal so viel, wie in der doppelt so großen Gruppe der 18-59-Jährigen. Das sieht man auch bei der relativen Veränderung der Belegungszahlen (blau gestrichelte Linie). Die Fallzahlen sinken um mehr als 3 %, gegenüber knapp 1 % in der Altersgruppe 18-59.
Änderung der Anzahl der neu Intensivpflichtigen bei 1 Million zusätzlichen Impfungen
Aus vorstehender Abb. 12 wird in der Gesamtschau unmittelbar klar, dass man (zunächst einmal) vorrangig in der Gruppe der Älteren impfen muss. Dieser Schluss wird weiter untermauert, wenn man die Auswirkung auf die Belegung der Intensivbetten und die Todesfallzahlen mit in den Blick nimmt. Die beiden nachfolgenden Abbildungen (Abb. 13 und 14) zeigen dies nachdrücklich.
Aus Abb. 13 geht hervor, dass bezüglich der Neubelegung von Intensivbetten, Impfungen in der Altersgruppe 60+ einen fast 6-mal höheren Nutzen haben als in der Altersgruppe 18-59. Natürlich gilt dieser Befund in der Langfristperspektive nicht mehr, wenn alle Älteren geimpft sind und die Impfquote bei den Jüngeren ebenfalls in die Nähe von 90 % oder darüber kommt. Es trifft aber jedenfalls in der gegenwärtigen Situation zu, wo – trotz der hohen Impfquote von 86 % – noch viele Ältere nicht geimpft sind oder einen nachlassenden Impfschutz aufweisen. Im Kontrast dazu sind Impfungen in der Altersgruppe 12-17 (und erst recht bei Kindern) im Effekt auf die Belegung von Intensivbetten geradezu wirkungslos.
Abbildung 13: Änderung der Neubelegung von Intensivbetten bei 1 Mio. zusätzlichen Impfungen.
Abbildung 13: Änderung der Neubelegung von Intensivbetten bei 1 Mio. zusätzlichen Impfungen. Annahme: Inzidenzverteilung nach Altersgruppen gemäß 12-17: 200 / 18-59: 100 / 60+: 50 (entspricht einer Gesamtinzidenz von 80). Links ist die Änderung in der Bettenbelegung aufgetragen. Darauf beziehen sich die Säulen. Die punktierte Linie mit den Rauten zeigt die relative Änderung der Gesamt-Bettenbelegung (über alle Altersgruppen) an. S. hierzu die rechte Achse.
Änderung der neuen Covid-19 Sterbefälle bei 1 Million zusätzlichen Impfungen
In einem nochmals stärkeren Kontrast zeigen sich die Verhältnisse, wenn man auf die Todesfallzahlen blickt (s. Abb. 14). Diesbezüglich nimmt man die größten Unterschiede zwischen den drei Altersgruppen wahr. Es zeigt sich, dass 1 Mio. zusätzliche Impfungen in den Altersgruppen 12-17 oder 18-59 keine nennenswerte Auswirkung auf Fallzahlen haben. Erst wenn man in den Bereich von mehreren Millionen Neu-Impfungen kommt, sieht man einen Effekt. Der Grund dafür liegt auf der Hand: Das Corona-Sterberisiko in den Altersgruppen 12-17 und 18-59 ist mit und ohne Impfung zigfach niedriger als in der Altersgruppe 60+. Unabhängig von der Impfquote bleibt daher die Anzahl der Corona-Toten bei den Jüngeren relativ niedrig. Im Gegensatz dazu verringern sich indes die Todesfallzahlen bei den Über-60-Jährigen trotz der schon vergleichsweise hohen Impfquote von 86 % weiter um mehr als 6 % (-35 Ungeimpfte, +15 Geimpfte, macht -20 in der Bilanz).
Abbildung 14: Änderung der Todesfallzahlen bei 1 Mio. zusätzlichen Impfungen.
Abbildung 14: Änderung der Todesfallzahlen bei 1 Mio. zusätzlichen Impfungen. Annahme: Inzidenzverteilung nach Altersgruppen gemäß 12-17: 200 / 18-59: 100 / 60+: 50 (entspricht einer Gesamtinzidenz von 80). Links ist die Änderung in der Bettenbelegung aufgetragen. Darauf beziehen sich die Säulen. Die mit Rauten markierte punktierte Linie zeigt die relative Änderung der Gesamt-Bettenbelegung (über alle Altersgruppen) an. Sie bezieht sich auf die rechte y-Achse.
Belastbarkeit der getroffenen Aussagen
Bezüglich der direkten Auswirkungen auf die Fallzahlen bei zunehmendem Impffortschritt haben wir in der vorstehenden Analyse einen guten Überblick gewonnen. Der Anspruch war und ist dabei aber nicht, exakt vorherzubestimmen, wie sich die Zahlen entwickeln werden. Dafür ist das publizierte Zahlenmaterial des RKI nicht geeignet, weil z.B. der Impfstatus der Getesteten nicht zuverlässig erfasst wird. Die Zusammensetzung der Testkohorte spiegelt lediglich rechtliche Vorgaben wider. Nötig wäre aber eine Orientierung an wissenschaftlichen Grundsätzen. In letzter Konsequenz sind daher die veröffentlichten Inzidenzen nur grobe Schätzungen.
Darüber hinaus gibt es keine Zahlen über die tatsächliche Verbreitung des Virus unter den nicht Getesteten. Um diese Zahl zumindest verlässlich abschätzen zu können, wären regelmäßige anlasslose Tests über einen repräsentativen Bevölkerungsquerschnitt erforderlich. Das alles steht nicht zur Verfügung, weswegen Vorhersagen über die künftigen Inzidenzen bei höherer Impfquote mit Unsicherheit belastet sind.
Mittelbar bleiben daher auch die Effekte im Hinblick auf die Hospitalisierung, die Belegung von Intensivbetten und letztlich auch die Sterbefälle unsicher. Um diese Unwägbarkeiten ein Stück weit abzumildern, haben wir deshalb die Aussagen auf die Inzidenz betreffend der symptomatisch an Covid-19 Erkrankten bezogen. Je nach Altersgruppe kann die tatsächliche Anzahl der Infizierten (also der positiv Getesteten) um den Faktor 2 bis 5 höher liegen.
Eine Schwäche mag man darin sehen, dass der möglicherweise günstige Einfluss von höheren Impfquoten auf die Infektionszahlen außen vor geblieben ist. Indessen gibt es Gründe für die Annahme einer nur schwachen Korrelation zwischen Inzidenz und Impfquote (s. [11]). Unabhängig von diesen bestehenden Unschärfen gibt die vorstehende Analyse nichtsdestotrotz zutreffende Einblicke in die herrschenden Gesetzmäßigkeiten und gibt richtige Hinweise auf die zu präferierenden Handlungsoptionen.
Was können wir bei einer deutlich gesteigerten Impfquote erwarten?
Wir wollen abschließend einen kurzen Blick auf die mittelfristige Zukunft mit einer möglichen Impfquote von 82 % wagen. Als Referenz ist in Abb. 15 die Neubelegung von Intensivbetten bei einer Gesamt-Impfquote von 68,5 % unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100 dargestellt. Zum Vergleich findet sich in Abb. 16 die Neubelegung von Intensivbetten bei einer Gesamt-Impfquote von 82 % (mit den in der Grafik angegebenen altersgruppenspezifischen Impfquoten).
Abbildung 15: Neubelegung von Intensivbetten bei einer Gesamt-Impfquote von 68,5 % unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100
Abbildung 15: Neubelegung von Intensivbetten bei einer Gesamt-Impfquote von 68,5 % unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100 (entspricht einer Gesamtinzidenz von 154). Links ist die Änderung in der Bettenbelegung aufgetragen. In den 3 Rubriken mit den Altersgruppen ist zudem die zutreffende gruppenspezifische Impfquote genannt.
Abbildung 16: Neubelegung von Intensivbetten bei einer Gesamt-Impfquote von 82 %. unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100
Abbildung 16: Neubelegung von Intensivbetten bei einer Gesamt-Impfquote von 82 %. unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100 (entspricht einer Gesamtinzidenz von 154). Links ist die Änderung in der Bettenbelegung aufgetragen. In den 3 Rubriken mit den Altersgruppen ist zudem die zutreffende gruppenspezifische zukünftige Impfquote genannt.
Impfquoten 68,5 % und 82 % im Vergleich – Neubelegung von Intensivbetten
Unter Verzicht auf die Trennung in Geimpfte und Ungeimpfte zeigt Abb. 17 die direkte Auswirkung der höheren Impfquote: Sowohl in der Altersgruppe 18-59 als auch in der Gruppe 60+ sinken die Neubelegungen bei einer Impfquote von 82 % gegenüber heute signifikant, wenngleich in beiden Gruppen immer noch eine erhebliche Anzahl Intensivpflichtiger verbleibt.
Es soll an dieser Stelle nochmals hervorgehoben werden: Die im Rechenbeispiel unterstellte Impfquote von 82 % bedeutet, dass 95 % aller Erwachsenen geimpft sind.
Abbildung 17: Neubelegung von Intensivbetten – Vergleich Impfquoten 68,5 % und 82 %
Abbildung 17: Neubelegung von Intensivbetten – Vergleich Impfquoten 68,5 % und 82 % unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100 (entspricht einer Gesamtinzidenz von 154). Die entsprechenden gruppenspezifischen Impfquoten sind in den beiden Kästchen aufgelistet.
Am Ende kommt es darauf an, die Gesamtbelegung klein zu halten, daher wollen wir in Abb. 18 die Differenzierung nach Altersgruppen beiseitelassen.
Abbildung 18: Summenbetrachtung zur Neubelegung von Intensivbetten – Vergleich der Impfquoten 68,5 % und 82 %
Abbildung 18: Summenbetrachtung zur Neubelegung von Intensivbetten – Vergleich der Impfquoten 68,5 % und 82 % unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100 (entspricht einer Gesamtinzidenz von 154). Die entsprechenden gruppenspezifischen Impfquoten sind in den beiden Kästchen aufgelistet.
Wie man dem Säulendiagramm in Abb. 18 entnimmt, verringert sich die Zahl der Neubelegungen knapp um ein Drittel. Zwar sinkt die Anzahl der ungeimpften Patienten deutlich um etwa 60 %, zugleich aber steigt die Zahl der Geimpften Intensivpflichtigen um ca. 40 %. Für diesen Erfolg muss man die Impfquoten in den Altersgruppen 18-59 und 60+ jeweils auf 95 % hochschrauben. Der Anteil der Altersgruppe 12-17 ist so marginal, dass man in nicht näher betrachten muss. Bei einer reduzierten Wirksamkeit des Impfstoffs (s. obige Diskussion) würden hier jeweils die Anteile der Ungeimpften etwas kleiner und die der Geimpften etwas größer ausfallen.
Impfquoten 68,5 % und 82 % im Vergleich – Auswirkung auf die Todesfallzahlen
In Analogie zum vorangehenden Abschnitt betrachten wir noch zwei Grafiken zum Effekt auf die Sterbefälle.
Abbildung 19: Neue Sterbefälle – Vergleich Impfquoten 68,5 % und 82 %
Abbildung 19: Neue Sterbefälle – Vergleich Impfquoten 68,5 % und 82 % unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100 (entspricht einer Gesamtinzidenz von 154). Die entsprechenden gruppenspezifischen Impfquoten sind in den beiden Kästchen aufgelistet.
Im Vergleich zu den Werten in der Altersgruppe 60+ sind die Sterbefallzahlen in der Altersgruppe 18-59 drastisch kleiner und werden durch die 95%-Impfquote nochmals halbiert (s. Abb. 19). Die Grafik verdeutlicht aber auch, dass die höhere Impfquote an der Gefährdungslage für die Älteren nichts Grundlegendes ändern kann. Zwar sinken die Fallzahlen, es bleibt jedoch immer noch ein hoher Bestand an Sterbefällen.
Abbildung 20: Summenbetrachtung zu den Todesfallzahlen – Vergleich der Impfquoten 68,5 % und 82 %
Abbildung 20: Summenbetrachtung zu den Todesfallzahlen – Vergleich der Impfquoten 68,5 % und 82 % unter der Annahme einer Inzidenzverteilung nach Altersgruppen gemäß 12-17: 300 / 18-59: 200 / 60+: 100 (entspricht einer Gesamtinzidenz von 154). Die entsprechenden gruppenspezifischen Impfquoten sind in den beiden Kästchen aufgelistet.
In der Summenbetrachtung (s. Abb. 20) wird nochmals herausgestellt, was man von der hohen 95%-Impfquote (betreffend die Erwachsenen) erwarten kann und was nicht. Die Todesfallzahlen gehen signifikant zurück, sie bleiben aber auf hohem Niveau, weil der Anteil der erkrankten Geimpften mit der Impfquote steigt. Der Hauptgrund dafür ist die limitierte Wirksamkeit der Impfstoffe im Hinblick auf den Schutz vor Ansteckung, den Schutz vor schweren Verläufen und den nur begrenzten Schutz vor einem tödlichen Ausgang, insbesondere bei den Älteren. Als Risikofaktor kommt die mit der Zeit offenbar allgemein nachlassende Schutzwirkung erschwerend hinzu.
Resümee
Wie man der vorstehenden Analyse unschwer entnehmen kann, bringen höhere Impfquoten eine spürbare Entlastung bezüglich der Hospitalisierung und der Belegung von Intensivbetten. Die Fallzahlen werden merklich gesenkt, sie gehen aber nicht auf null. Es bleibt ein immer noch hoher Sockelbestand an offenbar durch die Impfung allein – aufgrund von partiellem Impfwirkungsversagen – nicht vermeidbaren Fällen. Die Fallzahlen in der Altersgruppe 60+ überwiegen dabei deutlich.
Bezüglich der Todesfälle ein ähnlicher, teilweise aber differenzierter Befund: In der Altersgruppe 18-59 wird das ohnehin schon vergleichsweise geringe Covid-19 Sterberisiko nochmals deutlich reduziert. Auch die Altersgruppe 60+ profitiert, wenn auch nicht so stark. Das Covid-19 Sterberisiko der Älteren bleibt auch mit der Impfung – aus ähnlichen Gründen wie oben – auf einem vielfach höheren Niveau als bei den Jüngeren.
In der Gesamtbetrachtung spielt die Altersgruppe 12-17 keine Rolle, da hier nur sehr wenige Fälle von Intensivpflichtigen auftreten und Todesfälle nicht bis äußerst selten vorkommen.
In der Grafik (s. Abb. 1) sind die Impfquoten verschiedener Länder gegen die jeweiligen 7-Tage Inzidenzen aufgetragen. Auf den ersten Blick erkennt man keinen Zusammenhang. Es gibt Länder mit hoher Impfquote und niedriger Inzidenz (z.B. Portugal), sowie solche mit niedriger Impfquote und hoher Inzidenz (z.B. Österreich), so wie man das erwartet. Das Gegenteil sieht man aber auch: Länder mit niedriger Impfquote und niedriger Inzidenz (z.B. Schweden) und solche mit relativ hoher Impfquote und gleichzeitig aber auch höherer Inzidenz (z.B. Island).
Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern (x-y-Diagramm) – Datenstand 16.11.2021
Abbildung 1: Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern (x-y-Diagramm) – Datenstand 16.11.2021
Ist da überhaupt eine statistische Korrelation?
Idealerweise würde man eine Korrelation von -1 oder nahe daran erwarten, also einen eindeutig negativen Zusammenhang zwischen Impfquote und Inzidenz. Tatsächlich liegt die statistische Korrelation bei einem Koeffizienten von -0,15. Die Korrelation ist also nicht Null, sie ist aber so gering, wie etwa die mögliche Wechselbeziehung zwischen dem Verkauf von Waschpulver in München und den Tageshöchsttemperaturen in Wanne-Eickel. Mit anderen Worten: Es gibt keine Korrelation. Jedenfalls bestand sie nicht zum Zeitpunkt der Datenerhebung.
Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern (Säulendiagramm) – Datenstand 16.11.2021
Abbildung 2: Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern (Säulendiagramm) – Datenstand 16.11.2021
Welche Folgerungen kann man daraus ableiten?
Natürlich darf man daraus nicht schließen, dass Impfen nichts bringt. Eine direkte Auswirkung auf die Inzidenzen hat die Impfquote aber offensichtlich nicht. Das ist indes nicht verwunderlich! Zwar schützt die Impfung gut vor schweren Verläufen, sie kann aber Infektionen unter Geimpften und zwischen Geimpften und Ungeimpften nicht unterbinden. Hier liegt der Schutz etwa zwischen 70 % und 90 %, das ist sogar weniger, als Masken und Abstand in vielen Situationen gewährleisten können. Die Impfung kann also Masken und Abstand nicht ohne Weiteres ersetzen.
Bei dieser Ausgangslage ist damit klar: Es gibt keine Pandemie der Ungeimpften. Die Pandemie betrifft alle. Das liegt schon in der Bedeutung des Wortes. Die Ungeimpften kann man schlechterdings nicht für den begrenzten Infektionsschutz der Impfung verantwortlich machen – und erst recht nicht für die über die Zeit nachlassende Impfwirkung.
Schutzwirkung der Impfung
Wie man mittlerweile aus Studien weiß, verringert sich die Schutzwirkung bereits im Verlaufe von einigen Monaten nach der Impfung. In Abhängigkeit vom Impfstoff und dem Alter des Impflings ist der Schutz in vielen Fällen bereits nach 4 – 7 Monaten stark reduziert und mitunter kaum noch vorhanden. Das ist sicher mit ein Grund für die hohe Inzidenz bezüglich der schweren Verläufe und auch für die Todesfälle unter den Geimpften in der Altersgruppe 60+. Rechnerisch ist die Impfquote hier mit 85,6 % sehr hoch, aber die Zweitimpfung liegt vielfach schon mehr als 6 Monate zurück. Insbesondere für die vulnerablen Gruppen gibt es deswegen derzeit keine realistische Alternative zur Auffrischungsimpfung. Genau dies rechtzeitig zu planen und umzusetzen hat die Politik – leider zum wiederholten Male – verabsäumt.
Trotz dieser Fakten wirft man seitens der Politik den Ungeimpften gerne Verantwortungslosigkeit und unsolidarisches Verhalten vor. Man redet mittlerweile gar unverblümt von einer möglichen Impfpflicht.
Sind die Ungeimpften verantwortungslos und unsolidarisch?
Doch trifft dies wirklich zu? Sind die Ungeimpften schuld daran, wenn die Belegung der Intensivstationen an die Kapazitätsgrenze gerät? Wenn das Pflegepersonal auf den Intensivstationen überlastet wird? Wenn heute weniger Intensivstationen betrieben werden können als noch vor einem Jahr, weil das Pflegepersonal fehlt?
Geimpfte Patienten machen – u.a. aus den o.g. Gründen – zwar bereits 45 %, der Neueinweisungen in der Altersgruppe 60+ aus. Richtig ist aber, dass die Ungeimpften unter den Hospitalisierten einen überproportional hohen Anteil stellen. Deswegen tragen die Ungeimpften zweifellos einen Teil der Verantwortung. In einer ersten unreflektierten Reaktion mag man Ihnen gar die Schuld an der Situation im Krankenhaus zuweisen. Doch ist dies allzu einseitig und greift zu kurz, denn die Ursachen für die relativ hohe Belegung der Intensivstationen und die Belastung des Pflegepersonals liegen tiefer. Die Gründe sind schon seit längerem bekannt. Die Entscheider haben aber nicht gehandelt.
Pandemie der Unfähigen
Im Verlauf der letzten Monate wurde die Bettenkapazität auf Intensivstationen um mindestens 4000 reduziert. Die Begründung dafür lässt aufhorchen: Es fehlen nicht etwa die technischen Geräte, sondern das Pflegepersonal. Und weil das Pflegepersonal knapp ist, müssen die (noch) Einsetzbaren über ihre Belastungsgrenze hinausgehen. Wer trägt dafür die Verantwortung?
Weder die Geimpften noch die Ungeimpften kann man dafür verantwortlich machen. Unabhängig von der pandemischen Lage muss man daher festhalten, dass zuvorderst andere in die Pflicht zu nehmen sind, die es an Solidarität und Verantwortung haben missen lassen. In erster Linie sind da zu nennen:
Politiker, die nicht rechtzeitig vorgesorgt haben, sei es durch Planung der Auffrischungsimpfung oder durch Vorgaben an die Gesundheitsinfrastruktur.
Krankenhausträger und Krankenhausbetreiber, die die Arbeitsbedingungen für das Pflegepersonal so gestaltet haben, dass jenes die Flucht ergreift.
Und nochmals die Politik, die es versäumt hat, praxisgerechte Vorgaben für die Behebung des Pflegenotstands zu machen.
Die verantwortlichen Politiker haben fahrlässig unzumutbare Arbeitsbedingungen für das Pflegepersonal geschaffen bzw. hingenommen. Das nenne ich verantwortungslos. Es wird aber offensichtlich klaglos akzeptiert. Die wirtschaftlichen Zwänge erfordern dies, wird dazu gerne gesagt.
Sarkastisch könnte man hinzufügen: Jetzt muss man nur noch die Intensivbettenkapazität um weitere 2.000 Betten reduzieren, dann hat man schon bei einer Inzidenz von 100 die „Katastrophe“. – Mich wundert, wie wenig dies in den Medien thematisiert wird. Besonders perfide finde ich, dass man nun pauschal die Gruppe der Ungeimpften zu Sündenböcken erklärt und damit von den eigenen Versäumnissen ablenkt. Offenbar ist man damit erfolgreich.
Es ist keine Pandemie der Ungeimpften, sondern eine Pandemie der Unfähigen, der Ignoranten und der Pflichtvergessenen.
Solidarität vs. Individualität
Indem man das individuelle und im Rahmen demokratischer Freiheitsrechte liegende Verhalten Einzelner als unsolidarisch zu qualifiziert, öffnet man damit die Büchse der Pandora. Wenn wir das tun, sind alsbald auch Raucher, Alkoholtrinker, Autofahrer, (Extrem-) Sportler und Übergewichtige, die direkt oder indirekt für zehntausende Tote p. a. sorgen und das Gesundheitssystem nachweisbar belasten unsolidarisch. Die Liste könnte man noch fortführen, man sieht aber schon daran, dass man in eine Sackgasse gerät.
Allein 330.00 Todesfälle jährlich sind die Folge von Herz-Kreislauferkrankungen – einige 10.000 davon vermeidbar bei halbwegs gesundheitsbewusster Lebensführung. Vor dem Tod steht nicht selten der Krankenhausaufenthalt und damit letztlich eine zumindest teilweise vermeidbare Belegung von Krankenbetten.
Es ist völlig unangebracht, die Gruppe der Covid-19-Ungeimpften isoliert der Verantwortungslosigkeit zu bezichtigen (auch wenn es sicher einige darunter geben mag, die Kritik verdienen, weil sie sich allzu sorglos verhalten). Solidarität ist immer eine freiwillige Leistung, sie ist keine Bringschuld. Wenn sie zur Pflicht wird, ist es keine Solidarität mehr.
Die Absurdität des an Ungeimpfte gerichteten pauschalen Vorwurfs unsolidarischen Verhaltens ist offenkundig.
Update vom 01.12.2021
In den meisten Ländern sind die Inzidenzzahlen trotz Erhöhung der Impfquote weiter gestiegen. In Portugal und Spanien haben sich die Werte verdoppelt. Der Korrelationskoeffizient beträgt nun -0,09. Die Wechselbeziehung zwischen Impfquote und Inzidenz ist daher nochmals unschärfer als Mitte November (s. Abb. 1.1). Es gibt also keine Korrelation zwischen der Impfquote und den Inzidenzzahlen.
Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern (x-y-Diagramm) – Datenstand 01.12.2021
Abbildung 1.1: Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern (x-y-Diagramm) – Datenstand 01.12.2021
Update vom 15.12.2021
Die Inzidenzzahlen in Ländern mit vormals niedrigen Infektionszahlen sind weiter gestiegen, in Ländern mit hoher Inzidenz sind sie gefallen. Die Impfquoten-Musterschüler Portugal und Spanien haben es „geschafft“, ihre Inzidenzwerte innerhalb von 4 Wochen um den Faktor 3 bzw. 6 zu erhöhen. Zugleich wurde überall weiter geimpft. Der Korrelationskoeffizient liegt nahezu unverändert bei -0,07. Nach wie vor gilt daher: Es gibt keine Korrelation zwischen Impfquote und Inzidenzzahlen.
Was ebenfalls auffällt: Die Panikmache in Deutschland ist beispiellos. Haben vielleicht doch die Recht, die sagen, die Situation in den deutschen Krankenhäusern hat weniger mit Corona, aber viel mit dem hausgemachten und von politischer Seite geduldeten Pflegenotstand zu tun? Im Laufe des Jahres hat man die Kapazität an Intensivbetten um 4000 reduziert („stillgelegt“) und nichts dafür getan, die Arbeitsbedingungen in der Pflege zu verbessern.
Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern – Datenstand 15.12.2021
Abbildung 1.2: Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern (x-y-Diagramm) – Datenstand 15.12.2021
Update vom 01.01.2022
Der Korrelationskoeffizient liegt nun bei +0,35. Es gibt also eine schwach-positive Korrelation: Je höher die Impfquote, desto größer die Inzidenz (s. Abb. 1.3). Keine Frage, das ist nicht die gewünschte Form der Wechselbeziehung. Es ist definitiv die falsche Richtung. Man kann sich die Realität halt nicht stricken.
Die Impfquoten-Musterschüler Portugal und Spanien sind mittlerweile als Hochrisikogebiete eingestuft. Desgleichen u.a. Frankreich, Italien und Dänemark. Das rigide Corona-Management in Italien und Frankreich konnte ebenfalls nicht verhindern, dass sich dort die Inzidenzzahlen im Verlauf der letzten 6 Wochen vervielfacht haben – trotz gleichzeitig gestiegener Impfquote. Auch in anderen Ländern ist das der Fall (s. Abb. 1.4).
Dafür wird man nun wohl Omikron verantwortlich machen. Immer gut, wenn es einen Schuldigen gibt. Nach wie vor gilt natürlich: Inzidenzen sind nur Indizien für ein mögliches Risiko. Eigentlich geht es um die schweren Krankheitsverläufe. Auch wenn die Impfung vor Omikron weniger schützt als vor Delta, bleibt immerhin noch eine gewisse Schutzwirkung. Insbesondere Gefährdete mit vielen Kontakten können daher ihr eigenes Erkrankungsrisiko mit einer Impfung substanziell reduzieren. Gewiss, ein egoistisches Motiv, aber es kann wirken.
Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern – Datenstand 01.01.2022
Abbildung 1.3: Impfquote vs. 7-Tage-Inzidenz in ausgewählten Ländern (x-y-Diagramm) – Datenstand 01.01.2022
Verlauf von Impfquote und Inzidenz über 6 Wochen
Abbildung 1.4: Verlauf von Impfquote und Inzidenz über 6 Wochen. Die Pfeile zeigen, wie sich die Impfquoten und vor allem die Inzidenzen vom 16.11.2021 bis zum 01.01.2022 entwickelt haben. In fast allen Ländern gibt es eine Bewegung hin zu höheren Inzidenzen bei gleichzeitig leicht gestiegenen Impfquoten.
(„Ungeimpfte sind unsolidarisch“ – Kommentar von Sarah Frühauf, MDR: https://www.daserste.de/information/nachrichten-wetter/tagesthemen/videosextern/tagesthemen-21-45-uhr-202.html)
Wenn man der öffentlichen Diskussion folgt, so scheint der Klimawandel als virulentes Thema mittlerweile nahezu überall angekommen zu sein. Auch sonst politisch total Desinteressierte sind aufgeschreckt und glauben, im Wettergeschehen, sei es Trockenheit oder Starkregen, den sicheren Beweis für das heraufziehende klimatische Unheil zu erkennen.
Keine Partei, die den „Klimaschutz“ nicht als die Herausforderung schlechthin begreift (von der AfD einmal abgesehen). Ganz zu schweigen von den Grünen, die quasi jegliche politische Entscheidung unter das Klimakuratel stellen wollen. Aber auch für die meisten anderen Parteien ist Klimaschutz mittlerweile das Nummer 1 Thema.
Wie überzeugt man Klimawandel-Zweifler?
Tagein, tagaus, wiederholen die Medien in enervierender Regelmäßigkeit das Lamento vom menschengemachten Klimawandel, dem nötigen Klimaschutz, dem 1,5-Grad-Ziel und der bei zögerlichem Handeln drohenden Apokalypse. Gerne werden dabei passende Wetterstatistiken angeführt, die auch dem ungläubigsten Thomas klarmachen sollen, dass es hier keineswegs um mögliche Entwicklungen, sondern um knallharte Fakten geht.
Kein Zufall, dass die präsentierten Statistiken immer genau ins Bild passen: Wärmstes Jahr seit 1881, regenreichster Sommer, trockenster Sommer, schmelzendes Grönlandeis.
Der erfahrene Statistiker weiß natürlich, man kann die Zahlenbeispiele immer so auswählen, dass die intendierte Botschaft damit gestützt wird. Was nicht passt, das muss man ja auch nicht präsentieren. Deswegen bekommt das geneigte Publikum nur Statistiken zu sehen, die das Narrativ vom nahenden Klimaunheil vorbehaltlos stützen.
Auch Zweifler brauchen Bestätigung
Hier machen wir es umgekehrt. Im Juristenjargon: Wir suchen nicht einseitig nach der Schuld des Angeklagten, sondern befassen uns auch mit entlastenden Indizien.
Beigefügt sind 3 kleine Statistiken über das Wettergeschehen der letzten 66 Jahre in München. Es wird der Zeitraum von 1955 bis 2021 abgedeckt, damit sind wir schon in einer klimarelevanten Zeitspanne. Tatsächlich geht es nicht um singuläre Wetterereignisse, sondern um die Einordnung des Wetters im langfristigen Klimakontext. Ausgewählt wurden dazu die kältesten Temperaturen und die größten Regenmengen an einem Sommertag sowie die höchste Anzahl von Sommertagen mit einer Regenmenge über 1 l / m2 (entspricht 1 mm). Sommertage deshalb, weil der aktuelle Sommer 2021 tatsächlich schon ziemlich feucht war, was ja grundsätzlich in die Klimaprognose von den steigenden Regenmengen aufgrund der wärmeren und damit feuchteren Atmosphäre passt. Aber ist das wirklich so eindeutig?
Die Top 10 Jahre mit der höchsten Anzahl von Regentagen im Sommer
Werfen wir einen Blick auf Abb. 1.
Anzahl Sommerregentage
Abbildung 1: Die zehn Jahre mit der höchsten Anzahl von Sommertagen, an denen über 1 Liter/m2 Regen gefallen ist (seit 1955)
Man entnimmt der Darstellung, dass auch 2021 unter den Jahren mit einer hohen Anzahl von Sommerregentagen ist. Immerhin liegt der Sommer 2021 auf Platz 4. Die Plätze 1 und 2 sind aber von 1956 und 1957 belegt. Zunächst ist das also eine Bestätigung des Klima-Narratives. Andererseits fällt auf, dass 8 der 10 Jahre mit der höchsten Anzahl von Sommertagen, an denen über 1 Liter/m2 Regen gefallen war, in der linken Hälfte des Betrachtungszeitraums liegen. Das heißt nichts anderes als: Früher hat es im Sommer nicht weniger geregnet. Ganz im Gegenteil. In die 21 Jahre von 1955 bis 1975 fallen 7 der Top 10 Jahre mit vielen Sommerregentagen. Damals hatte also jedes dritte Jahr besonders viele Sommerregentage. Völlig anders im Zeitraum zwischen 1994 und 2020: Kein einziges Jahr mit besonders vielen Sommerregentagen, erst 2021 wieder. Mit anderen Worten: Die Sommer mit vielen Regentagen gab es auch früher, und nicht einmal selten.
Die Top 10 Jahre mit den größten Regenmengen im Sommer
Und wie sieht es mit den Regenmengen aus? In Abb. 2 sind die Top 10 Jahre mit den größten Regenmengen im Sommer dargestellt.
Regenmengen im Sommer
Abbildung 2: Die zehn Jahre mit den größten Regenmengen im Sommer (seit 1955)
Wir haben ein ähnliches Bild, aber die Verteilung ist nicht ganz so extrem einseitig wie in Abb. 1. Sechs der Top 10 Jahre mit den größten Regenmengen im Sommer liegen zwischen 1955 und 1973. Nur zweimal zwischen 1996 und 2021 waren Regenmengen unter den Top 10 der Jahre mit den größten Regenmengen im Sommer zu verzeichnen. Das passt zur Aussage von Abb. 1: Auch früher gab es im Sommer viele Niederschläge. Der verregnete Sommer 2021 ist also keine Ausnahme, sondern entspricht eher dem, was man im mitteleuropäischen Sommerklima nun einmal erwarten muss.
Die Top 10 Jahre mit den kältesten Temperaturen an einem Sommertag
Neben den im Zuge des Klimawandels prognostizierten größeren Niederschlagsmengen geht es vor allem um die steigenden Temperaturen. Wie steht es damit?
In Abb. 3 sind die zehn Jahre mit den kältesten Temperaturen an einem Sommertag (seit 1955) grafisch dargestellt. Erstaunlicherweise liegen diese Top-Kaltsommertage nicht etwa weit in der Vergangenheit, sie gruppieren sich vielmehr um die Jahre 1997 bis 2009. Tatsächlich fallen 9 der Jahre mit den kältesten Sommertagen in die Zeit nach 1995. Von den Jahren davor war nur das Jahr 1986 unter den Top 10. Und keines der 30 Jahre von 1955 bis 1985 ist unter den Top 10 vertreten. Daher kann man nur resümieren: Kalte Sommertage waren früher nicht etwa kälter als heute. Und tatsächlich ist auch das Jahr 2021 unter den Top 10 Jahren mit den kältesten Temperaturen an einem Sommertag. Ganz so eindimensional ist das mit den steigenden Temperaturen offensichtlich nicht.
Kälteste Sommertage
Abbildung 3: Die zehn Jahre mit den kältesten Temperaturen an einem Sommertag (seit 1955)
Wird damit der Klimawandel widerlegt?
Aber nein! Selbstredend wird damit keineswegs bewiesen, dass der Klimawandel nicht stattfindet, zumal wir nur das Beispiel München betrachtet haben. Das war auch nicht das Ziel. Zweifellos ist der Klimawandel Fakt. Schon einfach deswegen, weil das Klima noch nie in der Erdgeschichte über längere Zeiträume konstant war. Es sollte lediglich gezeigt werden, dass die simple und beziehungslose Wetterbeobachtung eben keine stichhaltigen Belege für den (menschengemachten) Klimawandel liefern kann. Ebenso wenig taugen platte Statistiken dafür. Wir haben aber ansatzweise gesehen: Wenn man dies wollte, könnte man die Öffentlichkeit mit Statistiken sicher auch in Richtung einer vermeintlich bestehenden Klimastabilität manipulieren.
Einseitige Kommunikation ist Manipulation
Man muss sich vergegenwärtigen, dass die in den Medien angeführten „Beweise“ wenig bis nichts dazu beitragen, den (menschengemachten) Klimawandel zu bestätigen. Was dabei präsentiert wird, sind vielmehr gefilterte Realitätsausschnitte, ausgewählt mit dem Ziel, die intendierte Botschaft möglichst prägnant zu vermitteln. Am besten gelingt das mit geeignet aufbereiteten Schaubildern und Statistiken oder dem Hinweis auf dieses oder jenes dienliche Wetterphänomen. Wie wir einleitend gesehen haben, ist der Ansatz überaus erfolgreich. Man erkennt aber ebenso, dass die Kommunikation durchaus manipulative Züge trägt.
Auch wenn immer wieder auf die bestehende wissenschaftliche Mehrheitsmeinung zum Klimawandel verwiesen wird: Es geht letztlich um eine politische Agenda. Diese hat zwar ihren Ursprung in den Erkenntnissen von Wissenschaftlern, sie ist aber überfrachtet mit politischen Botschaften. Die klimatische Veränderung wird gleichermaßen einseitig und eindimensional dargestellt und es wird so getan, als könne man gleichsam durch Verzicht aufs Autofahren oder Fleischessen aus Deutschland heraus das Weltklima schützen und so den Klimawandel bremsen oder gar aufhalten.
Ein letztes Wort noch: Der katastrophale Starkregen in Rheinland-Pfalz und Nordrhein-Westfalen im Juni 2021 ist kein Beleg für den Klimawandel, auch wenn er von interessierten Kreisen gerne dafür herangezogen wird. Die Tragödie ist eher ein Zeugnis für eine unzulässig hohe Siedlungsdichte in hochwassergefährdeten Gebieten im Verein mit einem ungenügenden Katastrophenschutz.
Es soll in diesem Beitrag nicht um die Frage des besten Antriebskonzepts gehen. Nicht darum, ob Elektroautos weniger umweltschädlich und Verbrenner weniger umweltfreundlich sind. Ebenso wenig soll erörtert werden, ob das Attribut umweltfreundlich eher zum Elektroauto passt, beim Verbrenner indes die Assoziation umweltschädlich näher liegt. Das Thema ist vielmehr der Sinnzusammenhang der beiden Adjektive. Kann man, von trivialen Fällen abgesehen, sicher sagen, etwas sei umweltfreundlich oder umweltschädlich? Und was genau, sollte das jeweils bedeuten?
Semantik
Die Fragestellung hat zwei Hauptaspekte, eine philosophische und eine logisch-semantische. Wir beginnen mit dem Letzteren. „Wahre“ und „falsche“ Aussagen kann man im strengen Sinne nur innerhalb eines axiomatischen Systems treffen. Im realen Leben bewegt sich alles irgendwo dazwischen, vor allem auch deshalb, weil die Wortbedeutungen unscharf sind.
Konkret ist hier „umweltfreundlich“ ein genauso unscharfes Adjektiv wie „umweltschädlich“. In beiden Attributen klingt ein gewisser Absolutheitsanspruch durch, den zu verifizieren kaum gelingen kann. Mit Sicherheit wird man auch keinen allgemeinen Konsens darüber erzielen können, wo genau die Grenze liegt. Treffender ist es, stattdessen von „umweltschonend“ zu sprechen. Darin steckt viel weniger Wertung, obwohl immer noch offenbleibt, was genau damit gemeint sein mag. Sinnvoll erscheint zunächst einmal eine relative Definition. Die eine technische Lösung oder Handlungsweise ist umweltschonender als die andere, wenn sie in der Umwelt räumlich und zeitlich eine weniger starke Wirkung hinterlässt.
Logik
Darüber hinaus gibt es ein im eigentlichen Sinne logisches Problem. Es ist eine banale Erkenntnis, dass technische Systeme (und ihre Nutzung durch uns) die Umwelt immer in mehrerlei Hinsicht tangieren. Sie sind von ihr abhängig sind und beeinflussen sie. In der Regel reden wir hier von einer komplexen multifaktoriellen Beeinflussung bzw. Wechselbeziehung. Die Begründung für das Logikproblem ist einfach. Systeme, die durch mehr als nur einen Parameter charakterisiert werden (nur solche gibt es in der Realität), lassen sich nicht eindeutig in eine Ordnung bringen. Man kann nicht zwingend darlegen, dass das System mit der Charakteristik (2 5) besser oder schlechter ist als das System mit der Charakteristik (3 4). Das ist logisch unmöglich.
Ist ein Elektrofahrzeug mit einem Energieverbrauch von 20 kWh pro 100 km bei einer Zuladung von 500 kg und einer Akkukapazität von 80 kWh dem Konkurrenzprodukt mit 16 kWh pro 100 km, 400 kg Zuladung und 60 kWh Akkukapazität überlegen? Es kommt darauf an, wie man das Zusammenspiel der Eigenschaften im Hinblick auf den im Grundsatz willkürlich gesetzten Nutzwert beurteilt.
„Besser“ oder „umweltfreundlicher“ wird ein System erst durch die nicht im absoluten Sinne objektivierbare Bewertung, die wir ihm beimessen. Völlig gleich, wie viele vermeintlich gute Gründe wir dafür finden: Das Resultat wird durch die mehr oder weniger bewusste Entscheidung zur Zielsetzung determiniert und spiegelt daher zwangsläufig unser – unvollständiges – Bild von den Zusammenhängen.
Philosophische Sicht
Umwelt, das ist – im engeren Sinne – die Menge aller natürlichen (und im weiteren Sinne auch der künstlichen) Entitäten und ihrer Wechselbeziehungen. Wir sind Teil der Umwelt und alles, was wir tun und lassen, hat Folgen auf das System Umwelt. Schon durch unsere bloße Existenz beeinflussen wir die Umwelt. Mindestens nehmen wir Raum ein, und selbst bei größter Bescheidenheit benötigen wir Ressourcen für unser Überleben.
In unserer zwangsläufig anthropozentrischen und zuweilen auch romantisierenden Perspektive neigen wir dazu, unseren Einfluss auf die Umwelt, sofern er in Richtung einer Veränderung zurück zur Situation vor Auftreten des Menschen geht, als positiv und „umweltfreundlich“ zu begreifen. Den Einfluss in Richtung einer erzwungenen Anpassung der Umwelt auf die Existenz des Menschen und seiner Bedürfnisse verstehen wir oft pauschal als negativ. Aber auch hier gibt es kein simples Richtig oder Falsch. Gut oder schlecht, positiv oder negativ wird unser Wirken erst durch unser eigenes und letztlich willkürlich gesetztes Maß. Die Natur selbst kennt weder Gut noch Böse.
War der Einschlag des Meteoriten, dem vor 65 Mio. Jahren die Dinosaurier zum Opfer gefallen sind, eine Katastrophe? Oder war es doch ein segensreiches Ereignis, weil im Ökosystem mutmaßlich erst dadurch der Freiraum für die Entwicklung der Säugetiere und damit letztlich des Menschen entstanden ist?
Massive Eingriffe auf die Umwelt tragen das Risiko von Instabilität und disruptiver Veränderung in sich. Was danach folgt, muss nicht zwangsläufig „negativ“ sein, es ist aber jedenfalls ungewiss.
Ziel: Eingriffe klein halten
Wir kommen jetzt noch einmal auf den obigen Begriff zurück. Mit dem Attribut „umweltschonend“ messen wir uns am Ziel, den Einfluss auf die Umwelt möglichst klein zu halten. Das ist nicht unvernünftig, weil wir die Folgen unseres Handelns aufgrund der Komplexität des Gesamtsystems Umwelt zumindest in der Langfristperspektive nicht sicher vorhersagen können. Mehr noch, es fällt sogar schwer, die Auswirkung unseres Tuns auf die Umwelt überhaupt objektiv zu bestimmen. Was wir wahrnehmen, ist immer nur ein Ausschnitt der Wirklichkeit. Die Vielgestaltigkeit der tatsächlichen, offenen und versteckten, direkten und indirekten Wechselbeziehungen erlaubt uns allenfalls eine Annäherung an die komplexe Realität mit begrenzter Aussagekraft.
Ausgehend vom vorgefundenen stabilen Umweltsystem, liegt es in unserem unmittelbaren Interesse, die Stabilität des Systems zu erhalten. Denn eingedenk der immensen Komplexität wissen wir nicht, wohin es sich entwickeln wird, wenn es den Status quo verlässt und in der Konsequenz möglicherweise in einen Zustand der Instabilität gerät. Besser als das stark wertende Begriffspaar „umweltfreundlich“ vs. „umweltschädlich“ trifft daher die Fragestellung, inwiefern und in welchem Grade technische Lösungen und Handlungen als „umweltschonend“ bezeichnet werden können, den Kern der Diskussion.
Wie muss die Frage formuliert werden?
Die sinnvollere Fragestellung lautet daher: Ist ein Elektroauto „umweltschonender“ als ein Fahrzeug mit konventioneller Motorisierung? Entfaltet also ein Elektroauto im Hinblick auf seine Produktion und den Betrieb sowie der Energiebereitstellung im gesamten Lebenszyklus räumlich und zeitlich eine weniger starke Wirkung auf die Umwelt als ein sonst vergleichbares fossil betriebenes Fahrzeug? – Diese Frage zu beantworten, soll indes einem anderen Beitrag vorbehalten bleiben.


 und
und  . Der letztgenannte Wert heißt Formfaktor. Für die vorherrschenden Windverhältnisse in Mitteleuropa kann man den Formfaktor
. Der letztgenannte Wert heißt Formfaktor. Für die vorherrschenden Windverhältnisse in Mitteleuropa kann man den Formfaktor  ansetzen. In Süddeutschland liegt der Wert etwas darunter, an der Küste etwas darüber bei bis zu
ansetzen. In Süddeutschland liegt der Wert etwas darunter, an der Küste etwas darüber bei bis zu  .
.
 zu einem willkürlich gesetzten Zeitpunkt
zu einem willkürlich gesetzten Zeitpunkt  kleiner als die definierte Geschwindigkeit
kleiner als die definierte Geschwindigkeit  ist.
ist. 
 .
.

 aus der Nennleistung
aus der Nennleistung  und der Nenn-Windgeschwindigkeit
und der Nenn-Windgeschwindigkeit  gemäß
gemäß 


 . Abbildung 2 zeigt Beispiele für die Verteilung der Leistungsabgabe bei Formfaktoren um
. Abbildung 2 zeigt Beispiele für die Verteilung der Leistungsabgabe bei Formfaktoren um 


 gesetzt wird, dann gibt die obige Formel die Wahrscheinlichkeit des Ereignisses
gesetzt wird, dann gibt die obige Formel die Wahrscheinlichkeit des Ereignisses  wieder. Bei einer Erhöhung der Windstromproduktion um den Faktor
wieder. Bei einer Erhöhung der Windstromproduktion um den Faktor  ist folglich
ist folglich  die Wahrscheinlichkeit, dass weniger Windstrom als
die Wahrscheinlichkeit, dass weniger Windstrom als  produziert wird. Das ist demnach das Ereignis
produziert wird. Das ist demnach das Ereignis  . Eingesetzt in Formel (7) erhalten wir
. Eingesetzt in Formel (7) erhalten wir
 folgt der unmittelbar auswertbare Zusammenhang:
folgt der unmittelbar auswertbare Zusammenhang:
 ist das Verhältnis zwischen dem auf einen Zeitpunkt
ist das Verhältnis zwischen dem auf einen Zeitpunkt  . Wenn nun, wie oben, die Windstromproduktion um den Faktor
. Wenn nun, wie oben, die Windstromproduktion um den Faktor  gesetzt wird, dann ist das Ereignis
gesetzt wird, dann ist das Ereignis  identisch mit
identisch mit 

 statt 1 ergibt sich
statt 1 ergibt sich

 und das Versorgungsrisiko
und das Versorgungsrisiko  bei unterschiedlichen Formfaktoren
bei unterschiedlichen Formfaktoren 





 ist (also genauso viel Strom produziert wird, wie im Mittel benötigt wird), dann liegt die Versorgungssicherheit bei 0,3 (= 30 %) und das Versorgungsrisiko bei 0,7 (= 70 %). Vielfach wird diese Situation bereits als „Autarkie“ bezeichnet, obwohl es eigentlich nur „bilanzielle Autarkie“ ist und man tatsächlich in den überwiegenden Zeitabschnitten eines Jahres auf externe Stromlieferungen angewiesen ist.
ist (also genauso viel Strom produziert wird, wie im Mittel benötigt wird), dann liegt die Versorgungssicherheit bei 0,3 (= 30 %) und das Versorgungsrisiko bei 0,7 (= 70 %). Vielfach wird diese Situation bereits als „Autarkie“ bezeichnet, obwohl es eigentlich nur „bilanzielle Autarkie“ ist und man tatsächlich in den überwiegenden Zeitabschnitten eines Jahres auf externe Stromlieferungen angewiesen ist. liegt, dann erhalten wir eine Versorgungssicherheit von 0,15 (= 15 %) und ein Versorgungsrisiko von 0,85 (= 85 %). Wenn im Jahresverlauf summarisch doppelt so viel Strom als benötigt produziert (Produktionsfaktor
liegt, dann erhalten wir eine Versorgungssicherheit von 0,15 (= 15 %) und ein Versorgungsrisiko von 0,85 (= 85 %). Wenn im Jahresverlauf summarisch doppelt so viel Strom als benötigt produziert (Produktionsfaktor  ), so ergibt sich eine theoretische Versorgungssicherheit von 0,47 (= 47 %) und ein Versorgungsrisiko von 0,53 (= 53 %) .
), so ergibt sich eine theoretische Versorgungssicherheit von 0,47 (= 47 %) und ein Versorgungsrisiko von 0,53 (= 53 %) . liegt das Versorgungsrisiko immer noch bei 0,23 (= 23 %), also Versorgungssicherheit 0,77 (= 77 %). Und sogar bei
liegt das Versorgungsrisiko immer noch bei 0,23 (= 23 %), also Versorgungssicherheit 0,77 (= 77 %). Und sogar bei  , wenn also der in der Jahressumme benötigte Windstrom den Bedarf um den Faktor 100 übersteigt – was ja in der Praxis überhaupt nicht finanzierbar ist – bleibt das Versorgungsrisiko bei 0,055 (= 5,5 %). Wir erhalten also lediglich eine Versorgungssicherheit 0,955 (= 95,5 %). Trotz des utopisch hohen Aufwandes wäre zeitanteilig an 16 Tagen eines Jahres die Stromversorgung nicht gewährleistet.
, wenn also der in der Jahressumme benötigte Windstrom den Bedarf um den Faktor 100 übersteigt – was ja in der Praxis überhaupt nicht finanzierbar ist – bleibt das Versorgungsrisiko bei 0,055 (= 5,5 %). Wir erhalten also lediglich eine Versorgungssicherheit 0,955 (= 95,5 %). Trotz des utopisch hohen Aufwandes wäre zeitanteilig an 16 Tagen eines Jahres die Stromversorgung nicht gewährleistet. und dem Produktionsfaktor
und dem Produktionsfaktor 
 einen Quotienten von
einen Quotienten von  und somit eine Versorgungssicherheit von
und somit eine Versorgungssicherheit von  . Wenn nun der Produktionsfaktor auf
. Wenn nun der Produktionsfaktor auf  erhöht wird, ist der Quotient
erhöht wird, ist der Quotient  und die Versorgungssicherheit
und die Versorgungssicherheit  , d.h., die Versorgungssicherheit steigt überproportional mit dem Produktionsfaktor.
, d.h., die Versorgungssicherheit steigt überproportional mit dem Produktionsfaktor. für den Produktionsfaktor sein Maximum. Diesen Wert bestimmt man zu
für den Produktionsfaktor sein Maximum. Diesen Wert bestimmt man zu 
 bekommen wir z.B.
bekommen wir z.B.
 werden die jeweiligen Maxima mit Effizienzwerten von
werden die jeweiligen Maxima mit Effizienzwerten von  bei Produktionsfaktoren
bei Produktionsfaktoren  erreicht. Bei größeren Produktionsfaktoren ist die Investitionseffizienz in jedem Falle geringer.
erreicht. Bei größeren Produktionsfaktoren ist die Investitionseffizienz in jedem Falle geringer. (s. Abb. 7, rechts des Maximums der blauen Kurve). Bei ausschließlicher Betrachtung der Windstromproduktion und ohne die Berücksichtigung von (teuren) Speichern ist daher der Ausbau der Windkraft wesentlich über die Grenze
(s. Abb. 7, rechts des Maximums der blauen Kurve). Bei ausschließlicher Betrachtung der Windstromproduktion und ohne die Berücksichtigung von (teuren) Speichern ist daher der Ausbau der Windkraft wesentlich über die Grenze 


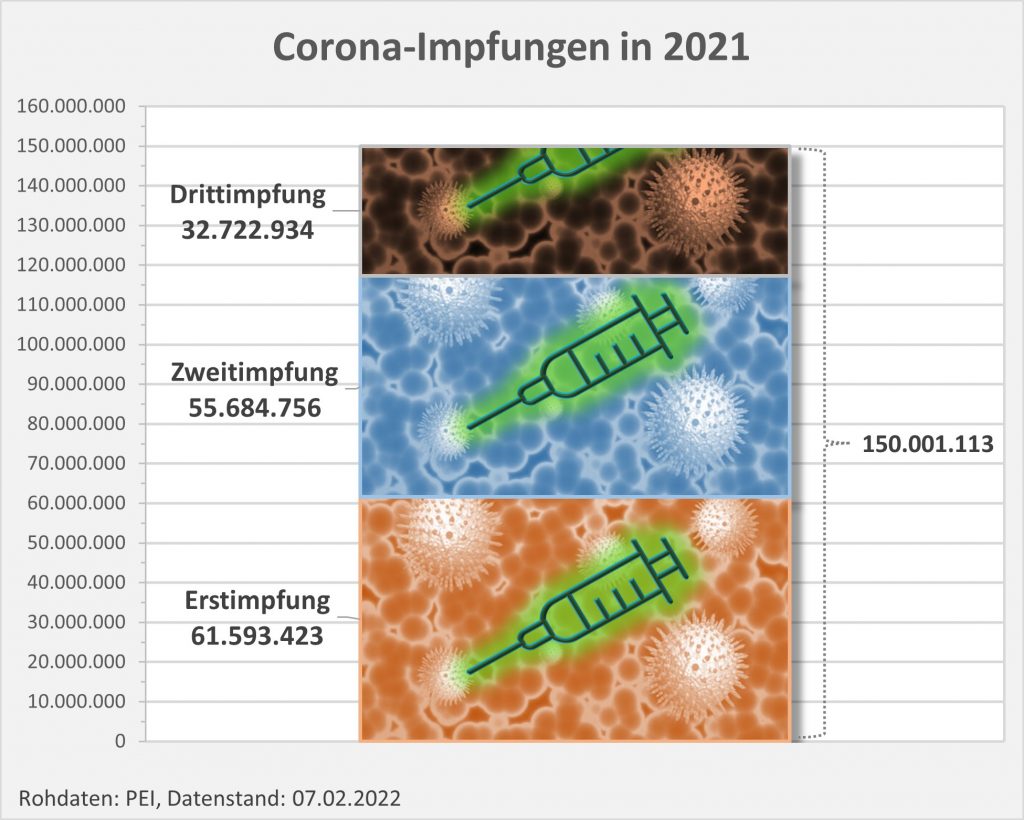
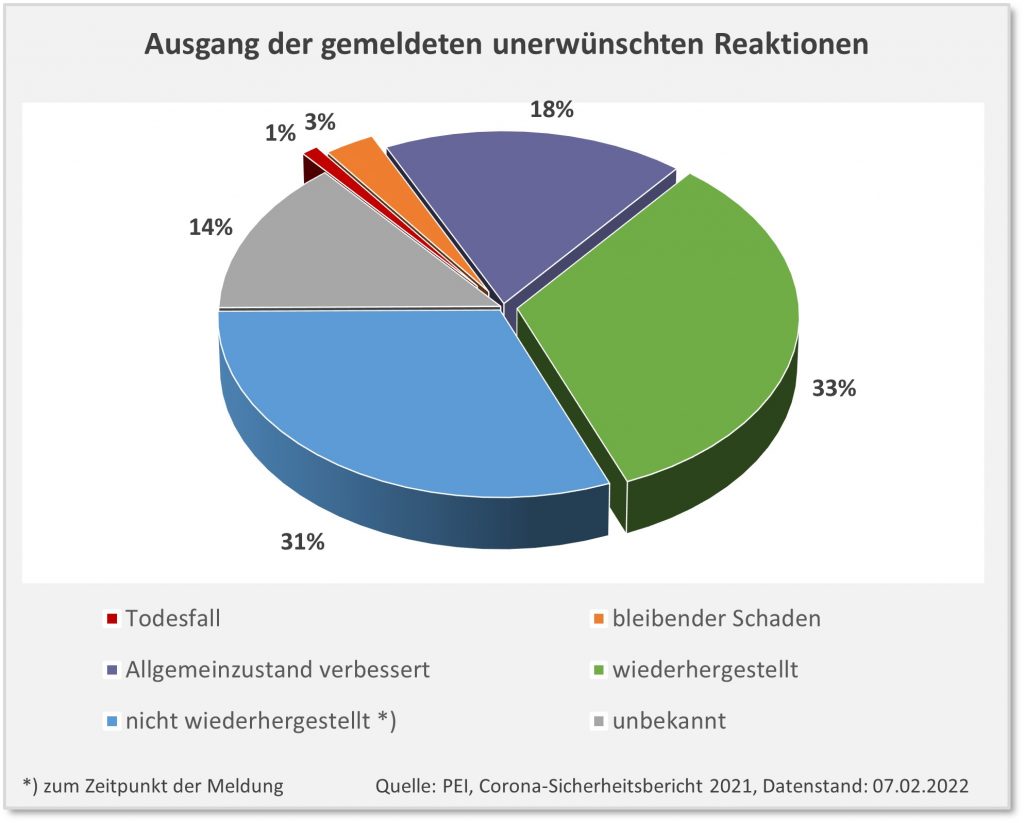
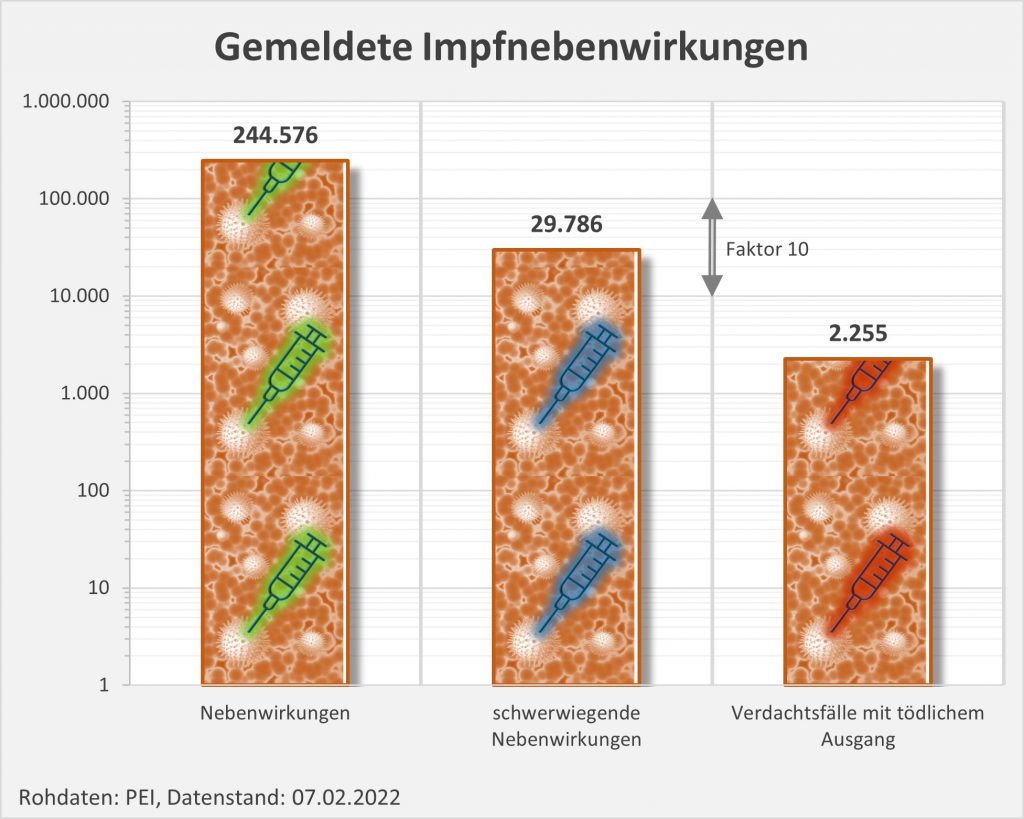
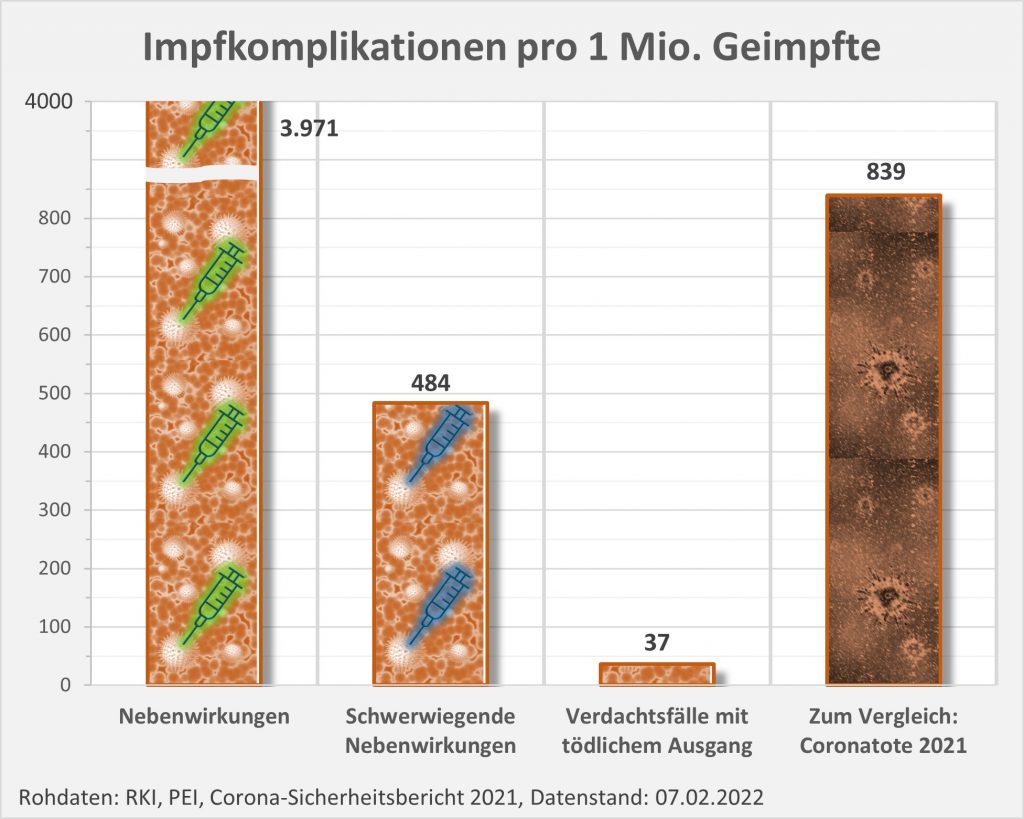
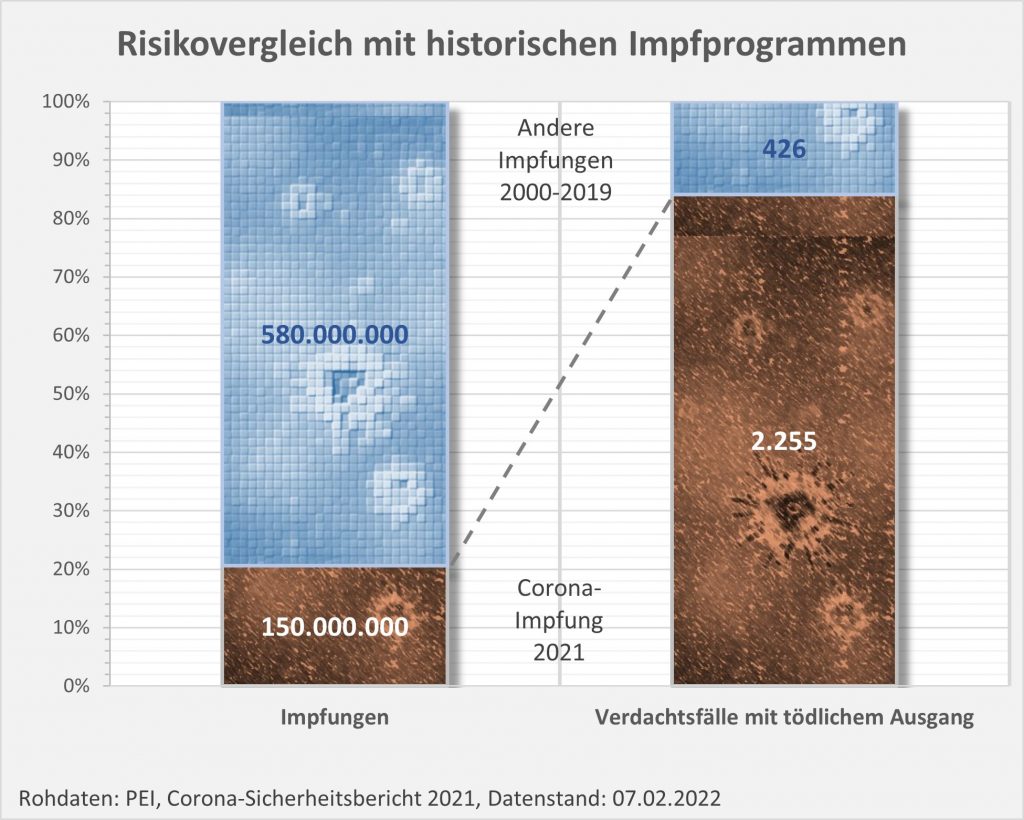
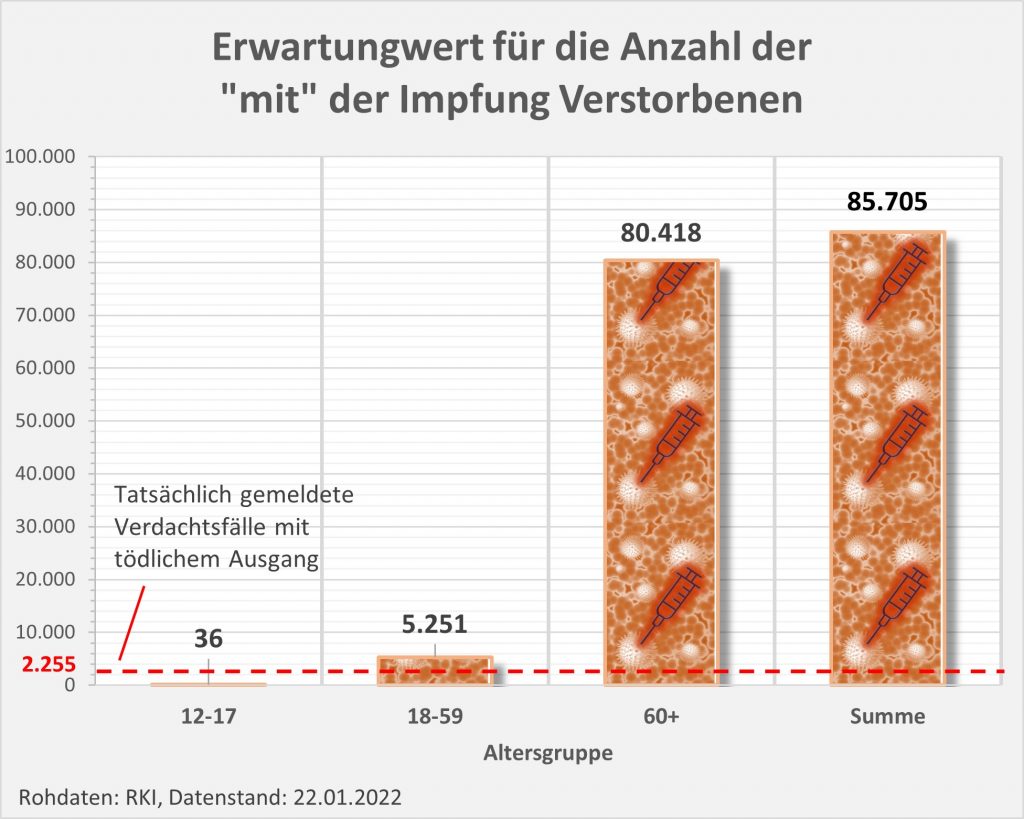
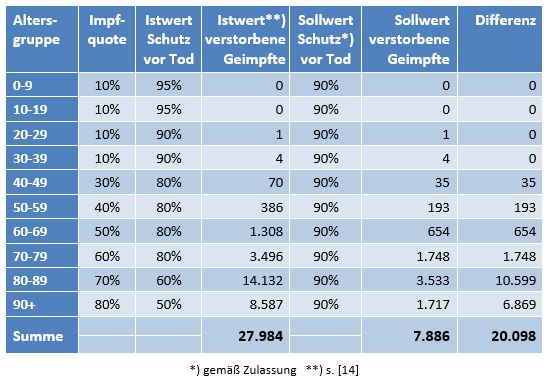
 die beobachtete Ist-Wirksamkeit des Impfstoffs und
die beobachtete Ist-Wirksamkeit des Impfstoffs und  die hypothetische Soll-Wirksamkeit. Entsprechend bezeichnen wir mit
die hypothetische Soll-Wirksamkeit. Entsprechend bezeichnen wir mit  die tatsächliche Anzahl der verstorbenen Geimpften und mit
die tatsächliche Anzahl der verstorbenen Geimpften und mit  die hypothetische Anzahl unter der Annahme der Soll-Wirksamkeit. Es gilt folgender Zusammenhang (s. [14], Analogie zu Formel (34) bei unveränderter Impfquote):
die hypothetische Anzahl unter der Annahme der Soll-Wirksamkeit. Es gilt folgender Zusammenhang (s. [14], Analogie zu Formel (34) bei unveränderter Impfquote):
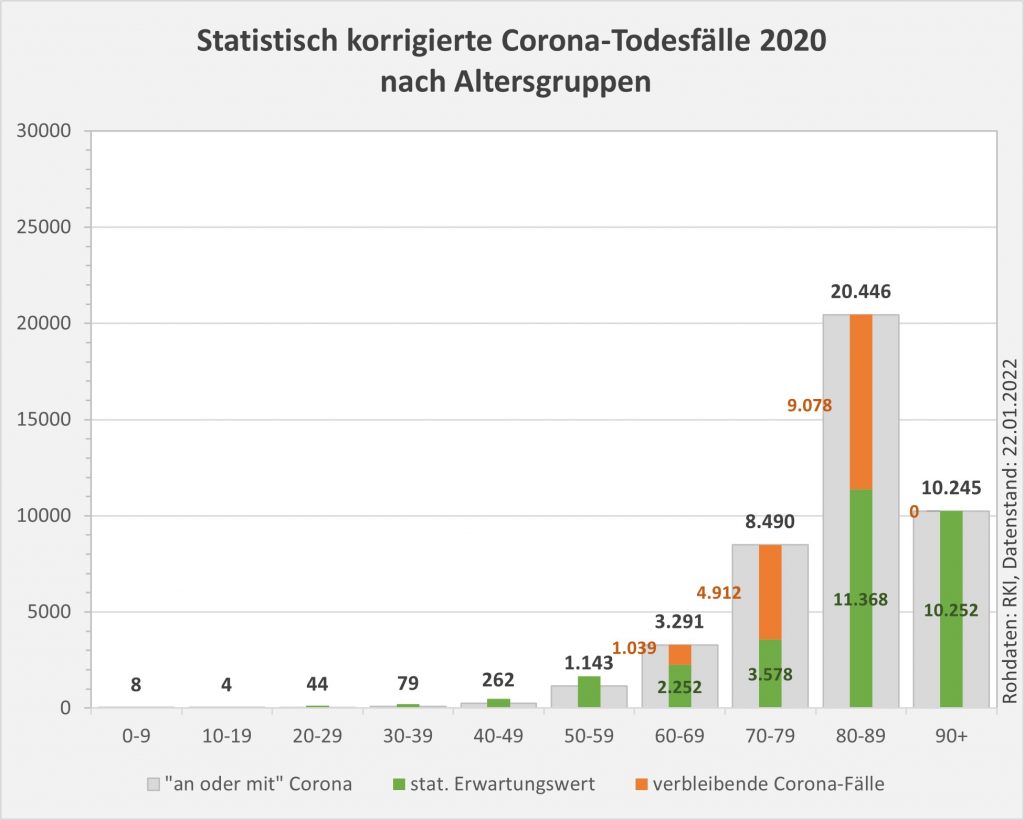
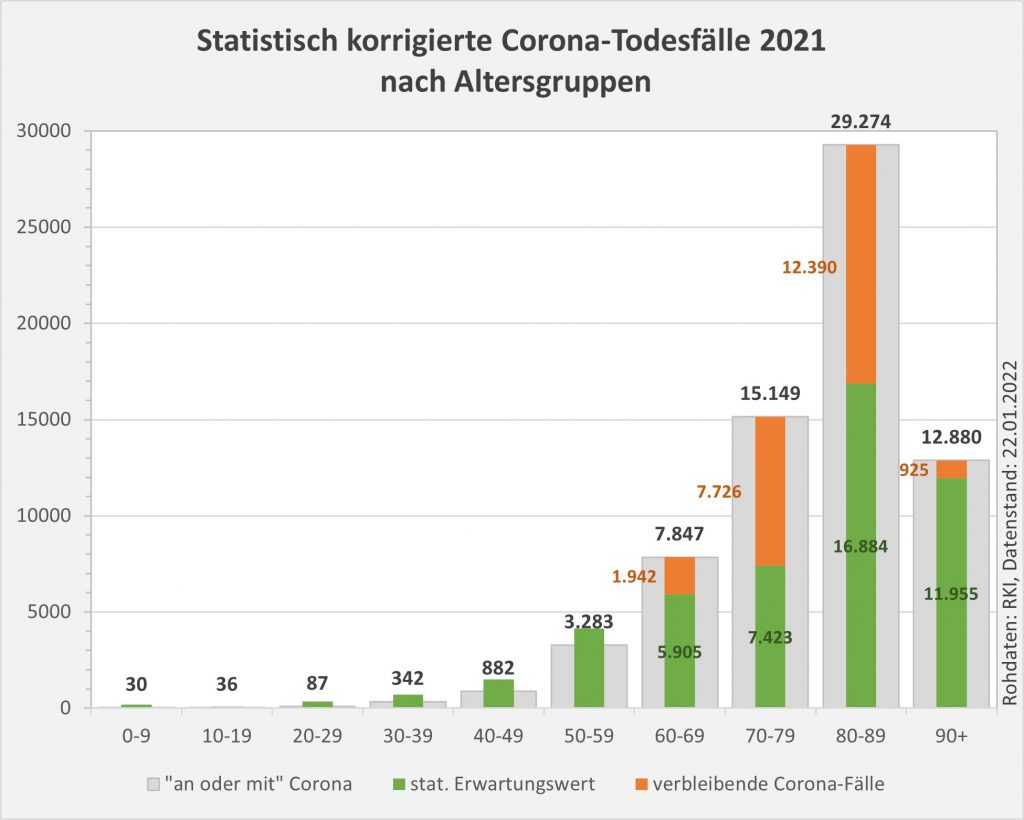
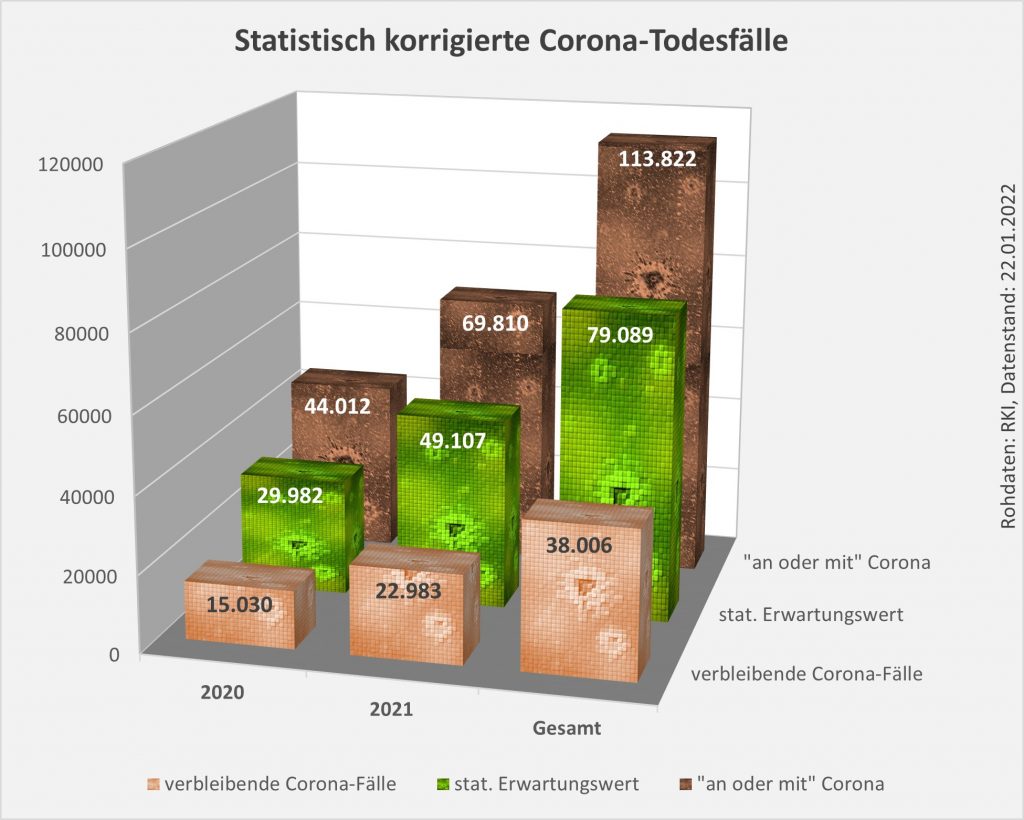



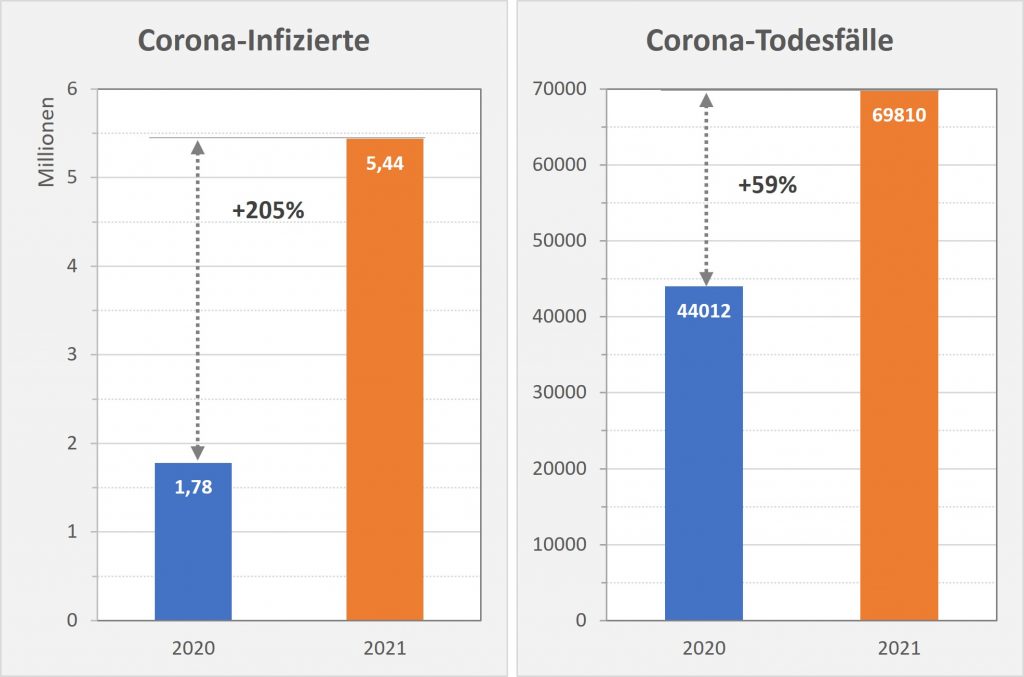
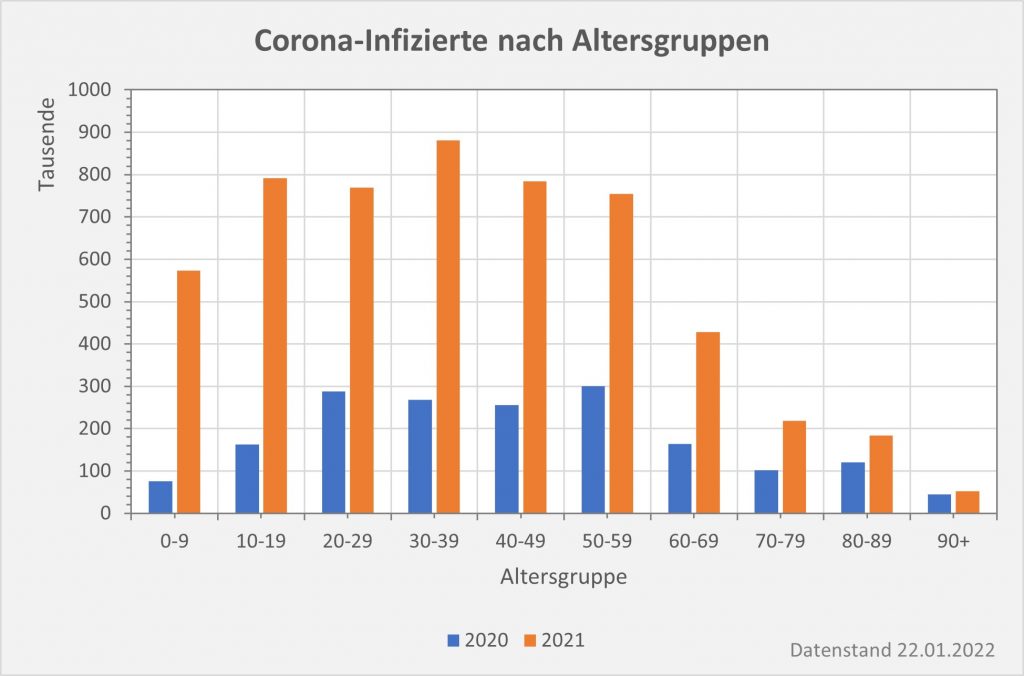

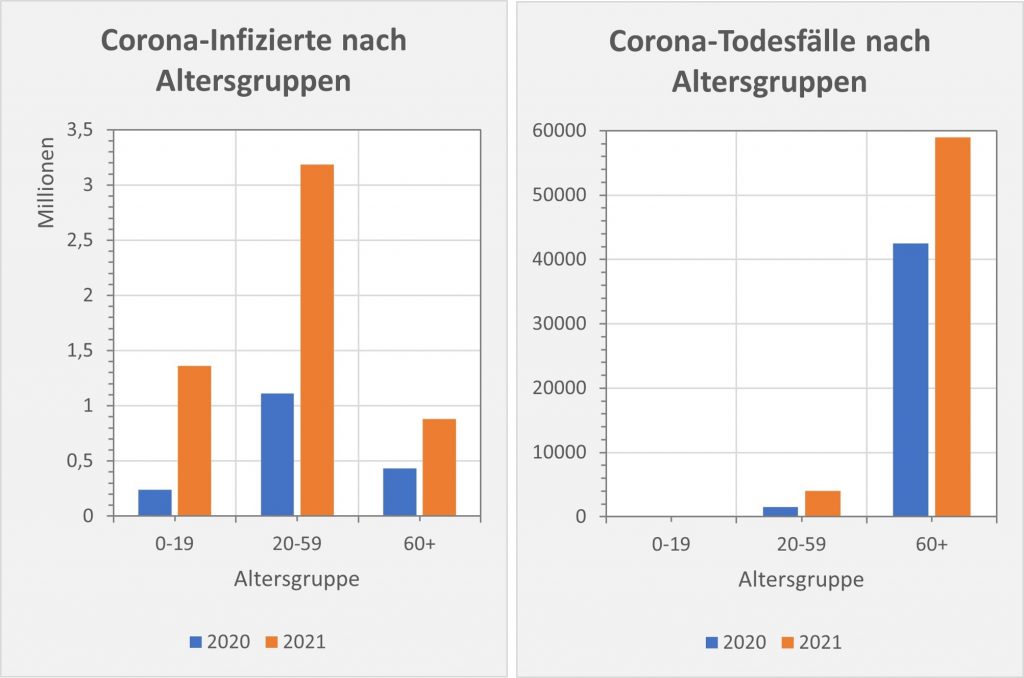
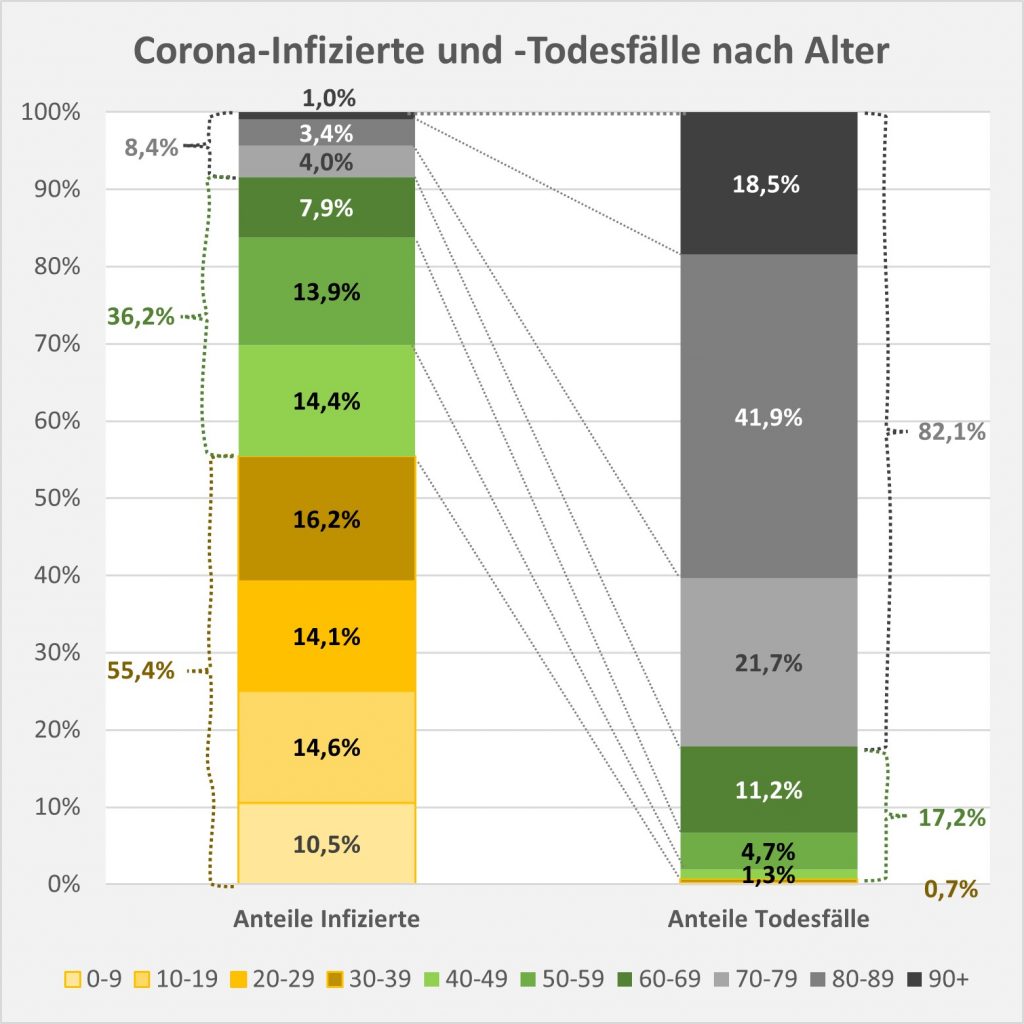
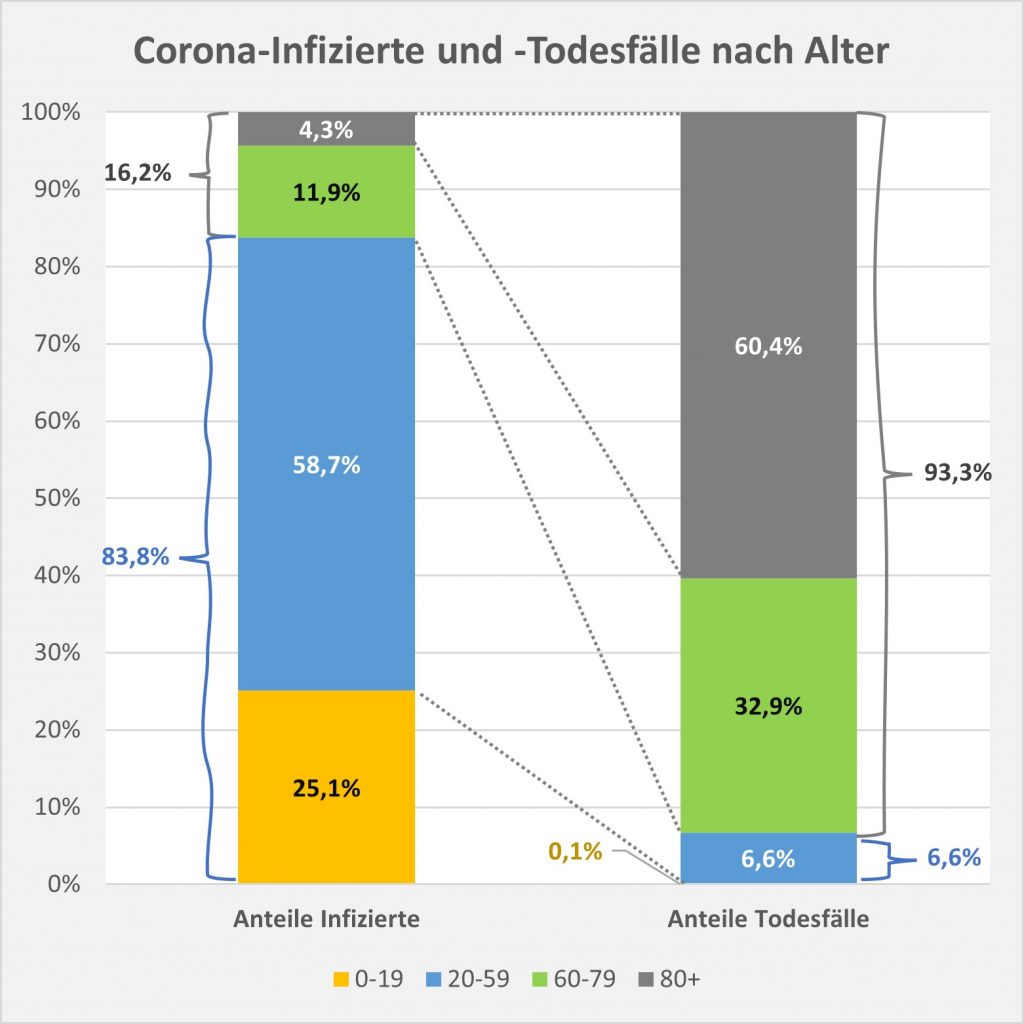
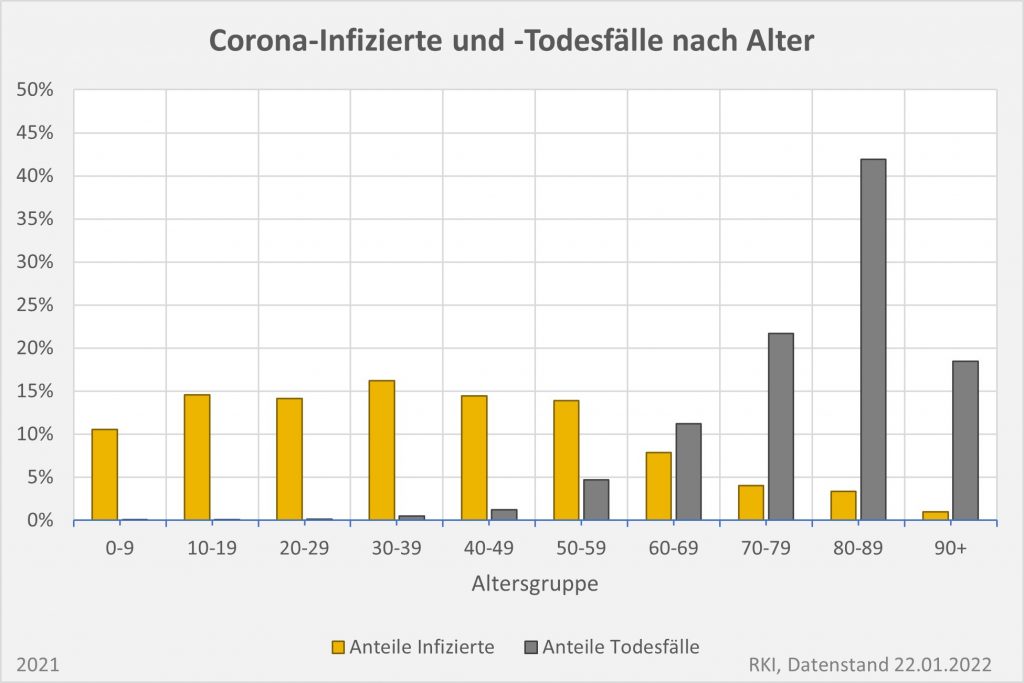
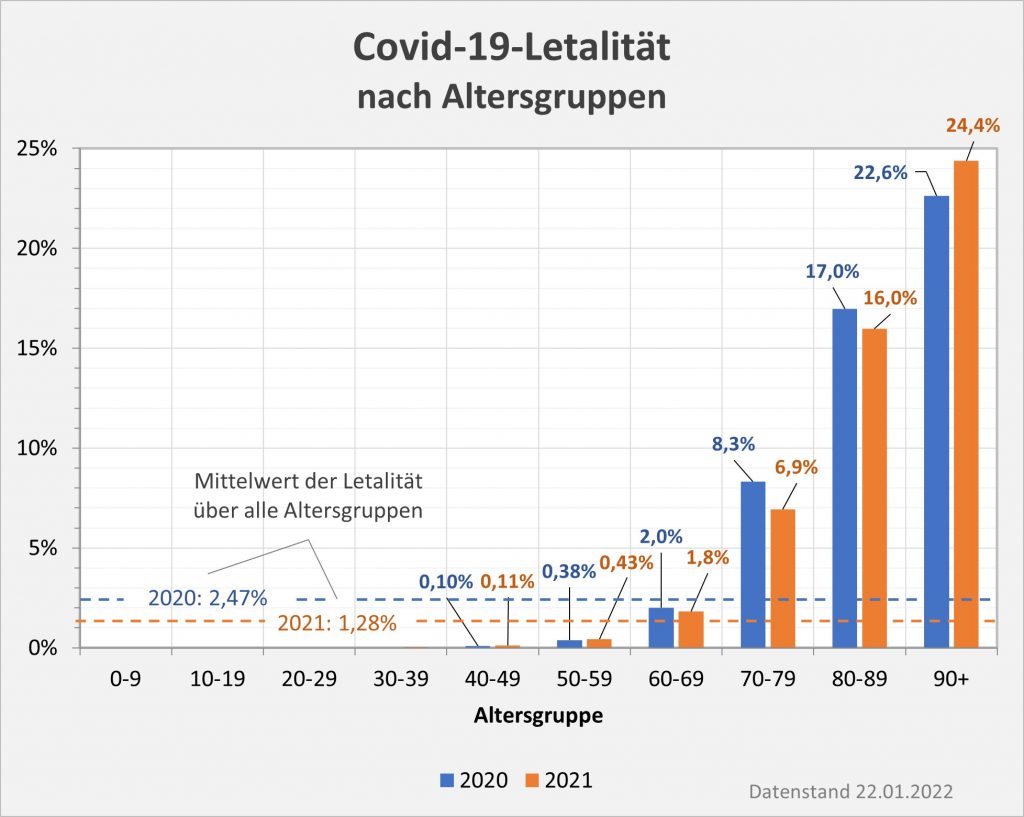
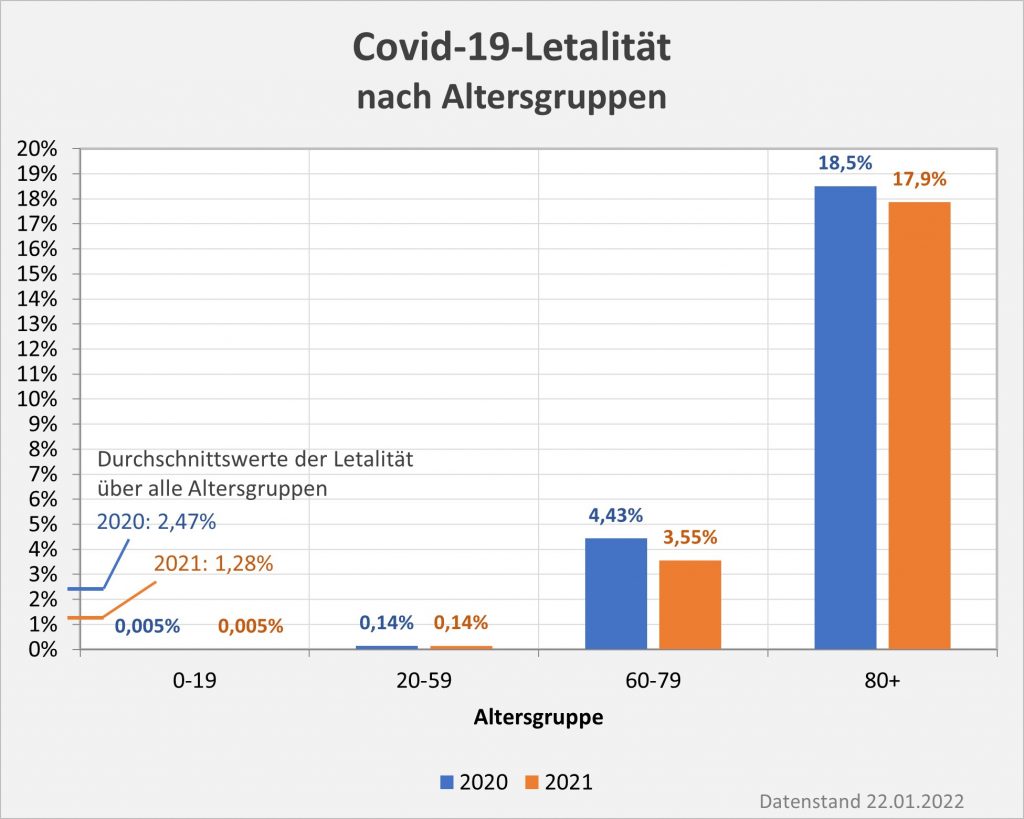
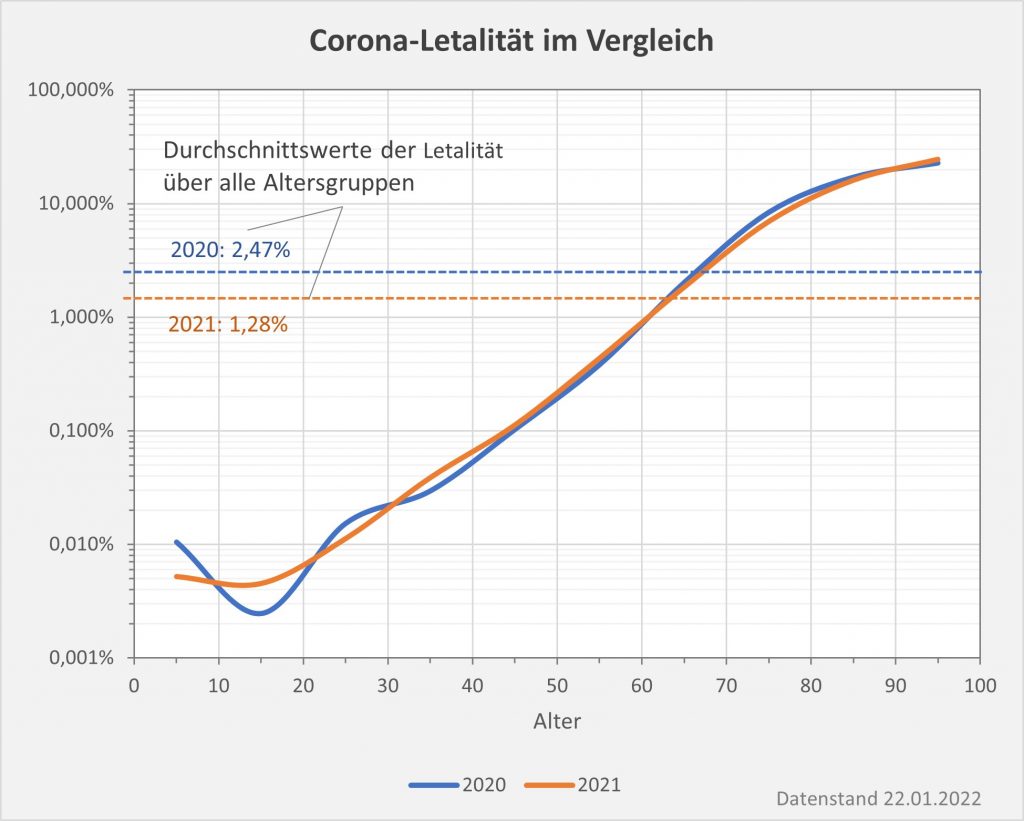
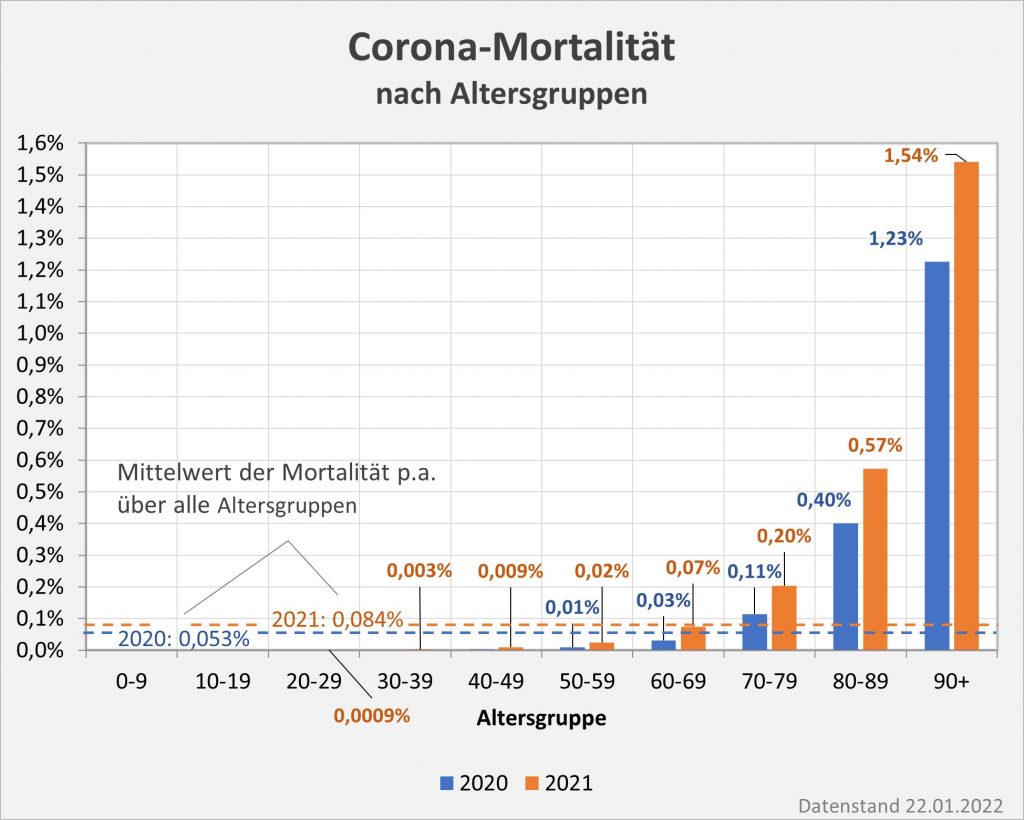
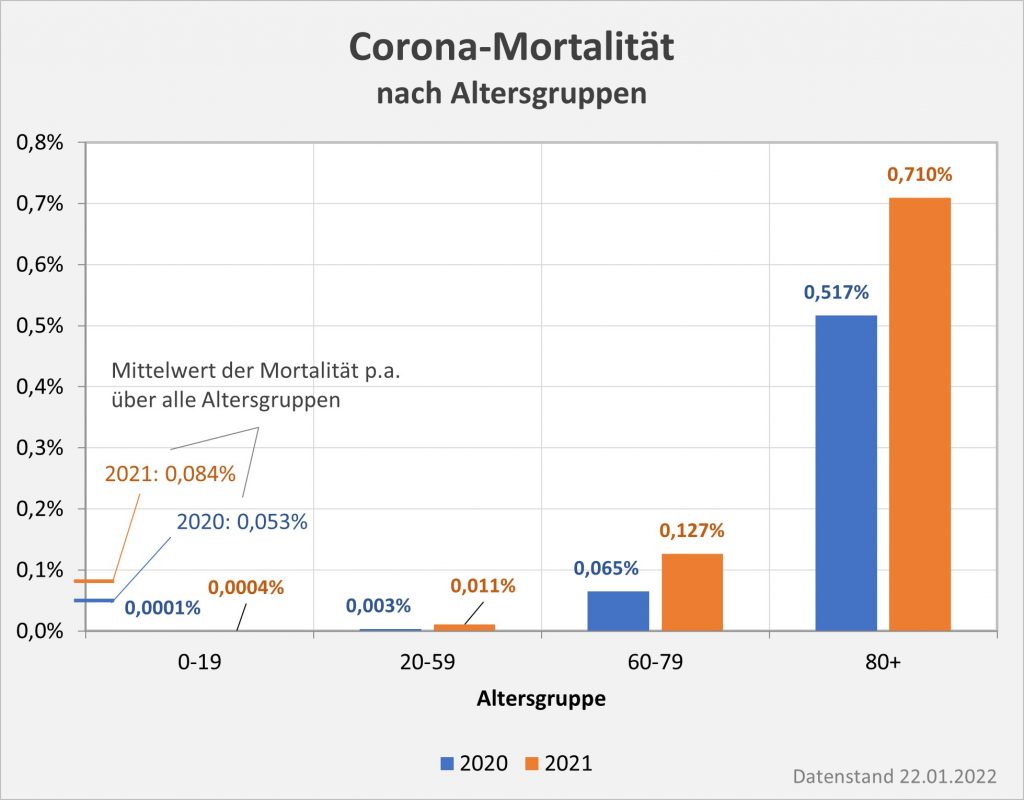
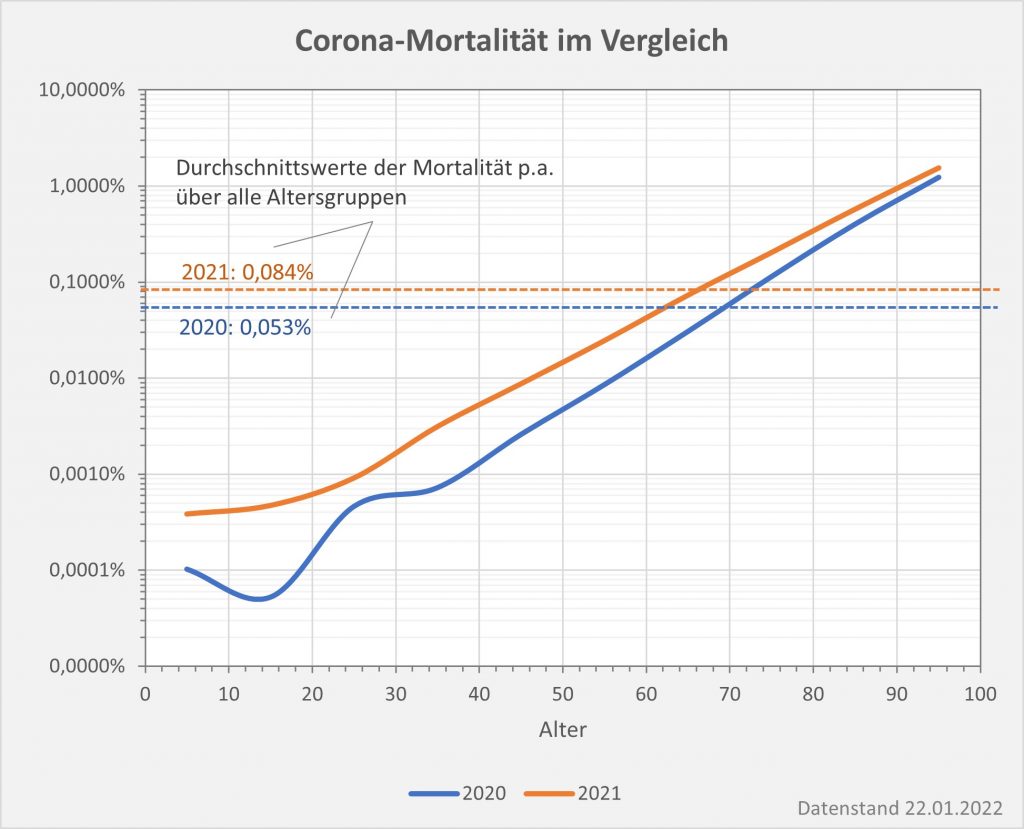
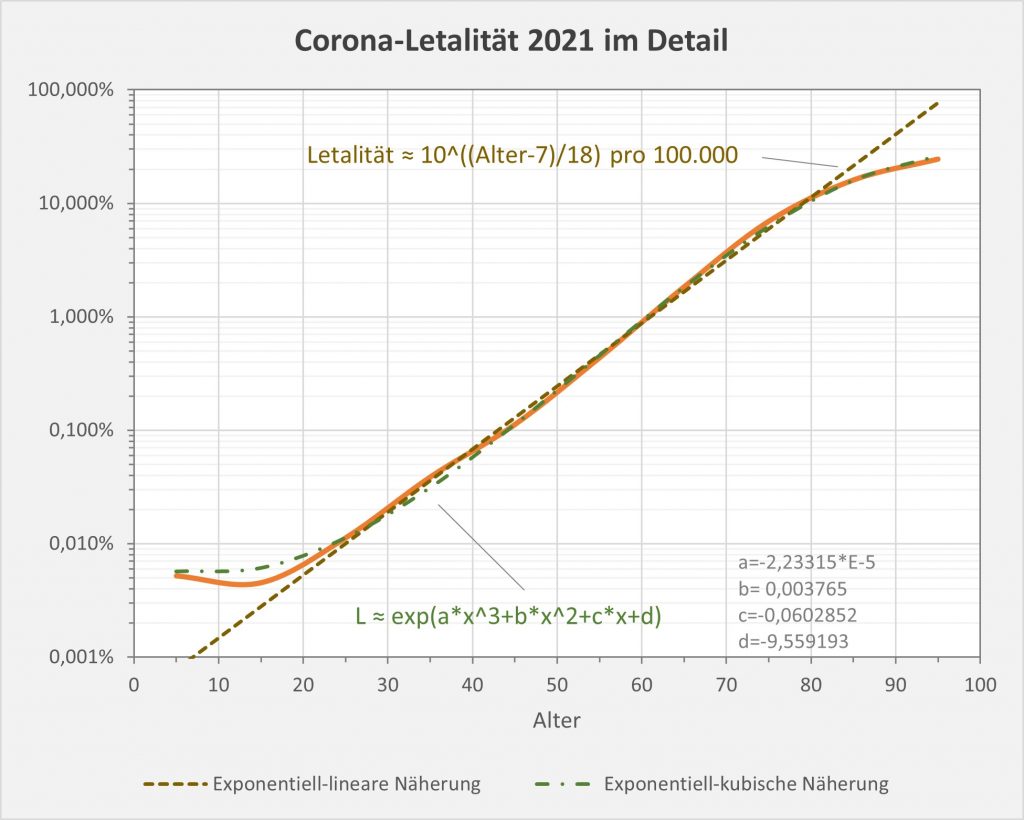
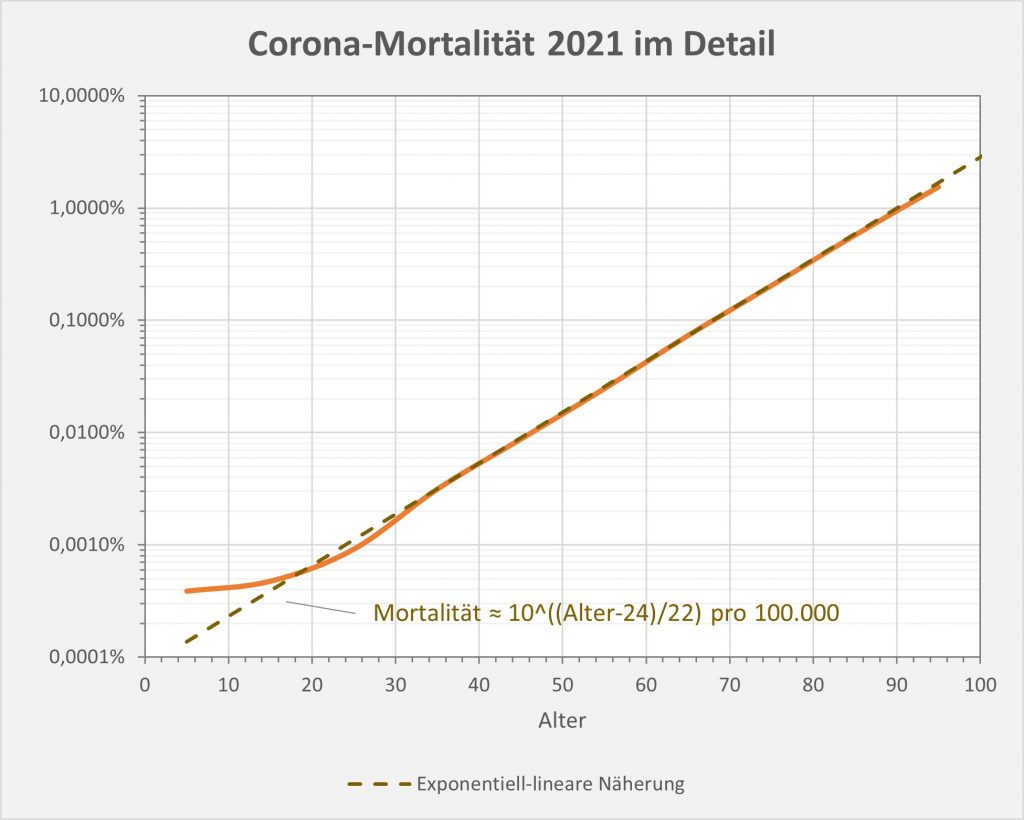
 und
und  , indirekt zu berechnen. Gleiches geht natürlich auch für die Ungeimpften (
, indirekt zu berechnen. Gleiches geht natürlich auch für die Ungeimpften ( und
und  ).
).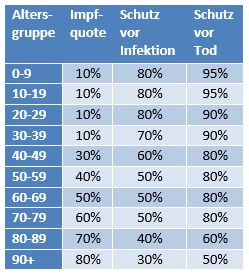
 für Geimpfte:
für Geimpfte:
 für Ungeimpfte:
für Ungeimpfte:
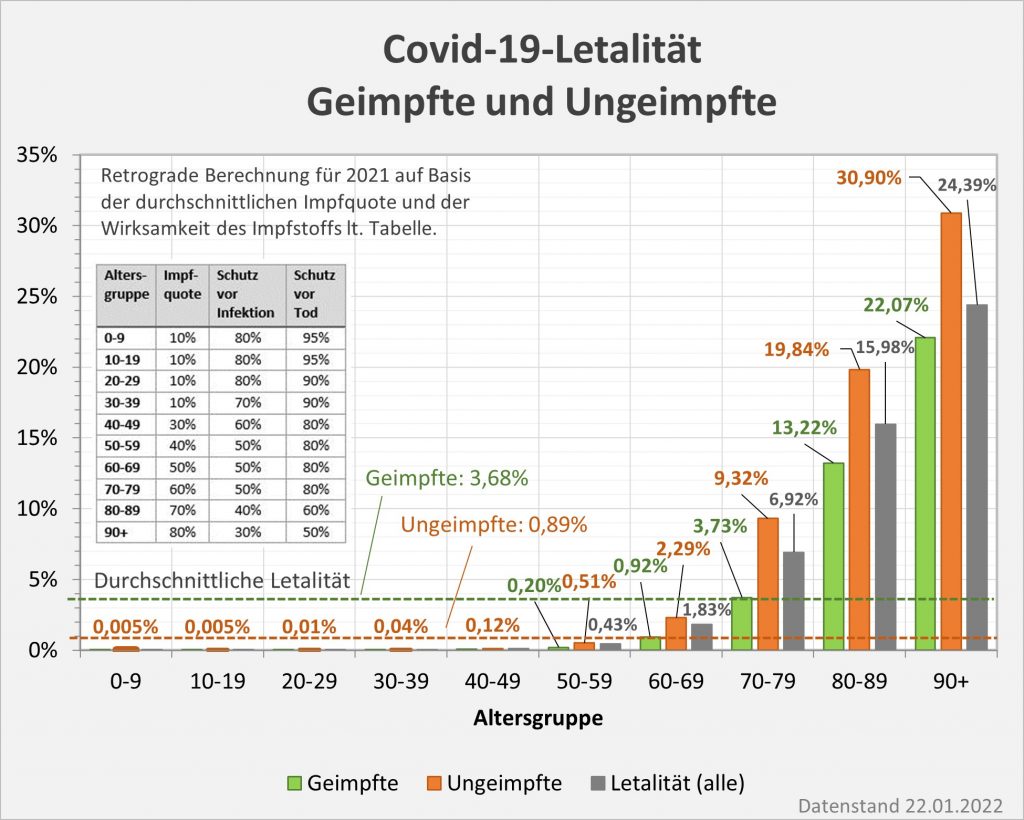
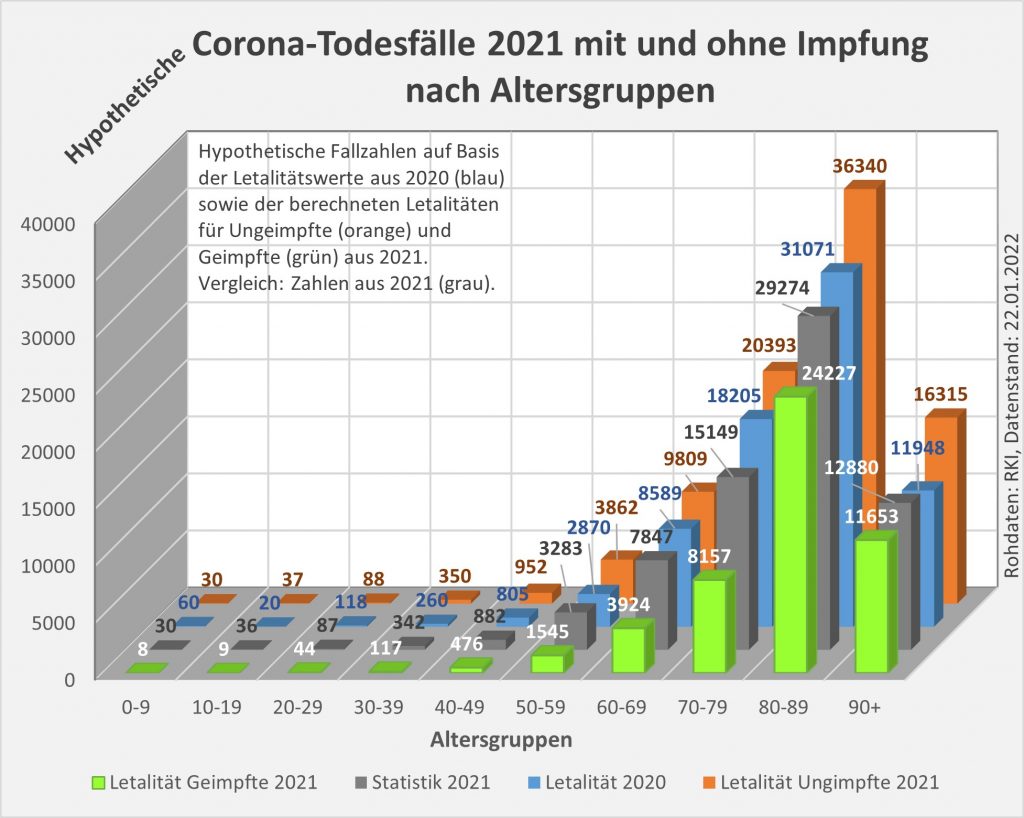
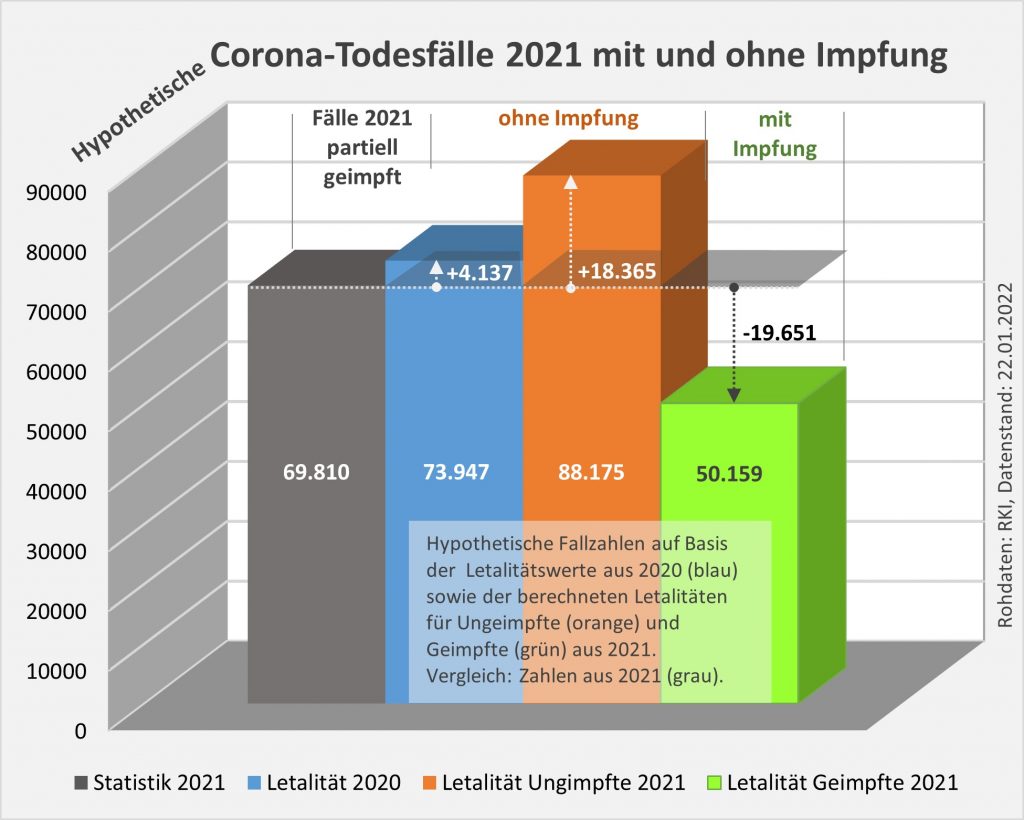
 und/oder Wirksamkeit
und/oder Wirksamkeit  zur Anwendung.
zur Anwendung.




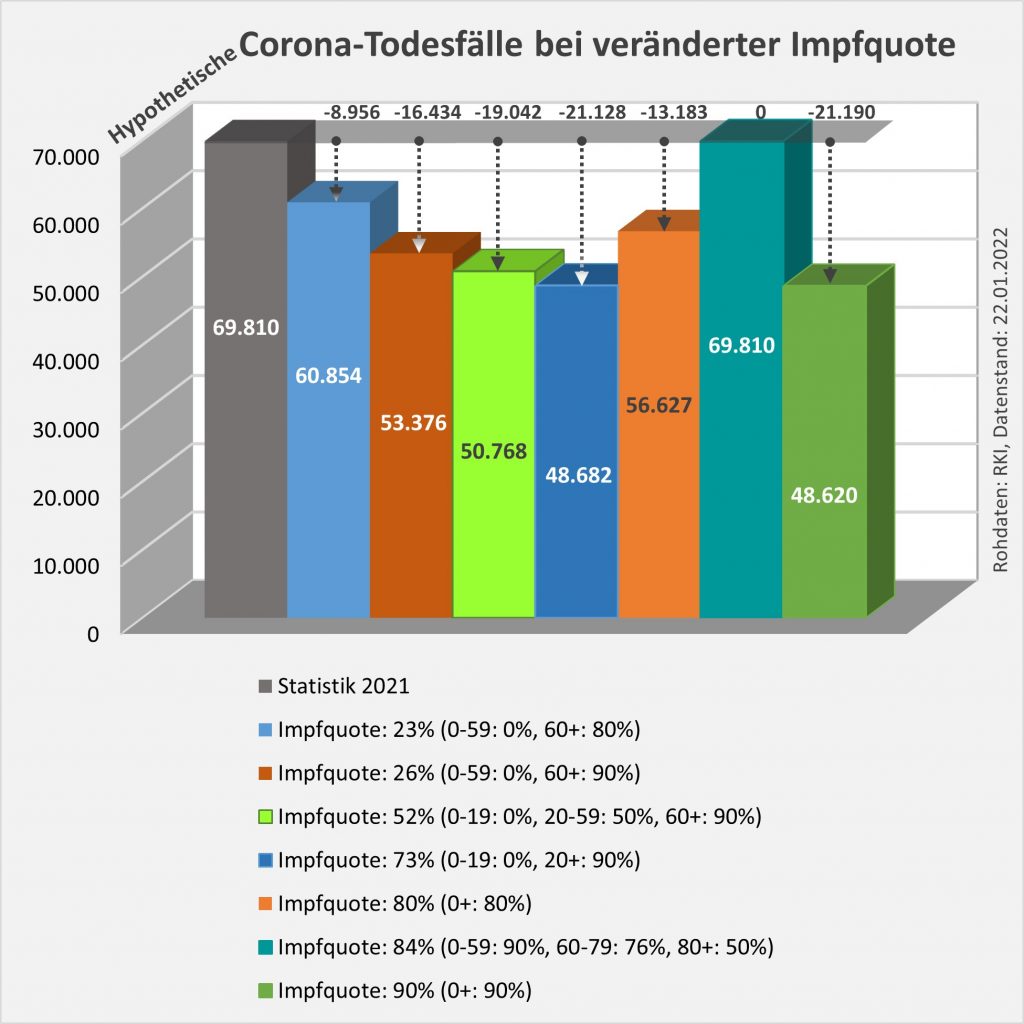
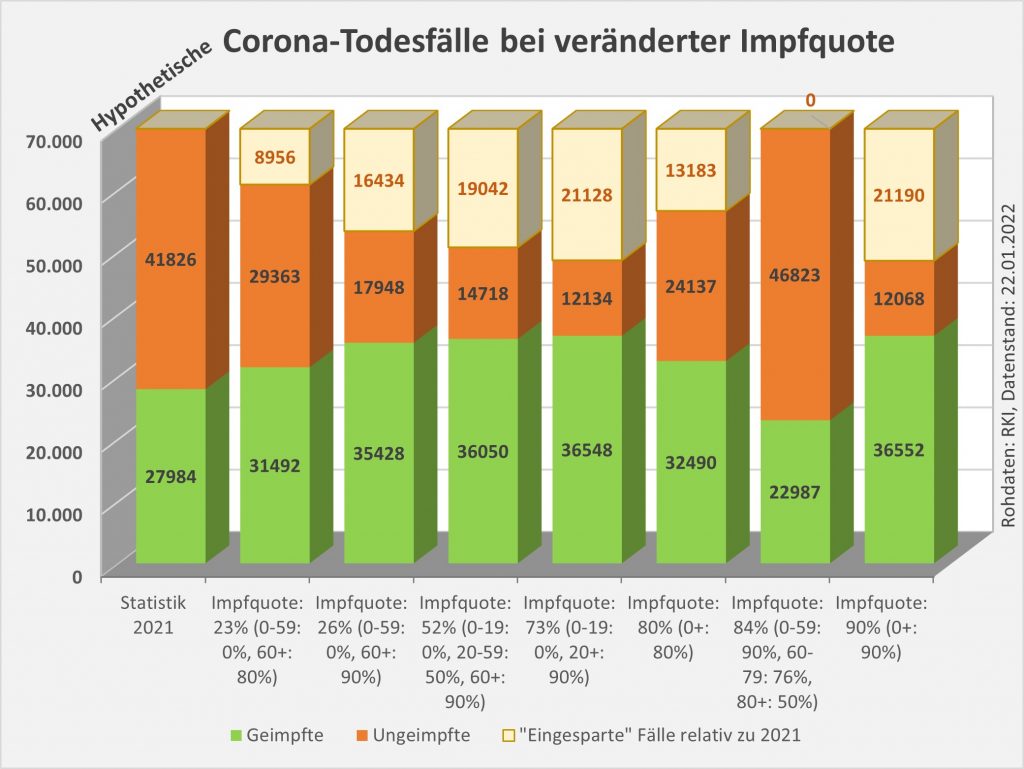
 pro 100.000 Infizierten kann durch die folgende exponentiell-lineare Näherungsformel ausgedrückt werden:
pro 100.000 Infizierten kann durch die folgende exponentiell-lineare Näherungsformel ausgedrückt werden:

 . Daher kann man festhalten, dass sich das Corona-Sterberisiko p.a. bei vorliegender Infektion pro etwa 5,5 Lebensjahren verdoppelt.
. Daher kann man festhalten, dass sich das Corona-Sterberisiko p.a. bei vorliegender Infektion pro etwa 5,5 Lebensjahren verdoppelt.
 pro 100.000 Einwohnern ist durch die folgende Beziehung gegeben:
pro 100.000 Einwohnern ist durch die folgende Beziehung gegeben:

 kann man ebenfalls konstatieren, dass sich das Corona-Sterberisiko p.a. pro etwa 6,5 Lebensjahren verdoppelt.
kann man ebenfalls konstatieren, dass sich das Corona-Sterberisiko p.a. pro etwa 6,5 Lebensjahren verdoppelt. in Prozent kann folgendermaßen formuliert werden:
in Prozent kann folgendermaßen formuliert werden:




 und
und  die entsprechenden Impfstoff-Wirksamkeiten für den Schutz vor Infektion und den Schutz vor Tod.
die entsprechenden Impfstoff-Wirksamkeiten für den Schutz vor Infektion und den Schutz vor Tod.






 bringt die Wirkung der Massenimpfung in kompakter Form zum Ausdruck:
bringt die Wirkung der Massenimpfung in kompakter Form zum Ausdruck:
 und für
und für  gibt es keine verstorbenen Geimpften, für
gibt es keine verstorbenen Geimpften, für  gibt es keine Ungeimpften.
gibt es keine Ungeimpften.  . Daher sind die Todesfallzahlen bei Geimpften und Ungeimpften gleich hoch, wenn das Zahlenverhältnis zwischen Geimpften und Ungeimpften reziprok proportional zum Verhältnis der Todesfallrisiken ist, wenn also
. Daher sind die Todesfallzahlen bei Geimpften und Ungeimpften gleich hoch, wenn das Zahlenverhältnis zwischen Geimpften und Ungeimpften reziprok proportional zum Verhältnis der Todesfallrisiken ist, wenn also 

 . Der Einfachheit halber verzichten wir dabei auf das Subskript, wenn es aus dem Zusammenhang heraus keine Verwechslungen geben kann;
. Der Einfachheit halber verzichten wir dabei auf das Subskript, wenn es aus dem Zusammenhang heraus keine Verwechslungen geben kann;  und den Bezugswerten bei der Impfquote
und den Bezugswerten bei der Impfquote  und der Wirksamkeit
und der Wirksamkeit  . Dabei setzen wir eine unveränderte Wirksamkeit
. Dabei setzen wir eine unveränderte Wirksamkeit  ,
,  ,
,  , die Bezugswerte mit
, die Bezugswerte mit  ,
,  ,
,  .
. 
 infizierte Geimpfte. Wenn wir nun die Impfquote auf 70% erhöhen, dann haben wir 700 Geimpfte und nur noch 300 Ungeimpfte. Entsprechend geht die Zahl der infizierten Ungeimpften auf
infizierte Geimpfte. Wenn wir nun die Impfquote auf 70% erhöhen, dann haben wir 700 Geimpfte und nur noch 300 Ungeimpfte. Entsprechend geht die Zahl der infizierten Ungeimpften auf  zurück. Zugleich steigt die Anzahl der infizierten Geimpften auf
zurück. Zugleich steigt die Anzahl der infizierten Geimpften auf  .
.  . Auf der anderen Seite wird die Anzahl der infizierten Geimpften entsprechend im Verhältnis der Impfquoten
. Auf der anderen Seite wird die Anzahl der infizierten Geimpften entsprechend im Verhältnis der Impfquoten  erhöht.
erhöht. . Ihre Anzahl verändert sich daher proportional zum Verhältnis der Restrisiken. Im Beispiel
. Ihre Anzahl verändert sich daher proportional zum Verhältnis der Restrisiken. Im Beispiel  . Zugleich sinkt die Gesamtzahl der Infizierten von
. Zugleich sinkt die Gesamtzahl der Infizierten von  auf
auf  .
.  zurück. Die Zahl der infizierten Geimpften verändert sich dagegen proportional zum Verhältnis
zurück. Die Zahl der infizierten Geimpften verändert sich dagegen proportional zum Verhältnis  auf
auf  .
. . Das ist das Verhältnis
. Das ist das Verhältnis  . Analog im zweiten Beispiel: Die Gesamtzahl der Infizierten verringert sich von
. Analog im zweiten Beispiel: Die Gesamtzahl der Infizierten verringert sich von  zurück. Schließlich stellt sich im dritten Fall bei der gleichzeitigen Veränderung von Impfquote und Wirksamkeit die neue Anzahl der Infizierten, also
zurück. Schließlich stellt sich im dritten Fall bei der gleichzeitigen Veränderung von Impfquote und Wirksamkeit die neue Anzahl der Infizierten, also  , entsprechend dem Verhältnis
, entsprechend dem Verhältnis  ein.
ein. 
 ,
,  ,
,  und die Bezugswerte mit
und die Bezugswerte mit  ,
,  ,
,  .
. 

 und
und  . Das Invarianz-Postulat wurde oben erläutert. Für die Gesamtletalität gilt dagegen
. Das Invarianz-Postulat wurde oben erläutert. Für die Gesamtletalität gilt dagegen  .
. gehen wir aus von
gehen wir aus von


 vereinfacht sich die
vereinfacht sich die 
 und den ursprünglichen Infektionszahlen
und den ursprünglichen Infektionszahlen  für diesen Spezialfall deutlich kürzer fassen lässt:
für diesen Spezialfall deutlich kürzer fassen lässt:
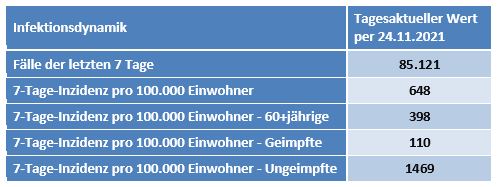
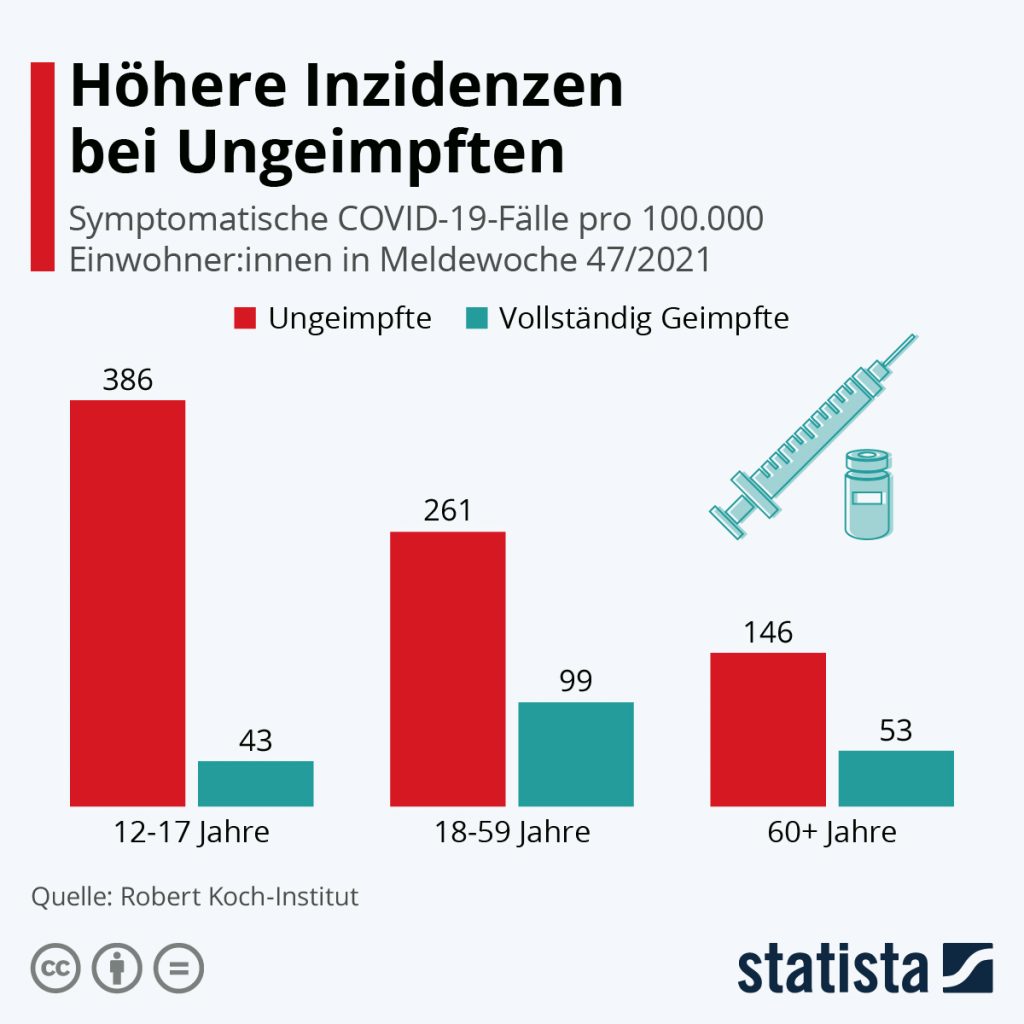
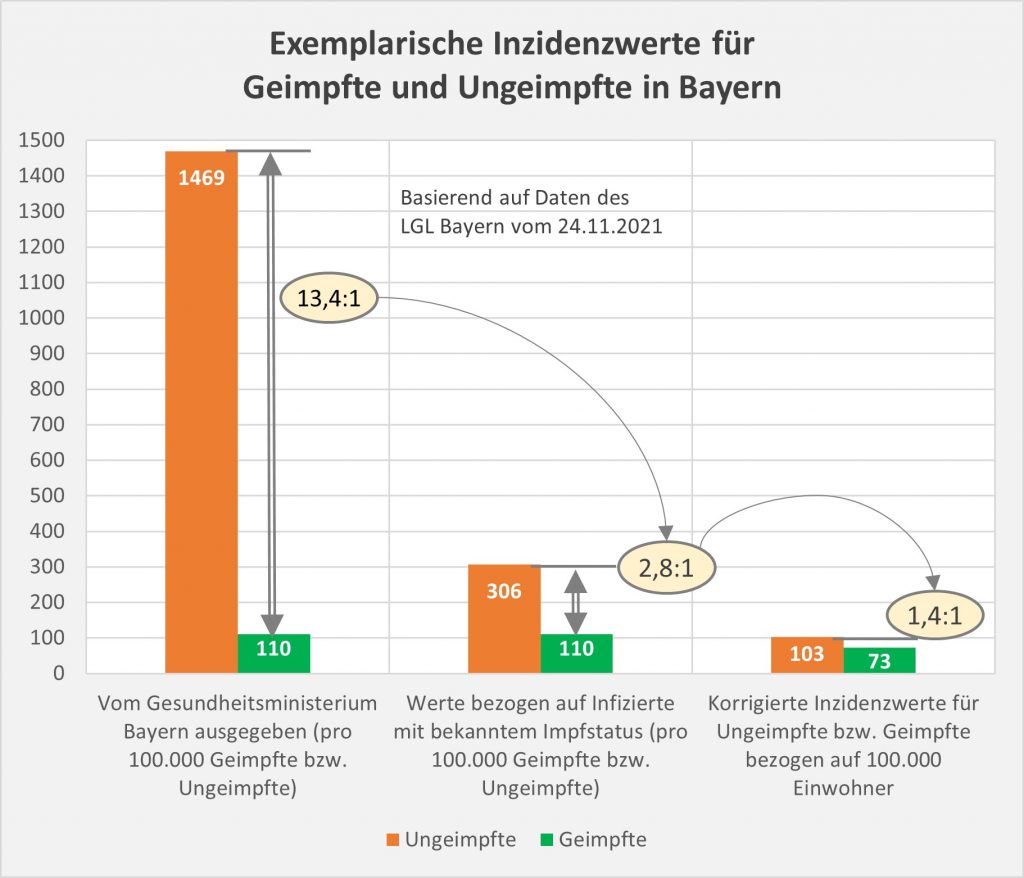
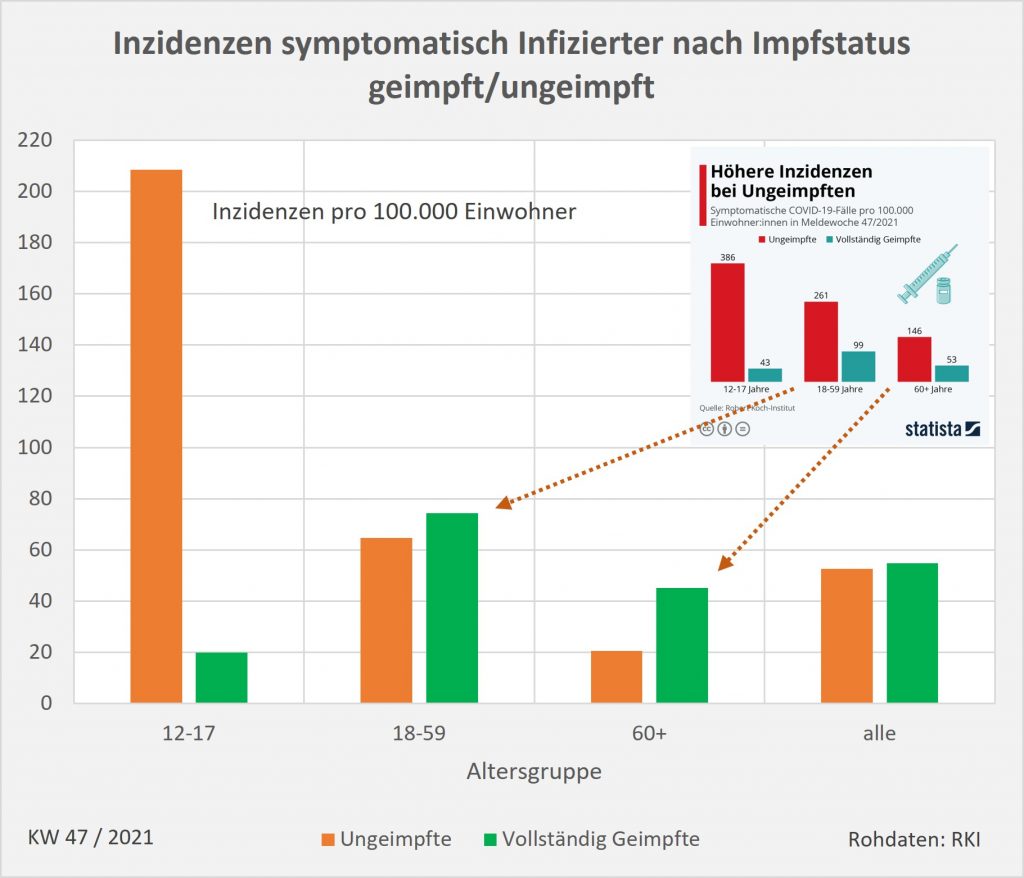
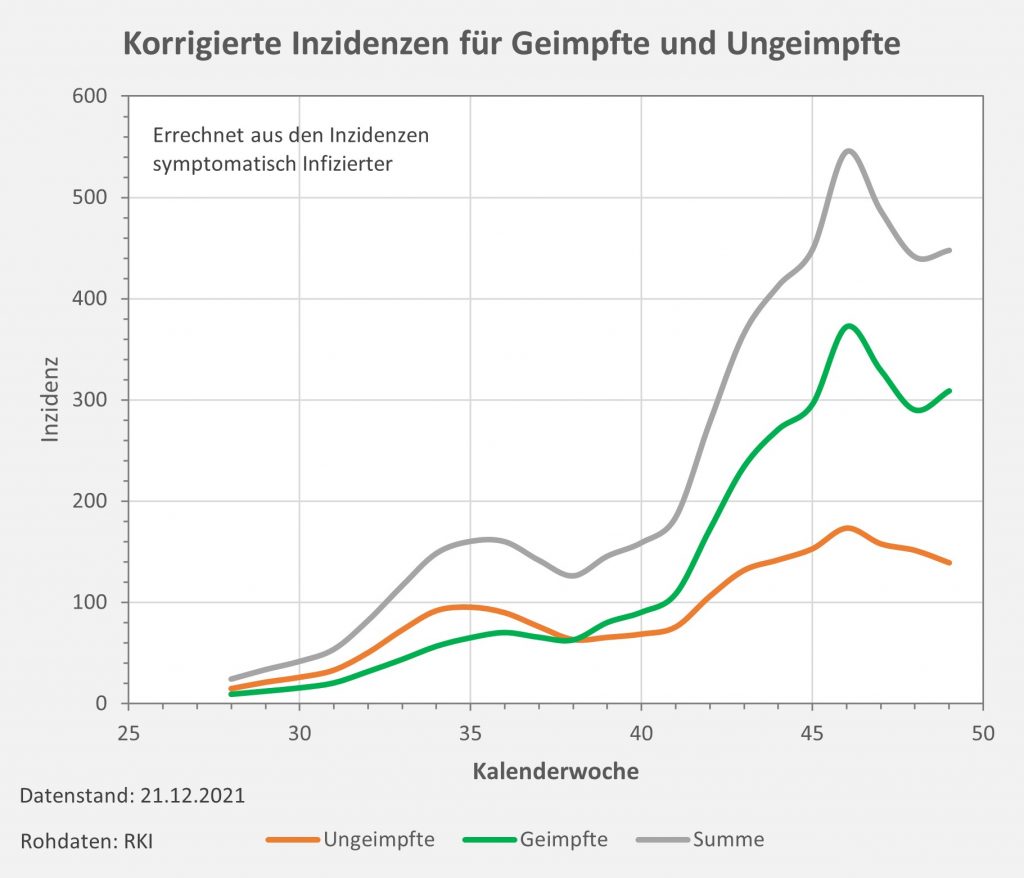
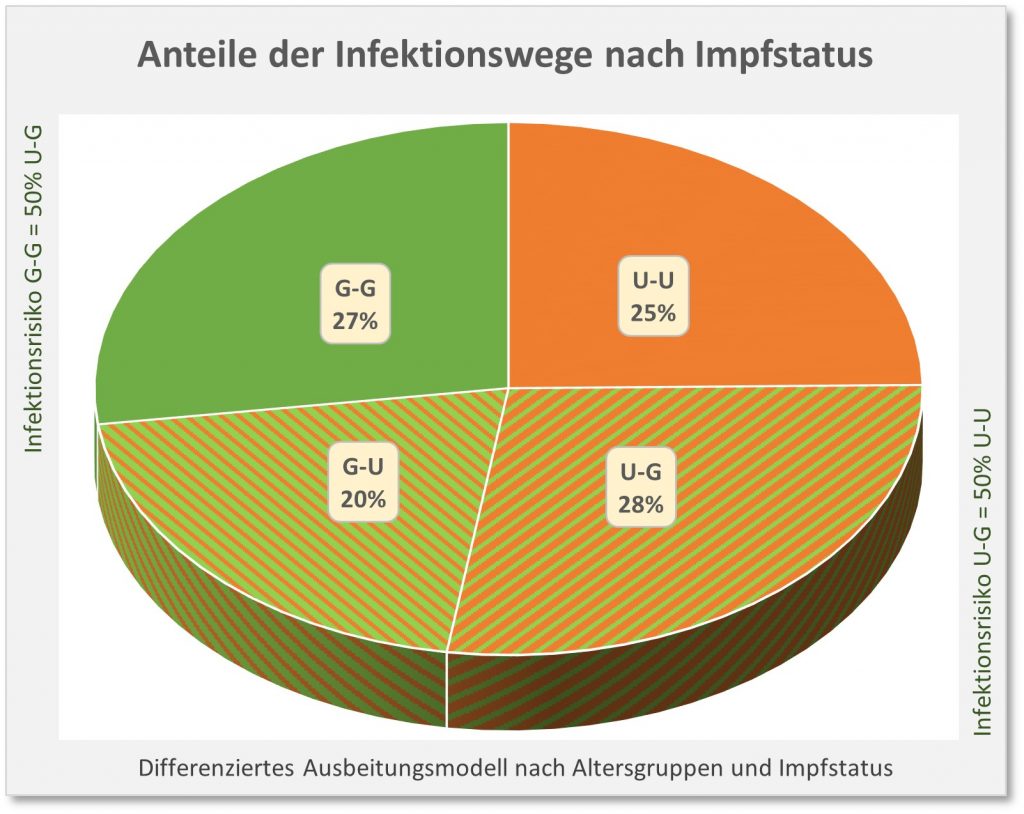
 = Größe der Population.
= Größe der Population. = Anzahl der Individuen in der Altersgruppe
= Anzahl der Individuen in der Altersgruppe  .
.
 = Anzahl infektiöser Ungeimpfter in der Altersgruppe
= Anzahl infektiöser Ungeimpfter in der Altersgruppe  .
. = Anzahl infektiöser Geimpfter in der Altersgruppe
= Anzahl infektiöser Geimpfter in der Altersgruppe  = Anzahl infizierter Ungeimpfter in der Altersgruppe
= Anzahl infizierter Ungeimpfter in der Altersgruppe  = Anzahl infizierter Geimpfter in der Altersgruppe
= Anzahl infizierter Geimpfter in der Altersgruppe  = Summe der infizierten Ungeimpften in der Altersgruppe
= Summe der infizierten Ungeimpften in der Altersgruppe  = Summe der infizierten Geimpften in der Altersgruppe
= Summe der infizierten Geimpften in der Altersgruppe 

 = Impfquote in der Altersgruppe
= Impfquote in der Altersgruppe 

 die Transformationsmatrix zur Berücksichtigung der Anzahl der bereits Infizierten:
die Transformationsmatrix zur Berücksichtigung der Anzahl der bereits Infizierten:
 :
: 
 Reproduktionsmatrix
Reproduktionsmatrix  eingesetzt, wobei:
eingesetzt, wobei:
 folgendermaßen definiert:
folgendermaßen definiert:
 für den Reproduktionsfaktor von infektiösen Ungeimpften der Altersgruppe
für den Reproduktionsfaktor von infektiösen Ungeimpften der Altersgruppe  . Analog steht
. Analog steht  für den Reproduktionsfaktor von infektiösen Geimpften der Altersgruppe
für den Reproduktionsfaktor von infektiösen Geimpften der Altersgruppe  für den Reproduktionsfaktor von infektiösen Ungeimpften der Altersgruppe
für den Reproduktionsfaktor von infektiösen Ungeimpften der Altersgruppe  für den Reproduktionsfaktor von infektiösen Geimpften der Altersgruppe
für den Reproduktionsfaktor von infektiösen Geimpften der Altersgruppe  in der Periode
in der Periode  und Ziel
und Ziel  wird wie folgt bestimmt:
wird wie folgt bestimmt:
 ,
, 





 die folgenden 4 Summen zur Gesamtanzahl der Infektionen in Bezug auf die entsprechenden Übertragungswege:
die folgenden 4 Summen zur Gesamtanzahl der Infektionen in Bezug auf die entsprechenden Übertragungswege: 
 ): 12-17, 18-59 und 60+ und ferner die folgenden Annahmen getroffen:
): 12-17, 18-59 und 60+ und ferner die folgenden Annahmen getroffen: 

 ist
ist
 = Anzahl der Fälle unter den Geimpften
= Anzahl der Fälle unter den Geimpften = Anzahl der Fälle unter den Ungeimpften
= Anzahl der Fälle unter den Ungeimpften
 als Gesamtanzahl der Inzidenzen sowie mit
als Gesamtanzahl der Inzidenzen sowie mit  als Anteil der Geimpften und
als Anteil der Geimpften und  als Anteil der Ungeimpften folgt
als Anteil der Ungeimpften folgt
 berücksichtigen, erhalten wir schließlich die einfache symmetrische Formel
berücksichtigen, erhalten wir schließlich die einfache symmetrische Formel
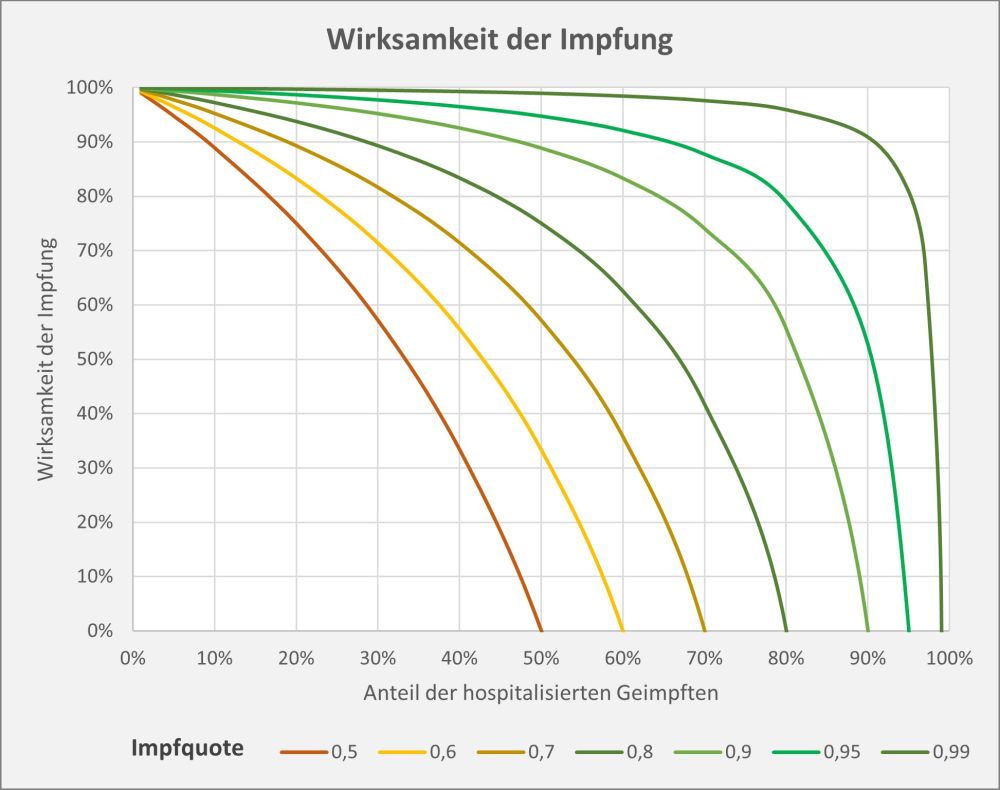
 bleibt, liegt die Wirksamkeit noch über 90 %. Bei einer Impfquote von 70 % wird diese Grenze ab einem Geimpften-Hospitalisierungsanteil von knapp 19 % unterschritten. Eine höhere Impfquote von 90 % führt dagegen noch bei einem Hospitalisierungsanteil von Geimpften in Höhe von 47 % zu einer Wirksamkeit von über 90 %. Bei 95 % Impfquote wird die entsprechende Hospitalisierungsgrenze auf etwa 65 % hinausgeschoben.
bleibt, liegt die Wirksamkeit noch über 90 %. Bei einer Impfquote von 70 % wird diese Grenze ab einem Geimpften-Hospitalisierungsanteil von knapp 19 % unterschritten. Eine höhere Impfquote von 90 % führt dagegen noch bei einem Hospitalisierungsanteil von Geimpften in Höhe von 47 % zu einer Wirksamkeit von über 90 %. Bei 95 % Impfquote wird die entsprechende Hospitalisierungsgrenze auf etwa 65 % hinausgeschoben. Prozent für einen Anstieg der Hospitalisierung um 10 Prozent (also z.B. um 10 % bei einer Impfquote von 50 % und um etwa 1 % bei einer Impfquote von 90 %).
Prozent für einen Anstieg der Hospitalisierung um 10 Prozent (also z.B. um 10 % bei einer Impfquote von 50 % und um etwa 1 % bei einer Impfquote von 90 %). , so dass z.B. bei einer Impfquote von
, so dass z.B. bei einer Impfquote von  die Wirksamkeit pro Erhöhung des Hospitalisierungsgrads um 1 Prozent um 4 % fällt; bei
die Wirksamkeit pro Erhöhung des Hospitalisierungsgrads um 1 Prozent um 4 % fällt; bei  gar um etwa 11 %.
gar um etwa 11 %.
 , wie nicht anders zu erwarten, der Anteil der Geimpften unter den Hospitalisierten stets gleich 0 ist. Wenn die Impfquote den Betrag
, wie nicht anders zu erwarten, der Anteil der Geimpften unter den Hospitalisierten stets gleich 0 ist. Wenn die Impfquote den Betrag  übersteigt, dann liegt der Geimpften-Anteil mindestens bei 50 %. Bei einer Wirksamkeit von 80 % ist das demnach schon bei einer Impfquote von 83 % der Fall. Sofern die Impfquote mindestens gleich der Impfstoff-Wirksamkeit ist, erreicht der Anteil der Geimpften unter den Hospitalisierten knapp 50 %. Das ist es, was wir derzeit angesichts einer Impfquote von 86,1 % in der Altersgruppe 60+ und einer Wirksamkeit in ähnlicher Höhe sehen.
übersteigt, dann liegt der Geimpften-Anteil mindestens bei 50 %. Bei einer Wirksamkeit von 80 % ist das demnach schon bei einer Impfquote von 83 % der Fall. Sofern die Impfquote mindestens gleich der Impfstoff-Wirksamkeit ist, erreicht der Anteil der Geimpften unter den Hospitalisierten knapp 50 %. Das ist es, was wir derzeit angesichts einer Impfquote von 86,1 % in der Altersgruppe 60+ und einer Wirksamkeit in ähnlicher Höhe sehen.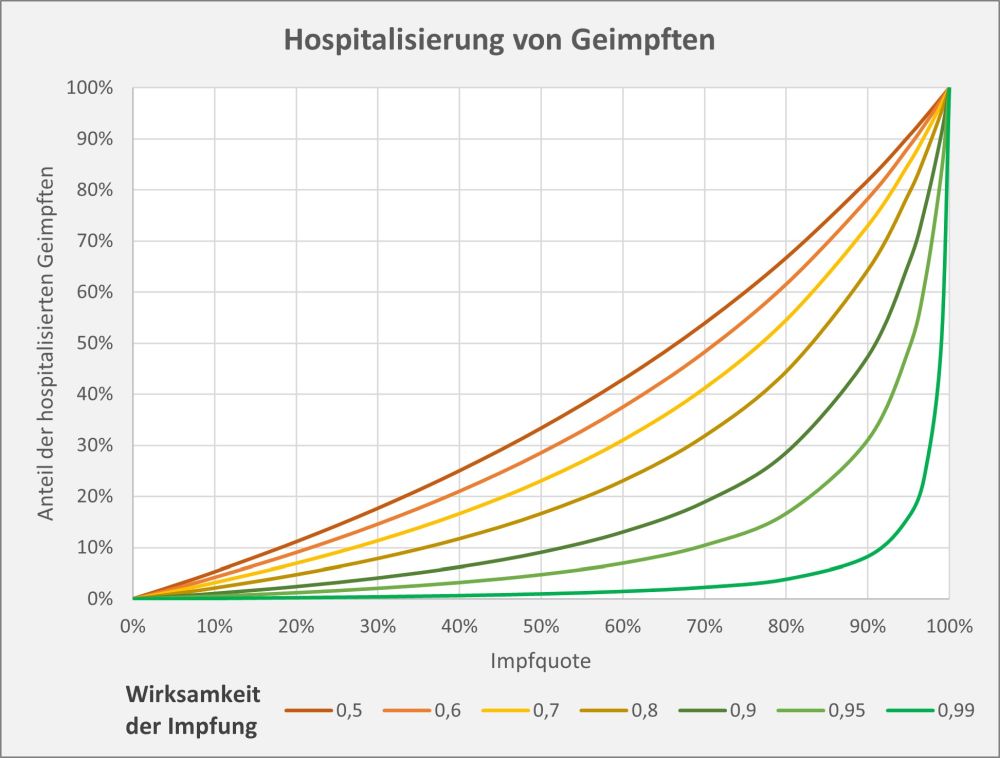
 (also z.B. um > 2,5 % bei einer Steigerung der Impfquote von 90 % auf 91 % und einer Wirksamkeit von 90 %).
(also z.B. um > 2,5 % bei einer Steigerung der Impfquote von 90 % auf 91 % und einer Wirksamkeit von 90 %). um
um  (also z.B. um 5 % bei einer Steigerung der Impfquote von 0 auf 10 % und einer Wirksamkeit von 50 %).
(also z.B. um 5 % bei einer Steigerung der Impfquote von 0 auf 10 % und einer Wirksamkeit von 50 %). Prozent für jedes weitere Prozent an höherer Impfquote (also z.B. um ca. 10 % bei einer Steigerung der Impfquote von 99 % auf 100 %) und einer Wirksamkeit von 90 %.
Prozent für jedes weitere Prozent an höherer Impfquote (also z.B. um ca. 10 % bei einer Steigerung der Impfquote von 99 % auf 100 %) und einer Wirksamkeit von 90 %. in der Wirksamkeit kann man die resultierende Veränderung der Hospitalisierung mittels des folgenden Differentials bestimmen.
in der Wirksamkeit kann man die resultierende Veränderung der Hospitalisierung mittels des folgenden Differentials bestimmen.

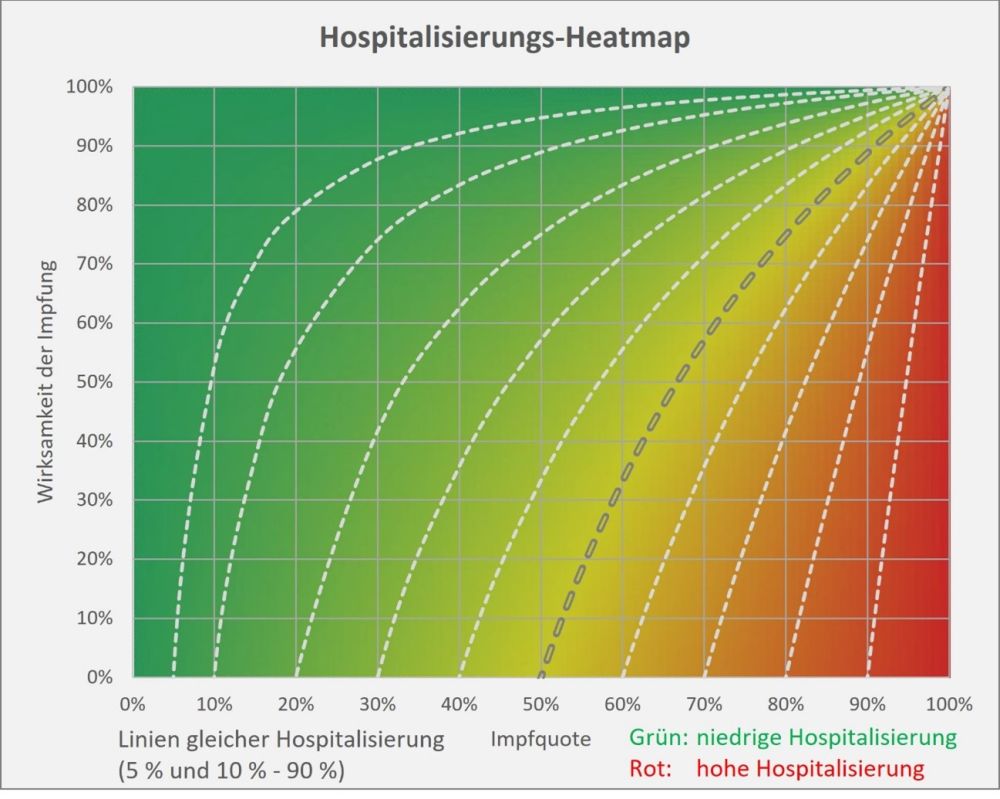
 , zugleich ist die Inzidenzquote der Geimpften unter den Hospitalisierten mit
, zugleich ist die Inzidenzquote der Geimpften unter den Hospitalisierten mit  angegeben. Daraus errechnen wir die resultierende Impf-Wirksamkeit zu
angegeben. Daraus errechnen wir die resultierende Impf-Wirksamkeit zu
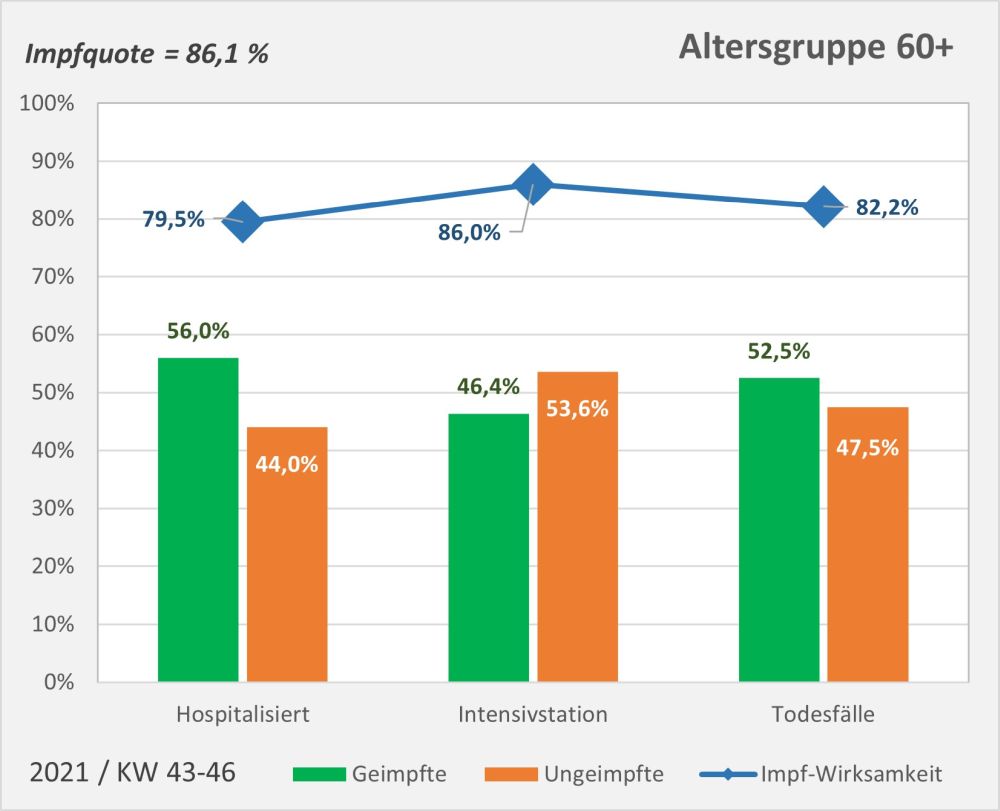
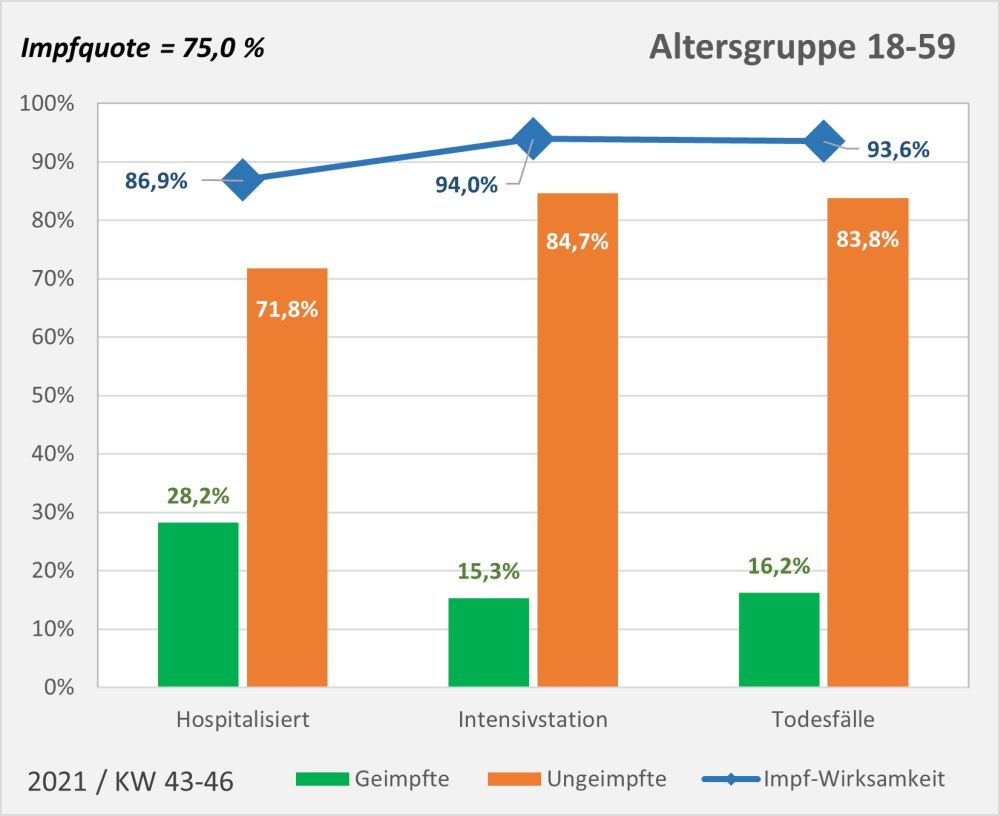
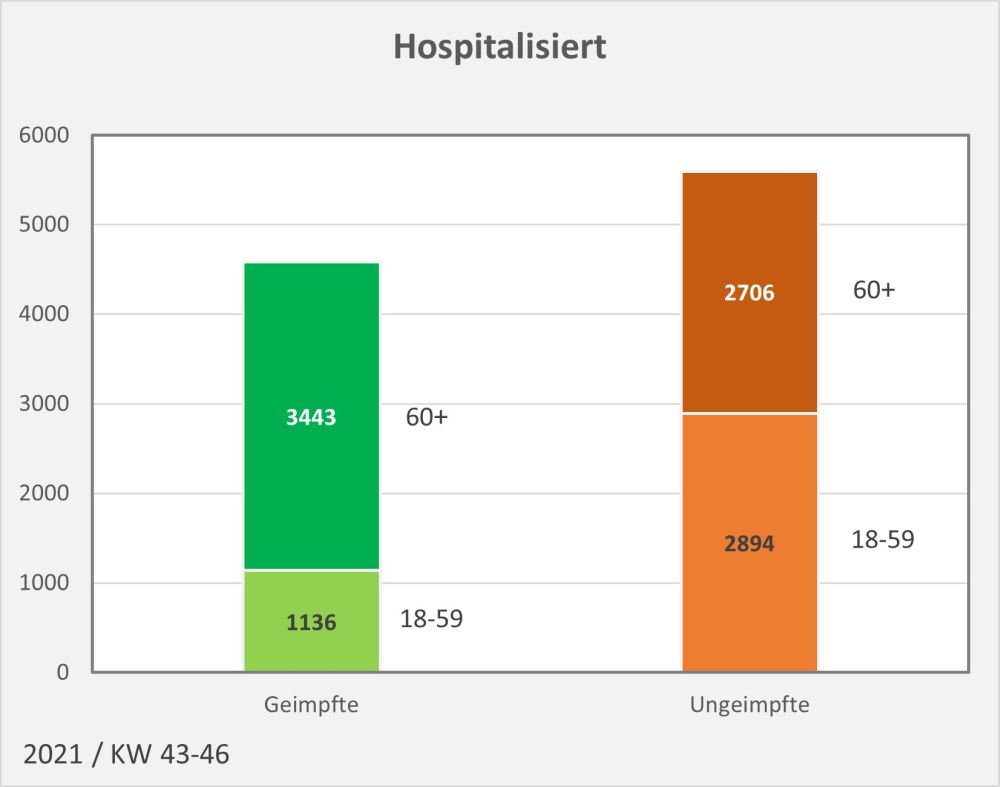
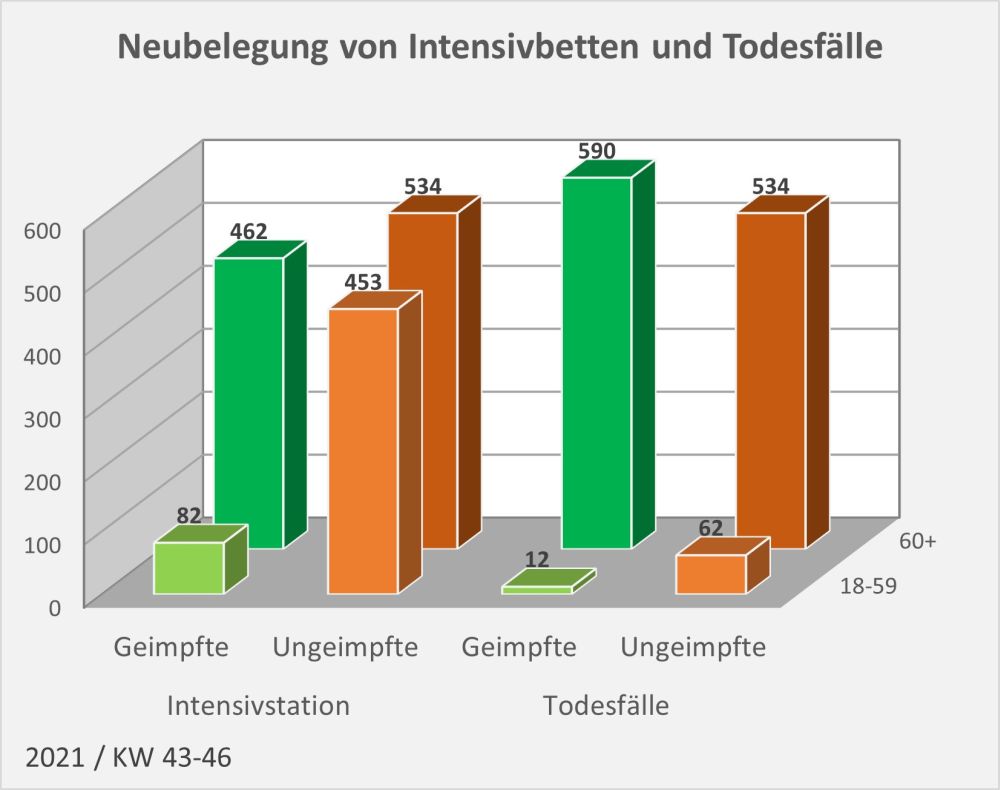
 sowie die Risikofaktoren für die Hospitalisierung
sowie die Risikofaktoren für die Hospitalisierung  bzw.
bzw.  . Ferner nennen wir die Anzahl der hospitalisierten Geimpften
. Ferner nennen wir die Anzahl der hospitalisierten Geimpften  und die der Ungeimpften
und die der Ungeimpften  .
.



 und
und  bzw.
bzw.  und
und  . Für die Fallzahlen der Geimpften und Ungeimpften schreiben wir
. Für die Fallzahlen der Geimpften und Ungeimpften schreiben wir  ,
,  ,
,  ,
,  ,
,  sowie
sowie  .
.