To anticipate the answer: The decisive advantage in functional safety results from the constructive cooperation of on-board systems and IT back ends.
Emission-free mobility and highly automated driving are the determinant future topics for automotive OEMs and suppliers. Embedded systems (ES) in the vehicle (on-board) together with high-performance back end IT systems (off-board) are the enablers in order to achieve these ambitious goals. The key lies in the intelligent connection of both worlds.
On the way to accomplish highly automated and autonomous driving functions, established OEMs, suppliers and engineering service providers are faced with the task of implementing innovative and highly complex customer functions economically. At the same time, the market is rapidly changing. New and unconventional acting market players such as Google, Apple, Tesla, Faraday, Uber, and others, are radically breaking new ground, both technologically and in terms of business models. This competition comes mainly from the IT world, not from the engineering world. These companies understand the vehicle mainly as a sort of „software on the road„.
The well-proven technology access, which has been tried and tested by premium OEMs and their suppliers, is based on a self-sufficient functional representation using on-board sensors and on-board embedded systems in the vehicle. Remember, a little bit more than 20 years ago, vehicles have been largely mechanical, mechatronic and electronic systems with a marginal share of software. Meanwhile, vehicle systems have been technologically expanded by more electronics and a rapidly growing share of software. This technological change has been extremely successful: many vehicle functions have been gradually realized completely as embedded systems with integrated software. Today, the functionalities at the cutting edge are complex driver assistance systems up to highly automated driving (level 3 automation / conditional automation). As mentioned before, all on-board and essentially without active communication with the outside world!
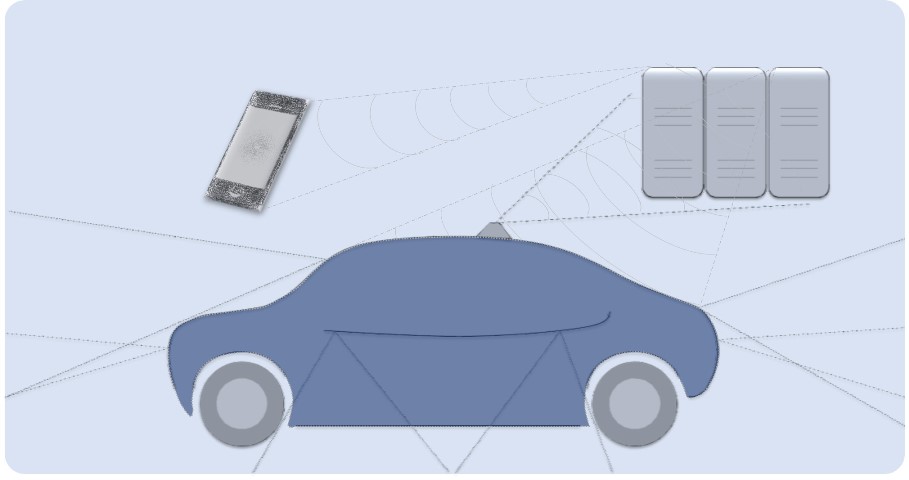
Even more challenging is the implementation of functions with the required higher levels of automation (Level 4 and higher / High and Full Automation or Autonomous Driving). Particularly, in the urban environment, e.g. safe passage of a multi-lane urban intersection, there are extremely difficult tasks that cannot be handled safely by state-of-the-art closed on-board solutions.
Provided, we must rely on the exclusive basis of a self-sufficient on-board system solution. Would we gain the confidence to entrust our preschool children (without accompanying adults) to an autonomous vehicle, which should they take to the grandparents living at the other end of the city? That’s hard to imagine!
To implement such highly complex and highly critical applications in a functionally reliable manner, new solutions are needed. One promising approach is to remove definite sub functions of the overall task from the vehicle and outsource them to an IT back end, or implement them at the IT back end, redundantly. This may comprise, for example, the computationally intensive parts of the representation and interpretation of the digital world view, the processing of large amounts of data, the determination of alternative courses of action in the driving strategy using AI methods (AI = Artificial Intelligence), the continuous expansion of the scenario knowledge base (Continuous Learning), the anticipation of the behavior of other road users, the analysis and verification of the ego vehicle’s driving trajectory in view of the traffic rules and quite simply the monitoring of the vehicle and the route from a distant location.
Certainly, it is no coincidence that the new market players mentioned above have recognized the benefits of IT solutions in automotive scenarios right from the start. They take advantage of the resulting flexibility in technical development and especially they apply IT proven procedures for the validation of driving functions. Also, they adopt the perspectives for potential disruptive changes in mobility concepts.
Enormous pressure on established OEMs, suppliers and engineering service providers results from this situation. Both technological approaches, the classical automotive one and the merely IT based one have their strengths and weaknesses. With respect to future mobility solutions, the benefits of the IT world (including the capability to process large amounts of data, rapid updates, usage of AI methods, deep learning) must be combined with the benefits of the ES world (including the close union of HW and SW, high efficiency, compact algorithms, real-time capability).
The decisive technological requirement arising from this is the connectivity capability of the different subsystems inside the car and the interconnection of the vehicle system with the overall network. The core requirement is the availability of highly secure and operationally reliable data connections with a high bandwidth. Provided this is ensured, functionally safe applications (Safety) distributed over a heterogeneous system environment of IT and ES systems can be established. At the same time, of course, the highest standards must be applied on data security (IT security). Finally, functional safety is ruled by the simple precept „without security, there is no safety„.
The technological cornerstones for maintaining the functional safety of IT back ends are:
-
- Function-dependent end-to-end latency < 20 ms … < 1sec
(transit time measured from on-board to IT back end, and backwards) - 24/7 availability and third-level technical support
- Protection of data integrity from cyber attacks
- Anonymization of the data
- Continuous updating of protective measures
- Scalability of services
- Function-dependent end-to-end latency < 20 ms … < 1sec
With the advent of the cellular standard 5G, the foundations have been laid for high-security data links with low latencies („signal propagation time„, delay between triggering and the effective execution of an action or response). The highly secure networking between the embedded systems in the vehicles on the one hand and the corresponding IT back ends on the other will thus provide a significant contribution to the further evolutionary steps in driver assistance towards reliable higher automation functions and autonomous driving.
Nevertheless, there can be no doubt that even with this holistic approach the way to the driverless car that rules the full variety of traffic scenarios („autonomous driving“ in the truest sense of the word) is still far away. There may be people who are saying, what’s the matter, that’s possible, Google has done it already. Others have also shown that cars can maneuver in real world traffic scenarios without driver intervention. Yes and no! Here we have to put into perspective, that all of these examples are far away from the required technological maturity and readiness for mass use under arbitrary real traffic conditions. – Let’s do the litmus test and remind ourselves again of the scenario mentioned above: Would we gain the confidence to entrust our preschool children to an autonomous vehicle (without accompany of adults) which should them take to the grandparents living at the other end of the city? – Provided, we can answer in the affirmative without hesitation we have reached the goal, not earlier.
In the medium to long term there will be an extensive technological convergence of the IT world and the ES world. We already see the beginnings of this process. For example, there are more dedicated AI chips used in both environments, ES and IT. Among other things this is the progression that is driving and pioneering convergence. This process has the power to bring together the still separate worlds of ES and IT. An additional transformation pressure comes from those highly complex new automation functions with multiple cross system dependencies. Paradoxically, precisely the use cases that are easy to describe (for example, the car should drive from address A to address B, completely independent from any driver interaction) call for a holistic view, thus driving the convergence process.
 und es gibt einen Konfigurationsparameter
und es gibt einen Konfigurationsparameter  . Der Algorithmus
. Der Algorithmus  bestimmt nach Maßgabe des Konfigurationsparameters
bestimmt nach Maßgabe des Konfigurationsparameters  , formal
, formal  . Bei einem lernenden Algorithmus ist das nicht anders, nur dass eben hier der Parameter
. Bei einem lernenden Algorithmus ist das nicht anders, nur dass eben hier der Parameter